 English | EN
English | EN 
Kubernetes at its core is a resources management and orchestration tool. It is jam-packed with rich features and goodies, but it can be a daunting task to understand the full spectrum of capabilities. As organizations adopt Kubernetes, it is critical to have a plan to ensure scalability and growth. Architects need to focus on questions like:
- What is my strategy to scale pods and applications?
- How can I keep containers running in a healthy state and running efficiently?
- With the on-going changes in my code and my users’ workloads, how can I keep up with such changes?
In this post we will discuss a high-level overview of different scalability mechanisms that are available for Kubernetes and the best ways to make them serve organization needs.
Kubernetes Autoscaling Building Blocks
Effective Kubernetes auto-scaling requires coordination between two layers of scalability.
- Pods layer auto-scalers, this includes
Horizontal Pod Auto-scaler (HPA) and Vertical Pod Auto-scaler (VPA). Both are available
resources for containers, - Cluster level scalability, which
managed by the Cluster auto-scaler (CA which scales up or down the number of
nodes inside your cluster.
Horizontal Pod Auto-Scaler (HPA)
As the name implies, HPA scales the number of pod replicas. Most DevOps use CPU and memory as the triggers to scale more pod replicas or less. Pods can be scaled based on custom metrics, multiple metrics, or even external metrics.
HPA workflow
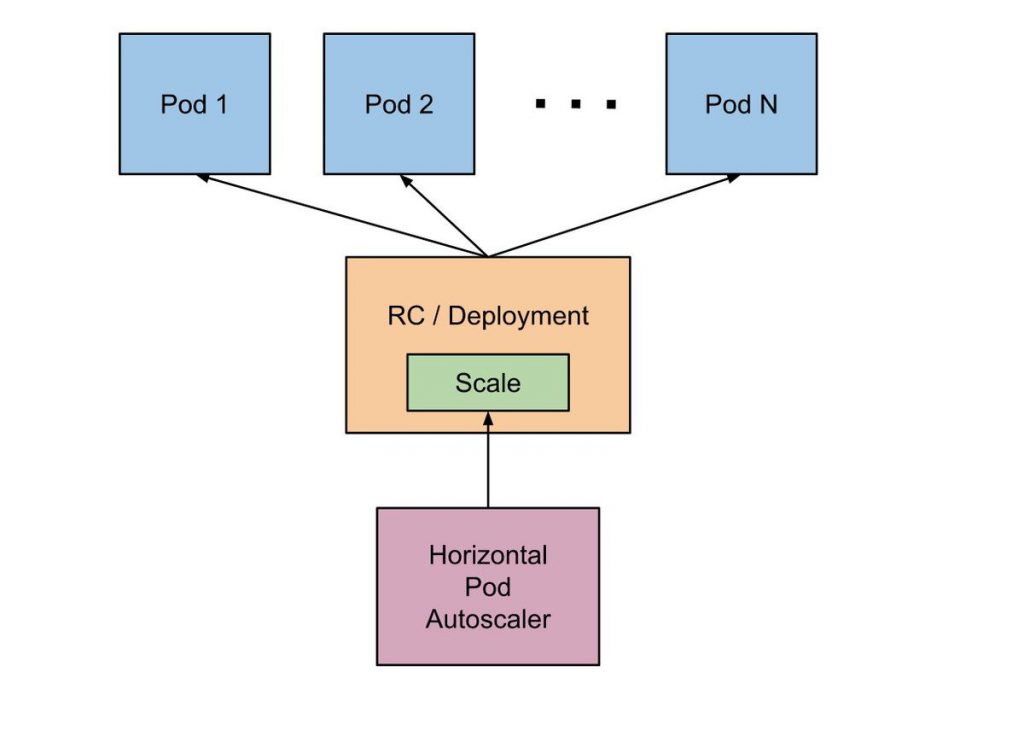
- HPA continuously checks metrics values you configure during setup using the default value of 30 SEC intervals
- HPA attempts to increase the number of pods if the specified threshold is met
- HPA mainly updates the number of replicas inside the deployment or replication controller
- The Deployment/Replication controller rolls out additional pods if needed
HPA Considerations:
- The default HPA check interval can be configured through the — horizontal-pod-autoscaler-sync-period flag of the controller manager
- Default HPA relative metrics tolerance is 10%
- HPA waits for 3 minutes after the last scale-up events to allow metrics to stabilize. This can also be configured through — horizontal-pod-autoscaler-upscale-delay flag
- HPA waits for 5 minutes from the last scale-down event to avoid autoscaler thrashing. Configurable through — horizontal-pod-autoscaler-downscale-delay flag
- HPA works best with deployment objects as opposed to replication controllers. It is important to note that HPA does not work with rolling updates.
Vertical Pods Auto-Scaler
Vertical Pods auto-scaler (VPA) allocates more (or less) CPU or memory to existing pods. VPA can be applied to both stateful and stateless pods although it is built primarily for stateful services. VPA can also react to out of memory events. When VPA restarts pods it respects pods distribution budget (PDB) to make sure there is always the minimum required number of pods and the min and max of resources can be set.
VPA workflow
- VPA continuously checks metrics values you configured during setup. The default value is 10 seconds.
- VPA attempts to change the allocated memory and/or CPU If the threshold is met
- VPA mainly updates the resources inside the deployment or replication controller specs
- When pods are restarted the new resources are applied to the created instances.
VPA Considerations:
- Pods must be restarted in order for the changes to take place.
- VPA and HPA are not yet compatible with each other and cannot work on the same pods. Their scope must be separated during setup if both are used inside the same cluster.
- VPA adjusts only the resources requests of containers based on past and current resource usage observed. It doesn’t set resources limits.
Cluster Auto-Scaler
Cluster auto-scaler (CA) scales your cluster nodes based on pending pods. It periodically checks whether there are any pending pods and increases the size of the cluster if more resources are needed and if the scaled-up cluster is still within the user-provided constraints. This feature was released as part of version 1.8 and is available for AKS/EKS/GKS.
CA workflow
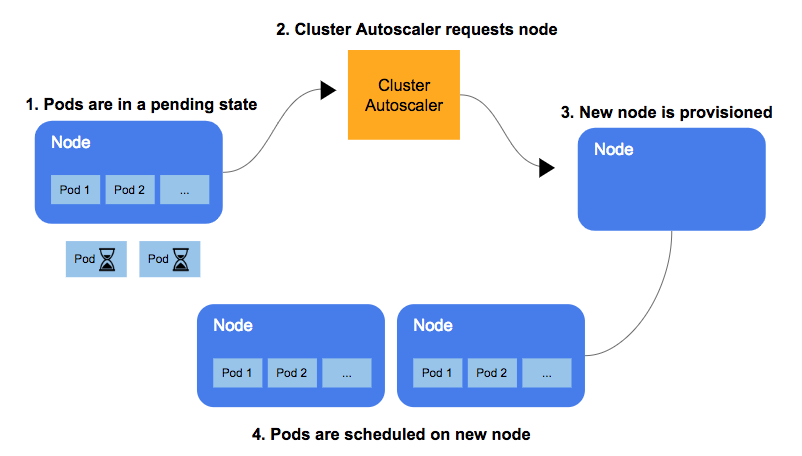
- The CA checks for pods in a pending state at a default interval of 10 seconds.
- If there are one or more pods in the pending state because there are not enough available resources on the cluster to allocate on the cluster them, it attempts to provide one or more additional nodes to compensate.
- When the node is granted by the cloud provider, the node is joined to the cluster and becomes ready to serve pods.
- Kubernetes scheduler allocates the pending pods to the new node. If some of the pods are still in a pending state, the process is repeated, and more nodes are added to the cluster as needed.
Cluster auto-scaler Considerations
- Cluster auto-scaler makes sure that all pods in the cluster have a place to run, no matter if there is any CPU load or not. Most importantly, it tries to ensure that there are no unneeded nodes in the cluster
- CA realizes a scalability need in about 30 seconds.
- CA waits for 10 mins by default after a node becomes unneeded before it scales it down.
- CA has the concept of expanders. Expanders provide different strategies for selecting the node group to which new nodes will be added.
Uniting All Auto-Scalers
In order to achieve the ultimate scalability, you will need to leverage pod layer auto-scalers with the CA. The way they work with each other is relatively simple as shown in the below diagram.

- HPA or VPA update pod replicas or resources allocated to an existing pod.
- If no enough nodes to run pods post scalability events, CA picks up the fact that some or all of the scaled pods in a pending state.
- CA allocates new nodes
- Pods are scheduled on the provisioned nodes.
Common Pitfalls
HPA and VPA depend on metrics and some historic data. If you don’t have enough resources allocated, your pods will be out of memory and they will be killed and never get a chance to generate metrics. In this case, there will be no scaling.
Scaling up is mostly a time-sensitive operation. You want your pods and cluster to scale fairly quickly before your users experience any disruption or crash in your application. You should consider the average time it can take your pods and cluster to scale up.