 English | EN
English | EN HOW TO EVALUATE YOUR CLASSIFICATION MODEL CORRECTLY
June 20, 2019

In this blogpost, I am going to talk about
the importance of understanding the meaning of evaluation metrics, in
classification problems. In this way, we can select the best one and evaluate
our model confidently.
A few days ago I attended one of the frequent meet-ups of
the Python Madrid community where two use cases were presented. The first was
run by Marta Rivera Alba and the second was conducted by Francisco Javier
Ordoñez. Both are experienced Data Scientists and spoke in detail about their
current performance in the organizations where they work.
Today, I’d like to focus on the case presented by the second
speaker. To begin with, broadly speaking, the main objective of his work as a
data scientist, is to find exact products in many web pages, catalogs,
publications. I have highlighted the word “exact”, because to
consider a “match”, the two products in the images, must be exactly
the same. It’s no use being alike. There’s the key of the matter.
Now someone’s wondering. To what end? Well, with the purpose
of helping companies optimize their portfolio, prices, discounts, etc. This
makes you see, there are many cases of use of Artificial Intelligence.
Once the case was centered, it happened that at a certain
point, he alluded to the imbalance problem they had:
Finding a couple of images of
exactly the same products within the overall set of references is extremely
difficult. Therefore, instances classified as “match” (1) are
“despicable” with respect to those classified as “no match”
(0). That’s where he talked about the need to use the evaluation metrics for
his ranking model correctly.
This has served as a basis for me to write about how important it is, within data science, the correct application and knowledge of statistics. Thus, we have to in use cases solved by classification algorithms. More specifically in binary classification, there is an easy way to represent the results. It’s called a confusion matrix:
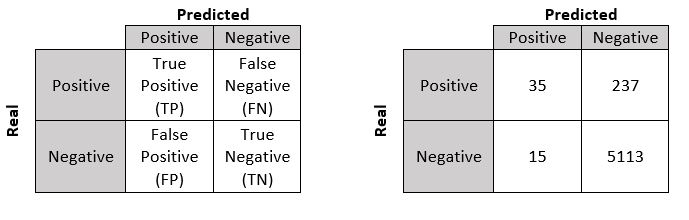
This is a constructed set of measurements that informs us about the goodness of our model. The main metrics with which we work are:

In the example above, when
calculating the accuracy value we get 95%. Awesome, someone would say.
Well, if we calculate the rest of
the measures we will see that, what seemed impressive, is not so impressive.
Moreover, for the case described above, the result would not be a good thing.
- Precision, it would be the value that
would answer a question of the style. What percentage of the positive
predictions were correct? The result would be: 70%
- Recall,
would be the value that would answer a question of the style. What percentage
of positive cases was correctly identified? The result would be: 12.90%
- F1-Score,
would be the value that answered a question of the style. How good is my model?
The result would be: 0.217
To better understand F1-Score,
let’s perform an exercise in imagination. So instead of being only 35 (TP),
we’ll exchange them for the 237 (FN). Thus, the resulting value for F1-Score
would be 0.904. While Accuracy and Recall would increase to 94% and 87%
respectively. In this way, we can conclude that: F1-Score values close to 1,
allow us to affirm that the model fulfills our purpose. Whereas, in the case at
hand, we would have to determine that, with an F1-Score of 0.217 the resulting
model is not acceptable. In a Data Science problem like this, the first thing
is to understand the Business. This will allow the use case to be handled
correctly and then advanced along with the data, in the classification models.
To then choose the algorithms, parameter search techniques, features, etc. But
also, as you have read, it is very important to understand the validation
measures of your model, to avoid being given cat for hare.
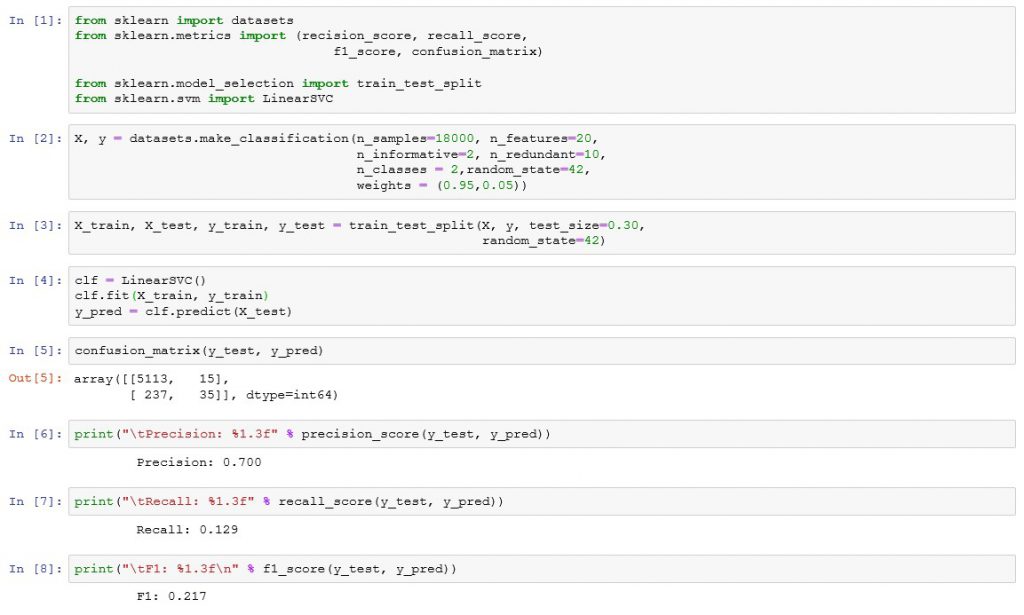
To conclude the article, I leave you a brief implementation of this example in Python using the scikit learn library, which provides the main functions, to obtain the different metrics to use in these cases. So we have:
About the author