 English | EN
English | EN 
In my last post titled: “How to evaluate your classification model correctly”, I explained in detail the metrics that you need to use for a good evaluation model when you are using a very unbalanced dataset. Today I will explain in-depth regarding this, in order to provide you some other tools to be successful with.
In this case, you can use three different techniques: undersampling, oversampling and synthetic data.
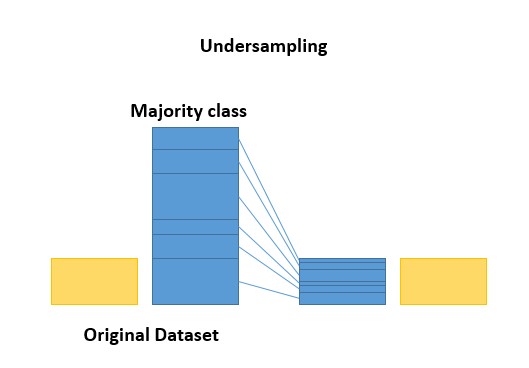
Undersampling as the name indicates you will use only one part of the dominant class trying to balance both.
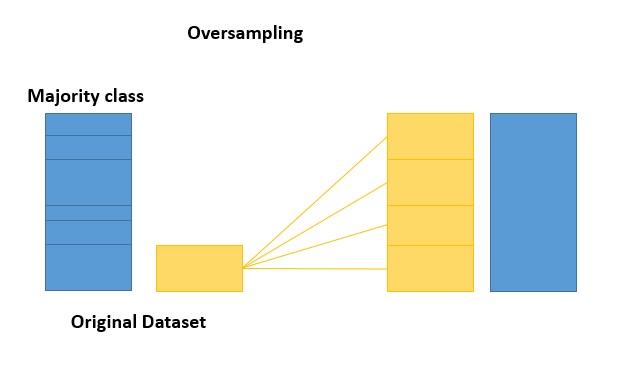
Oversampling means, replicate the minor class for a better balance between both.
And finally, synthetic data means to create dummy data from the minor class, maintaining the correlation between features and also the distribution of it. There is one another technique called SMOTE, nevertheless I will talk about Artificial Data Amplifier (ADA).

ADA is a new tool developed by the Sogeti Testing AI Team, and during the last month our colleague and member of the SogetiLabs ML Circle, Deepa Mamtani presented to us the tool. She used different examples for creating new synthetic data from datasets. I was really impressed when she started working with images dataset from teeth radiography and the process provided us new datasets with the same structure and quality than the original, seems awesome!
That means, this new tool provides you a lot of benefits not only for helping you to handle imbalanced data, also bring you the possibility to be compliant with GDPR, because you are working with no real data. Another benefit is that you are able to amplify a very small dataset, because sometimes it is quite complicated or costly to obtain. And last but not least, you can use it to increase the accuracy of your ML models due to the new huge quantity of data.
For all of that, I really suggest you go ahead and schedule a demo session!