 English | EN
English | EN MLOPS: CI/CD PHASE
May 22, 2023

This is where ML meets DevOps

We recently published four blogs of a six-part series about the importance and necessity of having a solid MLOps implementation, Problem Formulation, DataOps, and Modeling. In this fifth blog post, we aim to elaborate on a phase where DevOps and ML come together: Continuous Integration (CI) and Continuous Deployment (CD).
In our last blog we went in-depth into the components of the modeling phase in the ML development cycle. In this blog we see the ML lifecycle management problem from the bigger perspective, illustrate the importance of CI/CD, and introduce the players involved in this part. We then discuss the main activities within CI/CD and expand on some design principles to keep in mind while setting up this part of the MLOps process. Finally, we consider the importance of this phase in a broader context.
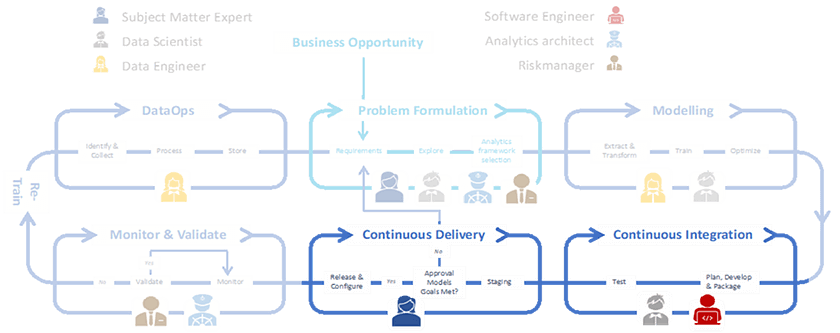
The why and the who of CI/CD
The purpose of MLOps is ensuring proper lifecycle management of Machine Learning model development with an end goal of scalability. As illustrated in the previous four blog posts, lifecycle management of ML and that of traditional software has some fundamental differences. The fact that we run through the ML lifecycle with people from different disciplines offers a consecutive challenge. Data engineers, domain/business experts, data scientists, IT teams: no two of them use the exact same tools or have the same skillsets. Therefore, it’s important to establish a toolset to enable the software engineers and the data scientists and engineers to work in an automated and streamlined way. CI/CD does just that, enabling the DevOps principles within MLOps, ensuring automated testing, deployment, and monitoring.
The people relevant to this process, next to data scientists, are software engineers and analytics architects. The software engineer takes care of placing the ML model in the organization’s application landscape. Starting from the model development phase, they closely collaborate with the data scientist to ensure that the model smoothly integrates with the application CI/CD pipelines, that the code is healthy and the serving efficient. To create meaningful monitoring dashboards and for efficient analysis of the model performance, input data, and other logged meta-data, Analytics Architect can advise the team.
The activities within CI/CD
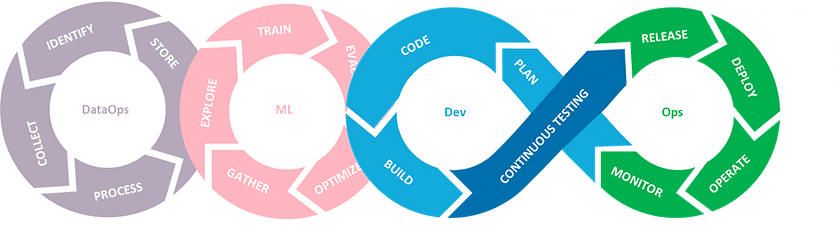
Since CI/CD enables the DevOps principles within MLOps, the activities in this phase of MLOps are in line with the pillars of DevOps — continuous testing, continuous integration, continuous deployment, and continuous improvement, with a nuance of continuous verification of data and models in each:
- Continuous Integration (CI): apart from testing and validating model code components, CI is about testing and validating data correctness, skewness, data schemas, and calculated feature values. CI enables the team to deliver new application features to their customers faster and more frequently.
- Continuous Deployment (CD): is not about deploying software as a service or a package, but deploying a ML system, consisting of data pre-processing steps. So, for automating continuous deployment, the service must be able to automatically build, test, prepare, and deploy new ML software on edge, or cloud. It should also provide flexibility to rollback to a previous version in case of poor model performance or unexpected behavior.
- Continuous Testing (CT): since ML development is an experimental process, it is important to save time and automate the retraining and testing of models, to ensure frequent deployments. With frequent automated testing, teams can discover bugs at an early stage before the code grows more complex.
- Continuous Monitoring (CM): Monitoring of model performance as well as checking the input data continuously, is a crucial step in model maintenance stage. If left unobserved, the data can shift, model can get skewed, and performance of the model can drop. It is thus important to log the meta-data and model performance to do statistical analysis of model performance over time. This pillar makes up a phase of MLOps — Monitoring, which will be the subject of our final blog post.
Enterprise solutions to enable these activities are already available on Azure, AWS and GCP. For open-source tools, read on in the following text where we dive into these activities in more detail.
Continuous Integration
Before deploying ML to production, it is important to make sure that the code passes all comprehensive unit tests and integration tests. This is done to have the metrics to track the quality of code being pushed into production. These tests are automated as a part of continuous integration (CI). Thorough testing of CI pipeline can be done by using a shadow environment, which is an environment aimed to provide same dependencies and data as in the production environment. Triggers are created as soon as new source code is generated, initiating CI pipeline to build the package with all relevant dependencies and test all the components of application’s functionality.
CI provides easily managed model versions, data versions, and promotes easy experimentation, hyper-parameter tuning, model retraining, model reproducibility and testing. Creating code which can be easily integrated into existing legacy code, also shares many similarities from DevOps architecture and practices. Just like any traditional software, good architectural design choices and coding standards can help in smooth integration. Software engineers often have deeper knowledge of how to create reusable, efficient, and scalable code. DevOps practices, like having documented rules from software architects for best-coding practices, documentation and use of dependent APIs, having code reviews before pushing new code in automated CI pipelines are few things one can incorporate for increasing efficiency of this phase.
To mask the complexity of managing and testing different model versions, MLFlow tool with tracking server can be used. It can be used to define the metrics and unit tests for the code being deployed or tested. It also provides logging options on localhost or server, which provides the developers flexibility to quickly test and compare the results of multiple models.
Continuous Deployment
Once the code is thoroughly tested, it is ready to be deployed to the target environment. Deployment types are dependent upon what kind of new code/service is being brought in the environment. In this stage compatibility of the code with all other modules must already work. If the new code change is a retrained model or some new assisting feature, then the most common deployment technique is canary deployment. In it, a small portion of the traffic is diverted towards the new algorithm being rolled out. Logs and dashboards are continuously monitored and if the statistics are as per requirements, greater chunk of traffic is shifted and so on. In such deployments, the negative impact of a poor performing ML model can be minimized. Another common type of deployment pattern is deploying multiple models in production and perform A/B testing. This helps analyze the behavior of different solution algorithms coded in the model under different scenarios and select the best performing model. If the model is retrained or replaced with a newer algorithm, blue green deployment techniques are often used. In it, the traffic is either routed to the old software version (blue version) or is routed towards new code version (green version). This distributes the traffic amongst old and new versions of the applications, and when the team feels the new code is stable, the entire traffic is rerouted towards the new green software version.
The blue green deployment is a type of progressive deployment where the main aim is to gradually roll out the changes, while having the live application as a secure backup. In progressive deployments multiple versions of software services are deployed like A/B testing, and the traffic is gradually shifted by servers or load balancers. These steps ensure there is zero downtime in critical applications serving live traffic, and that the rollback is easy providing high reliability.
To manage these different deployments and track them, containers offer an easy solution. Containers like Docker wrap the model code and all the dependencies in a package which is then ready to be deployed on the server. They use REST APIs to provide reusable or dedicated model servers. According to the project and cost requirements containers offer a variety of functionalities, scalability being one of them. Using containers, developers can easily monitor the resources required by the application and scale vertically or horizontally whenever required.
Continuous Testing
Once the new software code is deployed in the production pipeline, automated data and model analysis and tests should be performed. In this step, extensive tests must be done to check if the model performance is same as expected under different scenarios specially the edge cases. It involves testing of code and its integration as software with other dependent applications. It is a framework which ensures that with every new deployment, there is no added risk into the system. We discussed the types of tests which can be used to validate models and data in the ML pipelines, like unit tests, robustness tests, acceptance tests in our previous blog. The essence of doing continuous testing is to promote and support experimentation of ML algorithms. With automated continuous testing and deployments, data scientists have the flexibility to test several hypotheses tailored to specific domain problems and provide innovative, efficient solutions.
Similar tools like MLFlow or setting up automated pipelines like Tensorflow Extended (TFE), Kubeflow and Seldon Deploy can be used to easily deploy ML model and code modules. These self-contained pipelines hide the underlying complexity and wrap it into a function which can be used to define extensive tests for model code analysis.
Conclusion
Orchestrating a Machine Learning pipeline can be overwhelming because the design choices we make must ensure that the negative impact of the deployment process is none. In this blog we saw the important factors one must consider while developing a scalable, resilient, and robust ML pipeline in line with DevOps. These tips help the team to better manage the ML pipelines, so that debugging, tracking, and testing can be done frequently leading to the delivery of a quality service.
Once we have successfully deployed the ML service in the system, either on cloud or edge, we must continuously monitor the performance of the model and quality of incoming data. The tracking and logging techniques we discussed can be used to provide valuable insights for model advancement and data evolution. Therefore, monitoring services work hand in hand with CI/CD services to ensure that the model performance does not drop. The next blog post elaborates this ‘Monitoring’ stage in the ML pipeline and how it can be used with CI/CD modules to create an end-to-end reliable service.
Jump to part 1 of our MLOps series: MLOps: For those who are serious about AI
Jump to part 2 of our MLOps series: MLOps: the Importance of Problem Formulation
Jump to part 3 of our MLOps series: MLOps: DataOps phase
Jump to part 4 of our MLOps series: MLOps: Modeling phase
About the author