 English | EN
English | EN MLOPS: DATAOPS PHASE
May 8, 2023

Treat your data as an asset in an MLOps cycle

We recently published two blogs, the first and second of a six-part series, about the importance and necessity of having a solid MLOps implementation and the first step in organizing an MLOps project — Problem Formulation. In this third blog post we aim to elaborate on an important part of the framework: DataOps.
We illustrate the importance of DataOps with an example and introduce the players involved in this part. We then discuss the main activities within DataOps and expand on some design principles to keep in mind while setting up this part of the MLOps process. Finally, we consider the importance of DataOps in a broader context.
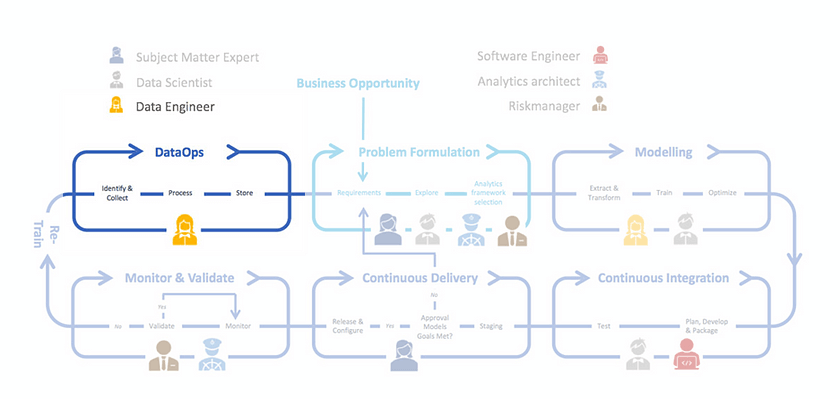
The why and the who of DataOps
It’s all about data! Treating data as an asset is imperative for a successful AI project. This is easier said than done as the data handling has a lot of moving parts. DataOps activities and principles aim to operationalize data handling.
Let’s investigate the why and the who of DataOps.
The why is illustrated with a personal example. Do you remember how shocked you were when you started working on your first real world use case? The difference between data in exercises and data in the real world is the plethora of issues real data can hold. These include missing values, outliers, features not recorded or recognized as important for the use case at hand and, of course, biased data. To mitigate these issues, data scientists are presented with an abundance of methods they can use for data preprocessing. However, the reality is that the mitigation of these issues starts with the understanding the data sources and selecting the adequate data collection method, where we ensure data collected is representative of the population. Correct data collection is tied to the use case and the model we are looking to use to solve a problem — this is covered in the Problem Formulation phase of the MLOps process. So, contrary to the popular approach of fitting the model to the data, we suggest starting with the data itself and treating its quality as priority. Once the data is collected, we can use data pre-processing methods on it, including feature engineering and feature selection. Sogeti’s Data Quality Wrapper (DQW) is a tool that educates on various open-source packages you can use to preprocess data. For transparency and insight into the preprocessing steps, data version control must be used. This ensures auditability and tracing every step in the data handling phase. Due to real world privacy regulations and the fact that data is often biased, this is a crucial part of the data handling pipeline.
We introduced the who of MLOps in our previous blog, so you know that different roles collaborate in this process. In DataOps, the most notable player is the Data Engineer, responsible for the creation of the data pipelines that provide data. At the beginning of a MLOps cycle, the data engineer collaborates with the SME in identifying the correct data (sources), such that the domain knowledge shapes the data preparation. In the phase of model realization, the data engineer and data scientist work together to construct even more specific data pipelines that measure up to the input needs of the models. An important requirement of the data engineer is that the MLOps framework should provide a detailed view on every individual step in the data pipeline.
These two players, together with data architect and data owners of the organization belong to the data governance working group. Besides them, the data governance review board is present with select organization members that are responsible to audit data and govern it.
The activities within DataOps
The activities within DataOps are outlined below.
- Identify and collect (Sandbox environment, explore the data sources and understand what the data is “trying to say”).
- Validate and process (Data cleaning according to business requirements, exploratory data analysis, preprocessing, feature engineering and selection).
- Store (Data is stored for use by other MLOps players, as illustrated below).
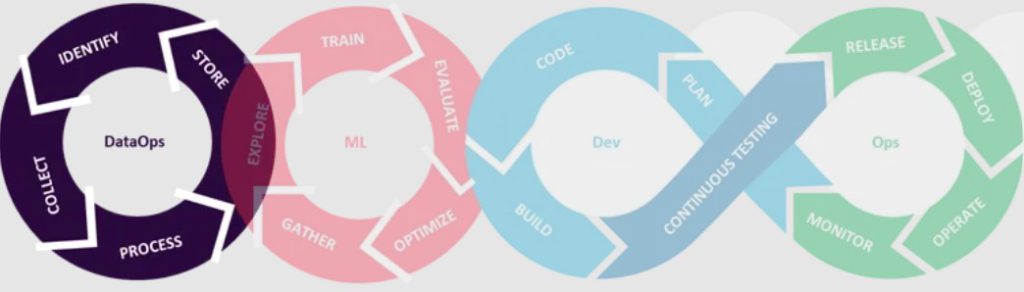
For technical implementation of these activities, enterprise cloud platforms have these functionalities built in and ready to use, you can check out Azure, AWS and GCP. For an overview of selected open-source and Sogeti-developed solutions, read on!
The design principles that govern DataOps
All the activities in the MLOps process related to DataOps need to have the following two design principles in mind that operationalize and orchestrate data handling:
Reproducibility
For a data scientist, experimenting with different data slices, parameters, pipelines, etc. is an integral part of the development cycle. When the experiment is finished, hopefully the resulting model’s performance is satisfactory. But wait! When we push our code, how do we guarantee that our colleague pulling the code to their own device will see the same results? This is where the reproducibility principle methods come into play. We could document the name of every data slice, every run parameter, and every model we used and shove those entities somewhere in a folder in our project. However, this has two downsides. First, it bloats our codebase with seemingly redundant files. Second, it makes for an awfully boring read.
Data version control allows us to commit versions of data, parameters, and models in the same way “traditional” version control tools such as git do. All that our colleague must do now is checkout the commit with DVC (or a comparable tool) and hit “run”. Meanwhile, on the repository side the accessed location of the data remains constant, even though the data itself may vary per commit. Thus, we have enabled easy reproducibility, while keeping our codebase nice and clean. This is but one of the many strengths of applying data version control to your ML project. In our next blog we will take a closer look at its merit in constructing a CI/CD-pipeline.
Transparency
Ensuring transparency in the data handling process is one of the crucial principles in DataOps. We stress the importance of this principle due to the need of auditing, privacy risk mitigation and fairness in data handling.
For privacy risk mitigation, DataOps focuses on assessing the data sources for personally identifiable information (PII) and considers using synthetic data to mitigate GDPR risk. We recommend checking out Sogeti’s Artificial Data Amplifier to find out more how Sogeti solves this with the use of synthetic data. Furthermore, the data sources need to be split in environments (non-production environments need to contain data representative of production data) and those environments must be protected by security protocols and governed. This is accomplished by authentication and role-based access.
Fairness in data handling is ensured by using bias mitigation methods to assess whether the training data is “judgement free”. We can mitigate this by re-weighting the features of the minority group, oversampling the minority group or under-sampling the majority group. Imputation methods can also be used to reconstruct missing data to ensure the dataset is representative. For more information on some techniques that can be used, refer to the DQW and Sogeti’s Quality AI Framework.
Auditing data is important for assessing the quality and veracity of the data within an MLOps project. It ensures that we are following the transparency principal. Audit trails include information on where the data is stored, how is it prepared for training, which tools and methods were used to prepare it and who is responsible for it. This is accomplished by monitoring and creating alerts that are triggered if any errors or deviations occur.
Consistency
Under the consistency principle, we focus on setting up tooling and documented specifications with information on where the data is located, what kind of source(s) it comes from, the preprocessing steps, the dataset schemas, the features used in training data, etc. These points all come together to form a data pipeline. Setting up a data pipeline to ensure complete consistency in the data handling process is at the core of DataOps. This principle ties together the reproducibility and fairness methods in an MLOps setting, creating tooling to enable and support it.
The components of data pipelines are:
- Extract from Data Sources. Data lakes for unstructured and semi-structured data, data tables for structured data, etc.
- Transform into features using preprocessing and feature engineering methods considering transparency and reproducibility principles.
- Load into feature stores to save commonly used features for model training.
For this, the TensorFlow Data API can be used to “build complex input pipelines from simple, reusable pieces; handle large amounts of data, read from different data formats, and perform complex transformations”. In other words, it applies the principle of separation of concerns to our DataOps solution: the data engineer processes the raw data, the transformed data is then exposed in a feature store, ready for the data scientist to cherry-pick and feed to the model. The data scientist no longer must concern themselves with “dirty” data and the data engineer doesn’t have to concern themselves with the data scientist’s “dirty” code. Win-win!
Treating data as an asset
Treating data as an asset and having a dedicated DataOps practice is beneficial not only for MLOps, but also for other areas of the business — financial, strategic etc. A dedicated DataOps practice enables an organization to have a clear of their data to fully utilize and leverage the insights obtained from it. Research done by Capgemini showed that companies that have a mature DataOps practice tend to outperform their competition by as much as 22% on profitability. They also show higher performance on metrics like customer engagement, operational efficiency etc. A strong DataOps foundation also needs a strong data driven culture within the organization. This is imperative for a successful and sustainable DataOps practice.
Conclusion
To summarize, the DataOps phase is vital for data-centric model development and a successful MLOps project. Understanding the data constraints and requirements stemming from the problem formulation phase sets the basis of cohesive data handling. This phase communicates with the Monitoring and Validation phase. We will address this and many of the mentioned concepts in later blogposts. The next topic will be on ‘Modelling’ and how it fits within the MLOps process.
Jump to part 1 of our MLOps series: MLOps: For those who are serious about AI
Jump to part 2 of our MLOps series: MLOps: the Importance of Problem Formulation
About the author