 English | EN
English | EN MLOPS: THE IMPORTANCE OF PROBLEM FORMULATION
May 1, 2023


We recently published a blog, the first of a six-part series, about the importance and necessity of having a solid MLOps implementation. There, we introduced the diagram seen in Figure 1. It is a simplified depiction of the framework used to operationalize Machine Learning models, and — just as important, though less evident — keep them operational. In this second blog post we aim to elaborate on the first step in the framework: Problem Formulation. We will formulate the problem in the literal sense. Furthermore, we will generalize by introducing the players involved in this first phase, as well as the other roles active in the whole MLOps process. Using this as a basis, we will address the requirements for the roles in the problem formulation phase.
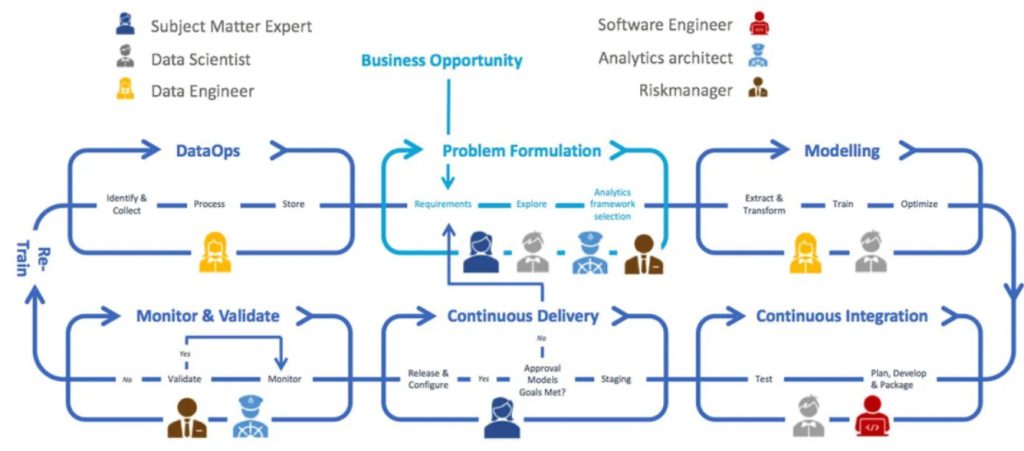
Who are the players and what do they need from MLOps?
As the above diagram shows, different roles collaborate in the MLOps process. Alongside data scientists — whose main responsibility is to develop the ML (Machine Learning) models — there are data engineers, software engineers, subject matter experts (SME’s), analytics architects, and risk managers. All of whom make the ML models worth the investment, and make sure it stays that way.
Data Scientist
Adopting the MLOps strategy has a significant impact on the work of data scientists — in a positive sense of course! The fact that they use different tools and work in isolated (data) environments causes difficulties for them to translate their ideas and initiatives into scalable solutions. MLOps address these difficulties for them and reward their efforts in the long run. To elaborate on the difficulties that we are talking about, consider the following example:
Pete is part of a small team of data scientists. The team has the assignment to develop a ML model and — in a later stage — put it into production. Initially, they only have access to a data dump that has been casually queried for them, since “we’ll work on that data pipeline at some point in the future”. In good spirits, the team starts with all the facets of the data science pipeline: data cleaning, feature engineering, exploration, modeling, model hyperparameter tuning, etc.[1] Soon, during standup, the product owner is delighted to hear about the progress that they have made; there’s even an actual first model! Though it should be mentioned that the model must be finetuned, as its performance is suboptimal, and the team has run into several oddities. During the same standup, it is put forward that a new query can be run to provide the team with up-to-date data that would contain recent developments of the company. Oh, and since they’re working on it anyway… could they train a similar model for their branch in France? “The business and data are almost the same, but not quite.”
Standup is over, nearly everyone is excited by the approval of their model; they will receive fresh data and there is no lack of ideas on how to improve the model. Only Pete walks away in quiet disappointment, as it is not the first time he has been through this. He knows what this entails, and what will likely happen. He knows that the workload will be distributed. Someone will work on data processing (of the new data), and new features will be created. Someone else will work on the model, and yet another will work in parallel on the model for France. Soon there will be confusion about functions and models that only work on one set of data, while other functions only apply to “the France model”. Distinct pipelines will intertwine, and it will seem as if all performance measurements are comparing apples to pears. Pete is worried and foresees chaos.
Pete is desperate for a MLOps framework that provides structure and enables version control. For example, the team would like to track when, how frequent, which model, and with which hyperparameters the model has run, and which version of the source code and data matches that combination. Furthermore, they would like to be able to push their models to production quickly and safely. This means that a pipeline is in place that packages their models, tests them, and provides them with an environment in the IT landscape that allows other applications to call on them.
Also, we should remember managing the model versions (France’s model, the model for product series X, the model that is only applicable for the data of the first half year, etc.). Finally, the team would like to be able to develop and run tests that determine the quality of the produced models. This needs to be monitored and should be accessible from a central location. When this is needed, they wish to have a mechanism or pipeline in place that can automatically adjust the model to improve the quality. Because the model is dependent on data that comes in by being trained in a certain way, they also want to be alerted whenever the data format changes, or the ‘content’ of the data slowly drifts.
Subject Matter Expert (SME)
Where most team members possess the technical skills to turn data into models, they often lack a deeper understanding of the business domain they operate in. For this reason, subject matter experts are needed in the team who provide the team with the proper context and data understanding. During the process, the SME will closely monitor whether the ML model’s outputs make sense and adjust the team’s course where needed. It is important for the SME to grasp the model evolution from a business perspective. Furthermore, the SME needs a way to provide feedback on the model. For example, if they notice that a model prediction is incorrect, they should have a mechanism at hand to provide the required information to improve performance. Since their role is especially important in the first phase (i.e., problem formulation), we will elaborate further on the subject matter expert after touching on the other roles.
Analytics Architect
The (data) analytics architect role requires additional skills when compared to that of the traditional data architect. Besides knowledge in the field of data storage and data pipelines, the analytics architect should know how ML models consume this data. They can select the right technologies from the wide range available on the modern market, varying from commercial to open source. This role comes with great responsibility, as the performance of models are highly dependent on the technologies that support them. Furthermore, the analytics architect evaluates non-functional attributes, such as security, utility, and stability. Thus, within MLOps, the analytics architect demands an overview of the models and their corresponding resources. Likewise, the pipeline should be flexible and accessible enough for them to make precise architectural adjustments whenever needed.
Risk Manager
The risk manager’s task is to assess — from beginning to end of the MLOps process — whether the ML model carries a risk for the organization from a regulatory or privacy aspect. A lot of manual labor in auditing can be spared when they have a clear overview of every version of model, data, and performance measurements.
Data Engineer
Every ML model is highly dependent on the data on which it is trained and tested. The data engineer is responsible for the creation of the data pipelines that provide this. At the beginning of a MLOps cycle, the data engineer collaborates with the SME in identifying the correct data (sources), such that the domain knowledge shapes the data preparation. In the phase of model realization, the data engineer and data scientist work together to construct even more specific data pipelines that measure up to the input needs of the models. An important requirement of the data engineer is that the MLOps framework should provide a detailed view on every individual step in the data pipeline.
Software Engineer
A machine learning model on its own doesn’t do well to serve an organization. The model should be validated as an asset to the business. The software engineer takes care of placing the ML model in the organization’s application landscape. Starting from the model development phase, they closely collaborate with the data scientist to ensure that the model smoothly integrates with the application CI/CD pipelines and thus is automatically deployed as soon as it is done.
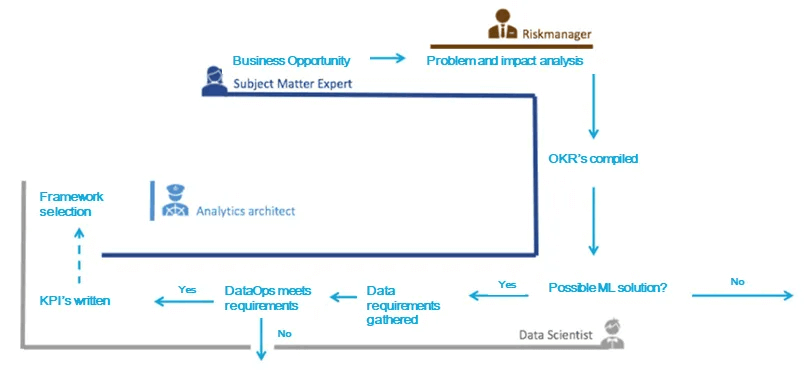
Business Opportunity
Now that we have met the main players of MLOps, let’s zoom in on the first phase: problem formulation. This is primarily a non-technical phase, where understanding the business is the first and highly decisive step in the process. As the diagram in Figure 2 shows, the MLOps process starts with “business opportunity”. Should there be either a business problem or an opportunity to improve, then — no matter the nature of the problem — it is imperative to identify and analyze it without immediately considering any solutions. The SME plays a key role here. Finally, it is important to establish clear communication between all the stakeholders. This way all relevant information and requirements for the next steps can be uncovered.
Requirements
The ‘problem formulation’ phase starts with an understanding of the requirements relevant to the business opportunity. The functional requirements of the players of MLOps have already been mentioned above and these must be considered as such in advance and can possibly be included in a checklist. The checklist can then be used to determine whether the next phase of MLOps can begin. However, the conditions that we specifically have in mind in this phase have to do with drawing up ‘Objective Key Results’ (OKRs) — this would encompass both business related as well as technical specifications. The more we pay attention to these requirements in this phase, the easier it will be to evaluate whether the model is successful or not.
Since not every problem can be solved with machine learning, this is the moment where a data scientist needs to be involved. It may not be obvious, but a data scientist’s role is not limited to the model development phase. They should be involved in formulating the business problem and they will discuss the OKR’s with a business expert to decide whether machine learning is the right tool for the job. Though it may take a significant amount of time, it is necessary! As it is the first decision in whether to kick off model development, or to pull the plug on the MLOps process entirely and start looking elsewhere. After this moment of go/no go, we have enough context based on the concrete problem and the quantified OKRs to know what data is needed. This information becomes part of the requirements list.
Again, this phase helps us to clarify the problem, what the solution should look like, and what the value is to the organization.
Explore
To clarify on this part, we assume for the sake of convenience that we have access to the required data and that the DataOps module of MLOps is in place as well. The main goal of this step is to answer the question of if the data is sufficient for the requirements. We do this by exploring the data, during which there should be open communication between the SME, business stakeholders, and the data scientist so that we discover and understand the relationships within the data. Here too, we can start brainstorming on the ML models only after the data has met the requirements. Furthermore, we can determine the more specific ML metrics and KPI’s to be used.
Analytical Framework Selection
Now that we have a clear view on the problem that we will solve and the part that machine learning will play therein, we can move on to selecting the right frameworks. This does not necessarily mean that every choice we make here is set in stone. However, some frameworks and libraries are better fit to specific use cases than others. For example, consider ML driven services such as image and speech recognition on mobile devices. If you want to apply your model in real-time, with limited connectivity, or where latency plays a role and you want to maintain security and privacy compliancy, you are better served to use a ML framework that is optimized for that exact goal (examples are Core ML, TensorFlow Lite, PyTorch Mobile, and Firebase ML Kit). Or suppose there is a demand for a bot that answers a user’s questions. In that case, you may choose to start from nothing, but you could also make use of cognitive services offered by certain cloud providers. Every one of them has its own pros and cons. The analytics architect plays a vital role during these selections, since they are always aware of the latest developments and can foresee what the long-term consequences could be with regards to scalability and performance of the solution.
Conclusion
To summarise, the first step in the MLOps process is a vital first step. Spending more time here with all the stakeholders mentioned above can save a lot of time and money and investments can be driven to the right projects and solutions. Setting up the problem formulation phase successfully paves the way for the next steps within the MLOps process. We will address many of the mentioned concepts in later blogposts. The next topic will be on ‘DataOps’ and how it fits within the MLOps process.
Posting on behalf of Sanne Bouwmann
Jump to part 1 of our MLOps series: MLOps: For those who are serious about AI
About the author