 English | EN
English | EN MLOPS: MODELING PHASE
May 15, 2023

Develop reliable and scalable ML models

We recently published three blogs belonging to a six-part series about the importance and necessity of having a solid MLOps implementation, the first step in organizing an MLOps project — Problem Formulation, and the second part in the MLOps cycle — DataOps. In this fourth blog post we aim to elaborate on a central part of the framework: Modeling. We illustrate the importance of modeling with an example and introduce the players involved in this part. We then discuss the main activities within it and expand on some design principles to keep in mind while setting up this part of the MLOps process.
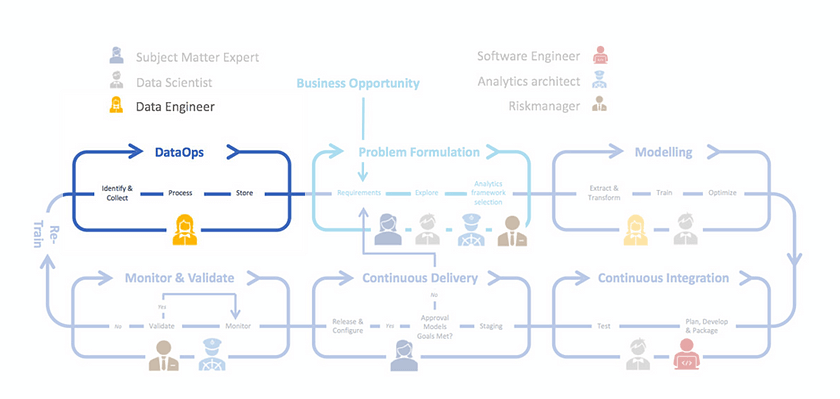
The why and the who of Modeling
Let’s illustrate the why of modeling with the help of our friend Pete (the data scientist introduced in the Problem Formulation blog post). To recap, Pete’s team was asked to create variations of an already developed model based on data from different financial departments and Pete foresaw chaos. Why is that? In his team, the modeling process was almost a standalone phase in the ML development lifecycle. The main activities in Pete’s team were centered around fitting the model to the data, in the so-called model-centric approach. This approach is defined by a focus on developing experiments that improve model performance, usually leaving the data in the background. During this, the data collection is centered around getting as much data as possible, the data quality methods are followed, but not elaborately (see the DataOps blog for an elaborate approach to data handling). This approach leads to underwhelming results in the real world, as data is ever changing and drifting. If it happens that a model developed this way ends up in production or needs to be adjusted to new data input, there is a high chance of it giving ill-fitted predictions. This is exactly what Pete was worried about and it illustrates the why of modeling in MLOps — the need in the industry for scalable, consistent, and transparent ML solutions that are data-centric in nature.
This brings us to the who of modeling. The main players here are Data Scientists and Data Engineers. Because of the data being put in the forefront of MLOps, the Data Engineer is included in the modeling process as well. In the phase of model realization, the data engineer and data scientist work together to construct specific data pipelines that measure up to the input and output needs of the models. An important requirement of the data engineer is that the MLOps framework provides a detailed view on every individual step in the data pipeline. The Data Scientist does what they are best at — finding the appropriate model, tuning it, and evaluating its performance. All the while, they ensure the reproducibility and scalability of the models by following the modeling activities and principles described below.
The activities within Modeling
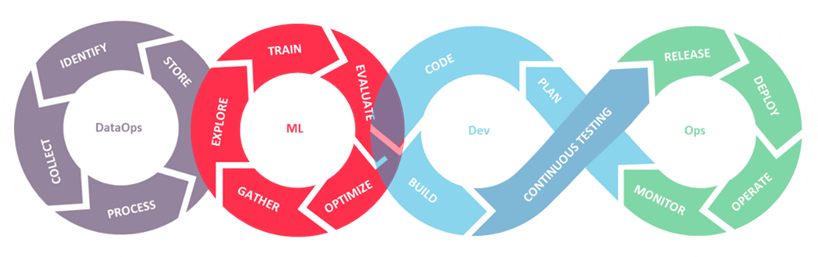
The activities in the modeling phase are described below:
- Explore the data and prepare it for model training.
- Train the model, saving model versions and training metadata.
- Evaluate the model performance by performing tests on the most granular level. An example would be calculating precision, recall and F1 score, AOC, etc. Additionally, feature importance and model robustness are assessed. We cover this and model bias mitigation in more detail in the transparency and consistency section.
- Optimize the model performance by tuning the hyperparameters and experimenting with the model’s constraints, all the while ensuring the versions of the model are saved for possible future use and evaluation.
- Gather insights and feed them to the DataOps phase for additional data engineering activities such as feature engineering and selection.
To support the communication of the modeling activities, enterprise solutions have been developed. For this, please refer to Azure, AWS and GCP resources. Read on for open-source solutions!
The activities in the modeling phase are governed by the following design principles: reproducibility, transparency, and consistency.
Reproducibility principle
The biggest concern with the old approach of Pete’s team was the lack of reproducibility of ML experiments. His team was asked to work on creating two more models with small variations on the original one, with new data and new assumptions. Pete foresaw chaos because there was no consistency or reproducibility in their old approach as everyone was busy experimenting on their own Jupyter Notebooks. He raised this concern to his team. Luckily, they saw validity in this and worked on deploying MLOps services to help them out.
Pete is not worried anymore — why? The new workflow looks like this: the data engineer prepares the data, ensures there are no quality and ethical issues, pushes the engineered features into feature stores or towards the data scientist. Then, the data is used for training — in this process, the data scientist can use platforms like MLflow or DVC combined with their Jupyter Notebooks or scripts for model versioning and training metadata storing. The saved models can be called for testing purposes, or to be used for new models (France’s model, the model for product series X, the model that is only applicable for the data of the first half year, etc.). This results in consistency, process clarity, and faster releases into production. It also promotes a more collaborative approach in MLOps as anyone in the team can contribute and run experiments on the same batch of data.
Another thing Pete’s team did is split repositories and pipelines into development, acceptance, and production. They utilize a version control system such as git to push a new version of the code to different environments. They added required reviewers in each step to ensure traceability and auditability. We will cover these points in more detail in our next blogpost where we dive deeper into CI/CD processes.
Transparency principle
Under the transparency principle, Pete needs to assess bias and ensure that model outputs are transparent and explainable. This is even more important when working for a financial institution, due to audit and governance. He must make sure the model is not treating end users unfairly but is also able to explain and justify its predictions.
A model is considered fair if it gives similar predictions to similar groups or individuals. Pete can tackle bias during modeling though four phases:
- Training data evaluation — use fairness metrics to assess bias in the data and model, resulting in the shortlisting of models which can be cross-validated to select the best performing and most fair one.
- Model training — use adversarial debiasing with generative adversarial networks (GANs) to maximize accuracy and a single relationship between protected features and the prediction.
- Post-processing — use reject option classification to make use of model prediction ambiguity to mitigate bias in target groups.
- Model evaluation — use the following metrics to assess the bias in model predictions:
- Statistical parity difference (difference in favorable outcomes in majority vs the minority group).
- Equal opportunity difference (difference in true positive rates in majority and minority group).
- Average odd difference (average difference between false positive and true positive rates in two groups).
- Disparate impact (ratio of rate of favorable outcomes in minority vs majority group).
Pete could use IBM’s Trusted AI python packages, which holds a plethora of methods to ensure trusted ML solutions on all bias mitigation stages. After using these tools, Pete can save all experiment results and can create fairness reports which he can then share with the stakeholders and auditors if necessary.
Pete should also use explainable AI (XAI) techniques like Lime and SHAP to understand model predictions. These two techniques aim to mimic model behavior at a global and/or local level to help explain how the model came to its decision. Pete can use this to lower the dimensionality of the training data i.e., by selecting only the most relevant and pertinent features and to explain how the model “thinks” to the users and stakeholders. He saves the results together with the hyperparameters in his MLFlow or DVC experiment. This is just as important as training metadata for reproducibility and transparency down the line.
Consistency principle
Under the consistency principle, we focus on setting up tooling and documentation with information related to the model, training metadata, logs, and the data pipeline itself. These points all come together to form a model pipeline. Setting up a pipeline to ensure complete consistency in the data handling process is at the core of Modeling. This principle ties together the reproducibility and fairness methods in an MLOps setting, creating tooling to enable and support it. Finally, this ensures model scalability and prevents data and concept drift in production.
The components of the model pipeline are (taken from MLOps principles):
- The data pipeline contents, described in our previous blog. Most notable are feature stores where training data is picked up.
- Model registry, where already trained ML models are stored after iterative model training, tuning and evaluation.
- ML metadata store contains tracking metadata of model training, such as model name, related data, and performance metrics.
- Deployment services such as Kubeflow, Seldon Core, and Tensorflow Serving. These services support scalable deployments of models into production.
- ML pipeline orchestrator. These pipelines/components communicate in an automated way, through triggers, CI, CD and CT builds. We will cover these concepts in our last two blogs.
This pipeline breaks the MLOps project into smaller pieces that can be scaled and replicated. It also enables Pete’s team to do extensive model tests within different MLOps phases, as described below.
Unit tests
Pete can test the functions he coded using the unittest python module. For example, he can automatically test functions by passing fixed variable values and cross-checking the result every time he adjusts them, ensuring consistency.
Model robustness tests (integration tests)
These tests are performed to evaluate model performance before the user testing starts. Pete would execute these tests after he is happy with the model performance on already seen data. Then he can use metamorphic and adversarial tests to assess model robustness. If these tests don’t hold — the model is not robust or able to give effective outcomes when tested on an independent dataset.
User acceptance tests
These tests are done by the SME to answer questions about the usability of the model:
- Is it difficult to get the model predictions and feed the model data?
- Is it difficult to understand why a model reached a prediction? XAI can be used here to explain model predictions, for example.
- Are there any lags in the model pipeline?
Additionally, application-specific metrics can be drawn to ensure the model will behave as expected in the target environment. These metrics should be defined according to business KPIs, and metrics defined in the Problem Formulation phase and are used to assess model adequacy in the given business context.
System tests in production
Enabled though monitoring of the model for data and concept drift. Data drift is the occurrence of data assumptions changing over time. This can be monitored through cross-checking data schemas of incoming data and data schemas saved in DataOps phase. Concept drift is the occurrence of the model input and output relationships changing over time. This can be tested though cross-checking the model performance metrics in production with the models saved in model registry. These checks can be automated and used as triggers for model retraining.
Conclusion
To summarize, the modeling phase is the core activity within the MLOps project. Understanding the data constraints and requirements stemming from the problem formulation phase sets the basis of cohesive data handling, thus, also ensuring the modeling phase starts efficiently. This phase closely communicates with CI/CD phase, as well as the monitoring phase. We will address this and many of the mentioned concepts in the following blogposts. The next topic will be on ‘CI/CD’ and how that fits within the MLOps process.
Jump to part 1 of our MLOps series: MLOps: For those who are serious about AI
Jump to part 2 of our MLOps series: MLOps: the Importance of Problem Formulation
Jump to part 3 of our MLOps series: MLOps: DataOps phase
About the author