 English | EN
English | EN 

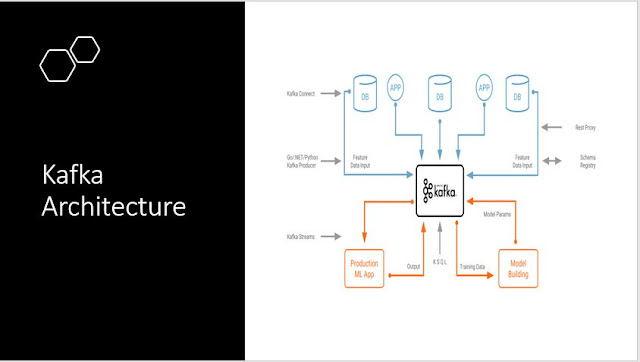
Apache Kafka is a global community-based event streaming platform able to handle trillions of events a day. Kafka was initially conceived as a message queue and is built on an approximation of a global commit file. Kafka has grown steadily from chat queue to a full-fledged event streaming platform since it was developed and launched by LinkedIn in 2011.
The Company Founded by Apache Kafka’s original developers, Confluent with Confluent Project, provides Kafka’s most full delivery. Confluent Platform expands Kafka at a massive scale with a new group and business tools designed to improve the streaming experience of both operators and developers in development.
The streaming platform requires three key capabilities:
- Writing and downloading to database sites, similar to a message queue or client messaging system.
- Store record streams sustainably in a fault-tolerant fashion.
- System document sources, as they occur
Generally, Kafka is used for two specific types of applications:
- Constructing real-time data transmission pipelines that efficiently receive data between networks or applications.
- Constructing applications that convert or respond to data streams in real-time.
The Kafka cluster stays for all written data-whether accessed or not-using a configurable retention duration. For instance, if the retention policy is set at two days, then it is available for consumption for the two days after a document is released, upon which it will be destroyed to free up space. Yes, the only metadata that is maintained per user is that consumer’s offset or location in the file. The consumer regulates this offset: usually, a customer should advance their offset linearly when they read records, but in reality, because the consumer manages the location they will ingest data in any order they like.
The mix of features ensures customers in Kafka are very cheap — they can come and go without any effect on the cluster or other consumers. For starters, you can use our command-line tools to “robe” the contents of any subject without modifying what any current users are eating. This variety of features ensures customers in Kafka are very cheap — they can come and go without having a significant effect on the cluster or other consumers. E.g., you can use our command-line tools to “tail” the contents of any issue without modifying what any current users are eating.
The log partitions are spread in the Kafka cluster over the servers with each server managing data and demands for partition sharing. For fault tolerance, each partition is replicated through a configurable number of servers. Every barrier has one server acting as the “leader” and zero or more servers operating as the “followers.” The master manages both groups to read and write queries while the followers implicitly repeat the delegate. If the leader loses, one of the supporters becomes the new leader immediately.
The Kafka Mirror Maker helps the clusters with geo-replication. Mirror Maker replicates communications through several data centers and cloud areas. You may do this for backup and recovery in active/passive scenarios; or for putting data near to the customers in active/active situations, or for serving data localization needs.