 English | EN
English | EN UNLOCKING THE POWER OF CUSTOM GPT: HOW TO OPTIMALLY LEVERAGE LLMS WITH YOUR OWN DATASET OR DOCUMENTS
August 30, 2023


Introduction:
There are humungous opportunities to leverage customized Generative Pre-trained Transformers (GPT) for various enterprises and their stakeholders. By seamlessly integrating datasets with Large Language Models (LLMs), a world of possibilities opens. However, fine-tuning LLMs comes with challenges, leading to a smarter, cost-effective solution – context embeddings. This blog explores the power of customized GPT, prompt engineering, leveraging embeddings, and fascinating use cases.
Opportunities:
Enterprises now have the chance to unlock a world of possibilities in the realm of customized GPT (Generative Pre-trained Transformer). By leveraging innovative frameworks, they can seamlessly integrate their datasets with LLMs, offering a tailored GPT experience for their stakeholders.
A new Avenue of future workstream is going to be flooded due to its power, and the experience it may bring to the customers. What if we need to provide an interactive experience to our stakeholders over the enterprise data set like a custom GPT(Chat) experience.
Challenges
Fine Tuning LLM Challenges:
Data Availability and Quality: Developing and refining a chatbot model necessitates a substantial volume of high-quality data. However, acquiring, organizing, and refining this data poses a significant hurdle for developers. Furthermore, the chatbot’s performance and accuracy heavily rely on the data’s quality. Therefore, it is imperative to ensure that the data used aligns with the training objectives.
Overfitting: A common problem encountered during the fine-tuning of chatbot models is overfitting. This situation arises when the model becomes overly specific to the training data, making it difficult to generalize to new data. To address this concern, developers must apply appropriate regularization techniques and utilize methods like early stopping and dropout to prevent overfitting.
Domain Contextualization: Chatbots must be tailored to specific domains, such as healthcare or finance. However, fine-tuning models for these particular use cases can be challenging due to differences in language and nuances of the domain that may not be adequately captured. To overcome this challenge, developers can create related datasets within the domain and fine-tune the model using this data.
Biasedness: Chatbot models can develop bias based on the training data they are exposed to. This bias can result in incorrect responses or ethical violations. To address this issue, developers should ensure that their training data is diverse and rigorously test the models for bias, utilizing fairness, accountability, and transparency metrics.
Cost: Another critical consideration in the development of chatbot models is the cost associated with training and fine-tuning. Training large-scale language models, such as chatbots, requires substantial computational resources and can be financially expensive. The expenses can include high-performance hardware, cloud computing services, and prolonged training times. Developers need to carefully balance the cost and benefits of training to achieve the desired level of performance within their budget constraints. Cost-effective strategies, such as model optimization techniques and efficient resource management, can be employed to mitigate the financial burden while still achieving satisfactory chatbot capabilities.
An Optimized Solution
While finetuning LLMs by training with enormous datasets is challenging, complex and costly, it can lead to promising outcomes. The smarter and more cost-effective alternative is context embeddings. This approach allows businesses to achieve impressive customization with minimal effort.
Though fine-tuning remains a viable option for specific applications with ample resources, the simplicity and efficiency of context embeddings make it an enticing choice for many organizations venturing into the realm of customized GPT.
Customizing Large Language Models (LLMs) like GPT-4 and ChatGPT with enterprises’ s own data and documents can significantly enhance their capabilities for specific applications. By providing context from the organization’s documents, they can obtain more accurate and relevant responses. We’ll explore a framework that utilizes document embeddings to achieve this customization effectively.
Prompt engineering:
If we put ourselves in a social gathering where we are unfamiliar with most of the attendees, and we are eager to initiate conversations, instead of simply commanding, “Talk!” we’d naturally add some prompts to get things going. For instance, we might say, “Hey, isn’t this music fantastic?” or “What’s your take last cricket match?” These prompts act as gentle nudges, providing a starting point to initiate a dialogue. This exemplifies the core concept of prompt engineering.
LLMs are context-sensitive, and by appending custom information to the prompt, we can modify their behaviour. Suppose we inquire ChatGPT about the “potential dangers of cryptocurrency investments”; in this case, it will furnish answers based on its pre-existing knowledge. However, if we preface our question with “Answer my questions based on the following research paper ” followed by relevant content on cryptocurrency risks, ChatGPT will offer responses that incorporate context from the provided document. Manually incorporating context into prompts becomes impractical, especially when dealing with numerous documents. Consider a scenario where we have a website with a vast repository of scientific articles and wish to build a chatbot using ChatGPT API. In such cases, we require a systematic method to match user queries with the appropriate articles and deliver context-aware responses. This is where document embeddings offer a valuable solution.
Leveraging Semantic using Embeddings:
We all must have experienced explaining a movie to a friend by comparing it to other movies they know. Well, semantic embeddings work similarly. These numerical vectors encapsulate the core meaning of words or phrases, enabling us to compare and comprehend their semantic significance.
These codes are very useful because they help LLMs quickly find the right information, especially when dealing with an enormous dataset.
Semantic Embeddings are numerical representations that encode various features of information. In the context of text, embeddings capture diverse semantic aspects, enabling easier measurement of text similarity. Similarly, phrase embeddings generate a numerical representation of a sequence of content.
At this step we capture semantics using embedding, now let’s see how to store and leverage them.
Embedding Database: To integrate embeddings into the chatbot workflow, we need a database that contains embeddings of the documents. If the documents are already available as plain text, we can directly create embeddings. Otherwise, techniques like web scraping or extracting text from PDFs can be used. We can use services like OpenAI’s Embeddings API, Hugging Face, or any transformer model to create embeddings. Storing these embeddings in a specialized vector database like Faiss or Pinecone which enables efficient querying based on measures.
Here a sample workflow which can be used to build such applications.
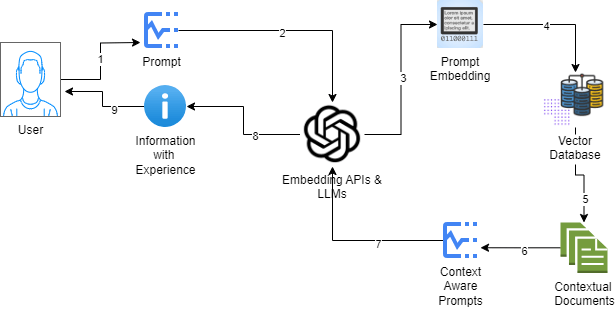
Optimization and best practices:
Maintaining Consistency in the Embeddings Framework: Ensuring reliable results heavily relies on maintaining consistency within the embeddings framework. It is essential to adhere to the same embedding model throughout the entire application. For instance, if we choose a specific embedding model for document embeddings, user prompt embeddings, and querying the vector database, sticking with this choice will yield consistent and accurate outcomes. Consider the token limitations imposed by the LLM to prevent issues with memory capacity. It’s crucial to ensure that the context data provided does not exceed the LLM’s token limit. To strike a balance, it’s recommended to keep documents limited to approximately 1,000 tokens. If a document surpasses this limit, consider breaking it into smaller chunks with some token overlap between each part. When necessary, employ multiple documents for generating responses. To avoid running into token limits, prompt the model separately for each document. This approach ensures that our customized LLM can draw upon a diverse range of sources without sacrificing the quality of the responses.
To avoid manually creating the entire workflow, LangChain, a Python library for LLM applications, can be used. It supports various LLMs, embeddings, and vector databases, streamlining the process for different types of applications like chatbots, question answering, and active agents.
In essence, by tapping into the capabilities of LLMs in a refined manner, we can effectively contextualize and attain a seamless GPT experience with our personalized dataset. The best part is this approach does not entail high training costs and time-consuming efforts.
Here are some fascinating use cases:
- Empowering Interactive Exploration of PDFs/Word/Text: Input any collection of PDFs, Word documents, or plain text, and obtain an interactive experience that enables users to explore and interact with the content effectively.
- Enabling Interactive Q&A with Audio/Video Transcripts: Upload audio or video transcripts, and leverage LLMs to provide users with an interactive experience, facilitating question-and-answer sessions over vast sets of video data.
- Transforming Excel Files into Chatbot Experience: Utilize LLMs to transform Excel files into a chatbot-driven experience, allowing users to engage with the content in a dynamic and conversational manner.
- Delivering Q&A Experience for Legal/Policies Documents: Provide end-users with an interactive question-and-answer experience specifically tailored to legal and policies documents, ensuring clarity and accessibility to important information.
About the author