 English | EN
English | EN 
I want to cover one way you can do CI/CD for Azure Synapse Analytics serverless SQL pools using Azure DevOps in this post. Because I know it is a popular topic.
It is related to my post about how you can create a dacpac for an Azure Synapse Analytics dedicated SQL pool using Azure DevOps. Since they are both based in the same service.
Plus, a while ago I wrote about the increase in demand for Data Platform automation. So, I really wanted to do a post about how you can do CI/CD for Azure Synapse Analytics serverless SQL pools.
By the end of this post, you will know one way you can achieve this. In addition, some open-source tools that can help SQL Server and Oracle professionals do migration-based deployments.
It is worth noting that there are other solutions available to do this. Which are either open-source or come at a cost because they provide more functionality.
Repository for Azure DevOps template
Before I go into too much detail, I have made a public repository available in GitHub that you can use as a template to do this yourself in Azure DevOps. It is called AzureDevOps-SynapseServerlessSQLPool.
One key point to remember is that when you create the password variable you must surround the value with single quotes (”).
If it proves useful for you, please give it a star in GitHub.
First success with serverless SQL pool
It took a while to get to an efficient process that satisfied me. My first success in getting CI/CD to work with a serverless SQL pool was by using DbUp.
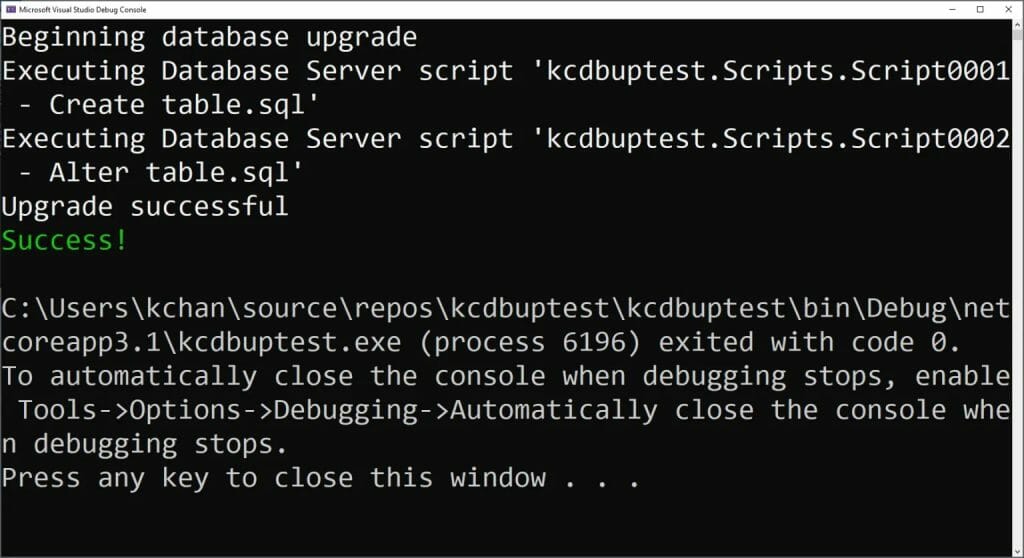
DbUp is a .NET library that you can use to do migration-based deployments. It is open-source and is licensed under the MIT license, which you can read about in the DbUp license file.
According to the official list of supported databases, it allows you to do migration-based to various databases like SQL Server and MySQL. However, I discovered it can also work with an Azure Synapse Analytics serverless SQL pool.
I had to do a few things to first get it to work in Visual Studio.
First, I discovered that the create database option does not work with serverless pools. So, I had to create the database first.
Afterwards, I discovered that I had to change the code so that it would not attempt to create a table called SchemaVersions. Which is used to track which scripts have been run. Because I was unable to create the table in a separate Azure SQL Database.
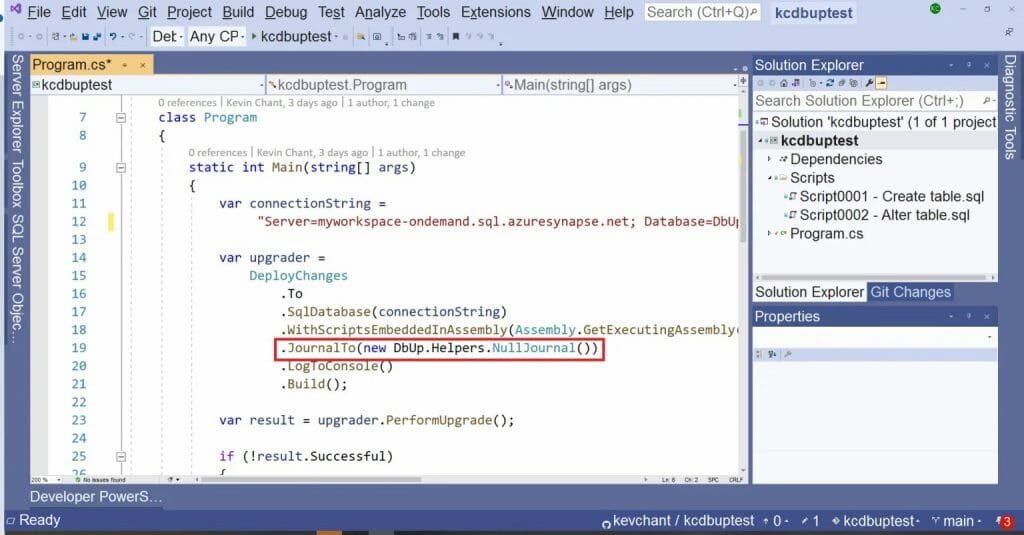
Idea is that when you want to make a schema change you add a new script to the above project. However, because there is no way to track when the scripts were run against a database DbUp will run all the scripts again every time.
So, if you are going to use DbUp or the following method in Azure DevOps my advice is to put defensive logic in your SQL code. Like in the below sample taken from the ‘Script0002 – Alter table.sql’ file that I used in the above Visual Studio project. Which I have shortened on purpose.
IF EXISTS (SELECT * FROM sys.external_tables WHERE name = 'nyc_tlc_yellow_trip_ext')
DROP EXTERNAL TABLE nyc_tlc_yellow_trip_ext
GO
CREATE EXTERNAL TABLE nyc_tlc_yellow_trip_ext (
[vendorID] varchar(8000),
[tpepPickupDateTime] datetime2(7)
)
WITH (
LOCATION = 'yellow/puYear=2014/puMonth=3/*.parquet',
DATA_SOURCE = [nyctlc_azureopendatastorage_blob_core_windows_net],
FILE_FORMAT = [SynapseParquetFormat]
)
GOCI/CD for serverless SQL pools using Azure DevOps
Moving on from there I wanted to do CI/CD for serverless SQL pools in both Azure DevOps and GitHub.
I first got this running in a pipeline by building the package using the ‘dotnet build’ command and then publishing it as an artifact. It worked; however, I thought this way was not as efficient as it could be.
So, I looked to see there was some PowerShell that could help. Whilst searching using my favourite search engine I spotted DBOps. I remembered that my friend Sander Stad (l/t) had mentioned it in a previous conversation.
So, I thought I would check it out. It is a GitHub repository that is in the Data Platform Community organization (previously known as the sqlcollaborative organization). Which was created by Kirill Kravtsov (l/t). Just like DbUp it is open-source and licensed under the MIT license. In fact, it uses DbUp for its deployment functionality.
Officially it supports SQL Server, Oracle, PostgreSQL and MySQL relational databases. However, I was able to get it to work with an Azure Synapse serverless SQL pool locally. So, I tried it in Azure DevOps.
I created a repository in Azure DevOps that contained only four files. A readme file, a yaml file for the pipeline and the two sample scripts. As you can see below it worked fine, with only those four files.
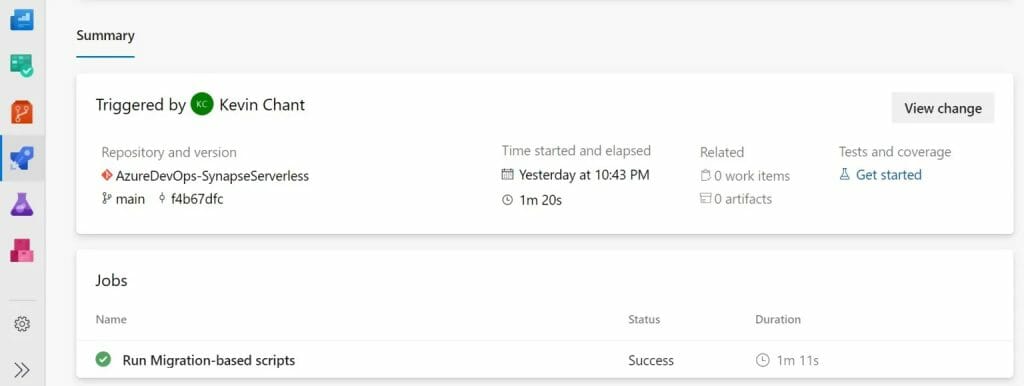
SchemaVersions table
One thing to note is that I am unable to change the location of the SchemaVersions table to be somewhere outside of the database. As I mentioned earlier in this post, that is the table DbUp uses to track which scripts have already been executed in a particular database.
It would be better to point it to a table in an Azure SQL Database or a dedicated SQL Pool instead. Because the table uses an identity column which is not supported in serverless SQL pools.
So, for now I am I am using the ‘-SchemaVersionTable $null’ syntax at the end of the PowerShell command. I have raised this as an issue. However, I have also figured out a potential workaround for it below.
You can try and work around the journal issue by creating a file in Azure Data Lake Storage that contains the headings that are mentioned in the DbUp Journaling section. From there, you can look to add it as an external table within the database you want to use in your serverless SQL pool. From there, you can reference the external table in your code.
Testing CI/CD for serverless SQL pools with two workspaces
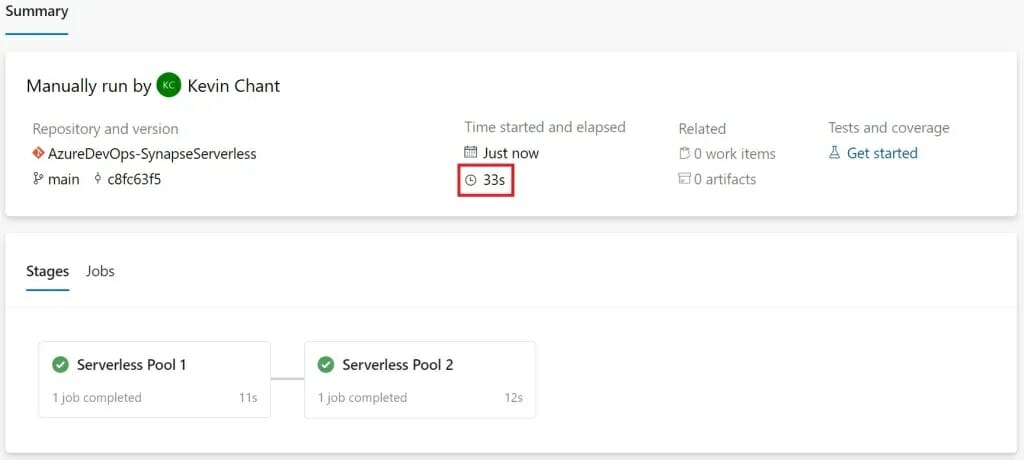
To check for consistency, I tested deploying the same two scripts to two separate serverless SQL Pools in two different workspaces.
For the first Azure DevOps example in this post, I put all the tasks in one job. Because I used a Microsoft-Hosted agent to deploy the package. So, I had to install the DBOps PowerShell module first before running the command.
However, for the second example I used a self-hosted agent with the DBOps module already installed. Which gives you more flexibility.
As you can see below, it made a big difference to the runtime of the pipeline as well.
Final words
I hope this post about CI/CD for Azure Synapse Analytics serverless SQL pools using Azure DevOps has given some of you inspiration. Because I am aware that it is an issue for a few people.
In addition, I hope it has introduced the DBOps module to some of you looking to implement migration-based deployments for other types of databases. Like Oracle and SQL Server.
Of course, if you have any comments or queries about this post feel free to reach out to me.
Please note – This blog was originally published on my personal blog here.