 English | EN
English | EN 

We’ve all seen the famous What NOT to do example,with Amazon’s bias recruiting tool. A project started in 2014 that aimed to automate the hiring process by reviewing resumes with artificial intelligence (AI) algorithms — but resulted in unfair ratings and bias toward women. The problem was that Amazon had used 10 years of historical data that contained a clear bias against women, as the tech industry was largely dominated by men when the data was recorded. That meant that the system learnt that male applicants were preferable. The result? Beside the backlash and reputational damage — Amazon pulled the plug on the tool and dismantled the product team responsible for creating it.
This is not the only infamous example of AI gone wrong — let’s not forget the discriminatory Facebook algorithm, the racist criminal prediction software, and the very non inclusive social networking app, Giggle.
In the pre-AI world, us humans made those types of decisions in recruiting, advertising, prison sentencing, and profiling. Often these decisions are regulated by laws or organizational values. Today, we are asking machines to make those decisions for us — and that’s all good and well since machine learning (ML) has proven to outperform us in many tasks — but what happens when we use a dataset that contains biases, or when we identify correlations that reinforce existing societal standards that we are trying to change and rectify? Who do we hold responsible for the biased decisions that a computer made but we programmed?

Enter the moral and legal grey zone of AI…
50 Shades of Grey Areas
Let’s talk about the ill-defined space of bias and ethics in AI and how bias enters the algorithm in the first place.
Bias can stem from unrepresentative and/or incomplete data. This means that the data used to train the AI model is more representative of some groups as opposed to others — consequently the model’s predictions may be worse for the under-represented groups. Implicit human bias can also play a role. Often these biases are deeply embedded in us and can be reinforced and reproduced in computer programs and ML models without the programmer or data scientist’s knowledge.
But what about the rules and regulations?
In 2019 the European Union released their own “Ethics Guidelines for Trustworthy AI” which states that AI should be Transparent, Technically Robust, Accountable, Non-discriminatory, Protective of Privacy, Improve Societal Wellbeing and be subject to Human Oversight.As these principles are just a guide and there’s no legal standard or definition of ‘fairness’, these abstract and high-level guidelines don’t really mean much to a data scientist when he/she/they are trying to implement a high performing model that just meets business requirements. The difficult, yet most important task comes in trying to put ethical requirements into practice.

Well, It’s both — a practical introduction to detecting and mitigating bias.
Practice makes perfect
To combat ethical risk proactively without sacrificing model performance, we must first define ‘fairness’.
A model is considered ‘fair’ if it gives similar predictions to similar groups or individuals.
In more detail, a model is ‘fair’ if for both groups of the positive outcome, the predictor has equal true positive rates and equal false positive rates for the negative outcomes.
Next, we can break up our bias detection and mitigation techniques into phases — the same phases that govern the development of an AI model: Data understanding & preparation; model development & post-processing; and model evaluation & auditing.
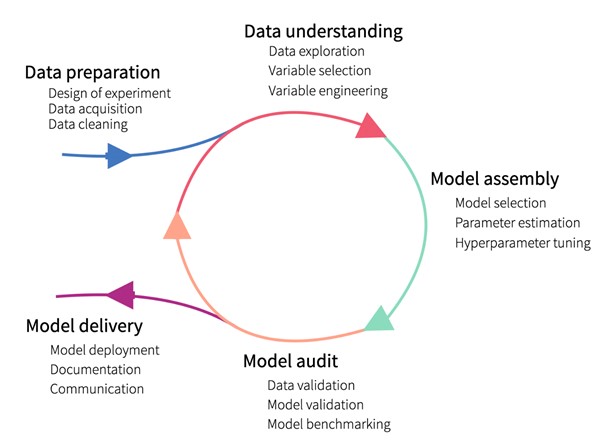
The AI development lifecycle
1. Data understanding & preparation
As the famous data science saying goes ‘Garbage in, garbage out’. Effective bias detection starts at the data collection and pre-processing phase. If the data does not reflect the actual distribution of data in real life, a trained ML model will enforce the bias. We can mitigate this by re-weighting the features of the minority group, oversampling the minority group or under-sampling the majority group. Imputation methods can also be used to reconstruct missing data to ensure the dataset is representative.
2. Model development
To combat bias during the training phase, a popular technique is to use adversarial debiasing with generative adversarial networks (GANs). In this approach, one network tries to predict a specified outcome from a set of features, while the second network tries to predict the protected attribute based on the outcome of the trained model. This technique maximizes accuracy while ensuring a one-way relationship between the protected attribute and prediction — meaning that the protected attribute cannot be deduced based on the prediction. This ensures equal outcomes for both groups.
3. Post-processing
We can use a deterministic algorithm like reject option classification in the post-processing phase. This can be used to swap outcomes between the favorable and unfavorable group near the decision boundary. A threshold can be specified to swap results so that if a favorable outcome was predicted and the individual is part of the favored group and within the threshold above the decision boundary; they are swapped with an individual from the underrepresented group. This technique aims to provide an equal set of predictions by boosting those of the minority group.
4. Model evaluation & auditing
Lastly, we need to evaluate the performance of the above techniques to understand if the model and outcomes are truly ‘fair.’ We can use specific metrics such as:
Statistical Parity Difference: The difference in the rate of favorable outcomes received by the minority group compared to the majority group.
Equal Opportunity Difference: The difference of true positive rates between minority and majority groups.
Average Odd Difference: The average difference of the false positive rate and true positive rate between minority and majority groups.
Disparate impact: The ratio of the rate of favorable outcomes for minority groups compared to majority groups.
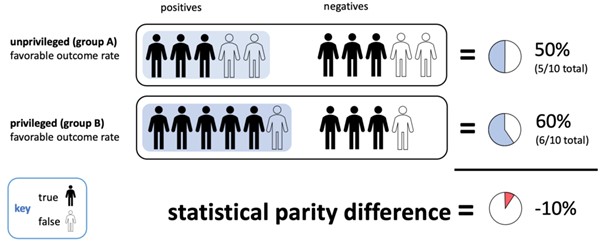
A visual representation of statistical parity difference: Using historic training data, a banking model predicts whether a person’s loan will be approved (a positive outcome) or denied (a negative outcome). Statistically, the model delivers a positive outcome for group B 60% of the time, and a positive outcome for group A 50% of the time . In this case, the statistical parity difference = -10% (50%-60%), suggesting that the model is unfairly biased against group A.
These metrics should be evaluated by the model stakeholders to determine if its results are fair and appropriate for production usage.
IBM Research has thankfully come up with a solution to combat our ethical AI dilemmas with their open-source AI Fairness 360 Toolkit (AIF360) — a very handy python package that includes functions with the aforementioned techniques, as well as many more based on the model use case.
Let’s wrap this up
The first step in implementing any bias mitigation technique is to understand the causes of bias in AI models, as well as having a full understanding of the context and the applications of the use case. With this understanding we can choose the best approach for rectifying the misrepresentations in our data and/or predictions. With the above methods in mind, we are on track for creating ethical, trustworthy, and inclusive AI.
At Sogeti we’re all about staying woke and keeping up with the latest ethics mitigation techniques so we can deliver trustworthy and quality solutions to our clients. That is why we have developed the Quality AI Framework (QAIF).
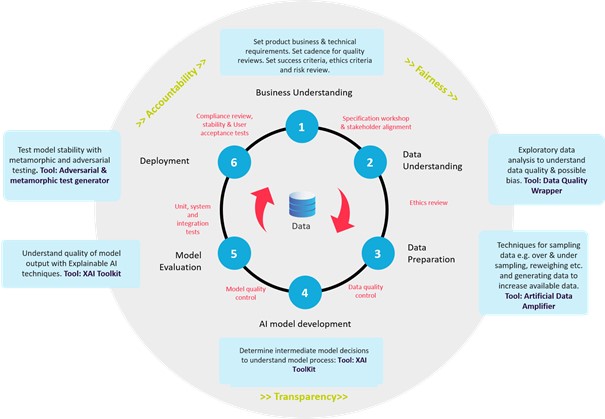
Sogeti Quality AI Framework (QAIF)
The QAIF is a practical framework with advanced tools and techniques based on statistics and ML that guides the AI product lifecycle, ensuring quality control and a high-performing solution. The QAIF not only evaluates and addresses data quality & bias, but model quality and validation too, It addresses several use cases for structured & unstructured data. The framework is based on the principles of Accountability, Fairness and Transparency — the trifecta of Trust. After all, if we don’t trust our AI, why would we implement it?
Get in touch with Sogeti for more information on our QAIF or other quality AI solutions.
This blog has been written by Almira Pillay.

Almira Pillay | Senior Data Scientist
Almira is part of the AI CoE team. She is an expert in Quality AI and currently leads the QA, Ethics & Sustainable AI initiatives within the team. Almira has a multidisciplinary background ranging from finance, biotech and software development.