 English | EN
English | EN THERE IS ALWAYS A FIRST TIME, FOR EVERYTHING. DO NOT MISS THE ARTIFICIAL INTELLIGENCE TRAIN.
August 14, 2019

This morning I was reading the interview with Larry Pizette, Head of Amazon ML Solutions Lab at AWS, in October 2018 titled: “How to Get Started with Machine Learning: Cutting-Edge Expert Tips.”
The interview, through ten questions, goes through the basic itinerary to start in Machine Learning from a business point of view. The key ones that I will delve into are: Input barriers, implementing ML and creating value.
Entry barriers: In the section, he mentions four points: data, resources, personnel and deployment.
- Indeed, one of the primary problems to any ML approach is the data. Moreover, the interview itself (page two) mentions that the data must be localized, evaluated, refined and centralized. This is key, but not only for ML solutions, but for any type of Data-Driven strategy. Making use of the very tame phrase: “Garbage inside, garbage outside”, even if you have the best resources, if your raw material is invalid, the result will be being equal.
The main characteristics such organizations are:
- They are managed based on fact and data.
- They are able to identify, combine and manage multiple data sources.
- They are able to build advanced analysis models to respond to their problems.
- They are able to use the results extracted from the data to transform the organization and improve in the decision-making process.
- They see the data as a resource of competitive advantage.
- They have changed the focus on the data, from toxic asset to value asset, which must be managed and maximized.
- Mechanisms have been established to measure the cost and value of the data.
- Incorporation into the Board of Directors of a new figure called CDO, Chief Data Officer.
- They have implemented cross-cutting and inclusive solutions in the organization, such as data governance.
- They have upgraded training programs on new technologies.
- There is a strong leadership towards analytical competence.
- They have a wide range of profile professionals associated with the data, in continuous training and growth.
- Allocate resources for the review and implementation of new business metrics and measures.
2. With respect to resources, a few days ago I attended a presentation by Intel ™ where they discussed their portfolio of solutions for Artificial Intelligence. I was very pleased with how they argued that “A GPU is required for Deep Learning” with a FALSE. But they sell chips, and somehow they have to deal with NVIDIA ™ GPUs. Jokes apart, to get started with ML, you don’t really need a huge outlay. Models can be built with hundreds of thousands of records perfectly with a laptop.
Even if you’re willing to go a step further, the Azure Cloud has multiple services that will make your job easier. With Azure ML Studio, you can build your own model in a very graphic way and then deploy it to be consumed with Excel, to more advanced solutions using Data Science-specific Virtual Machines. Distributed on both Windows and Linux, there are multiple tools installed and ready to be used, which will make it very easy to face any challenge.
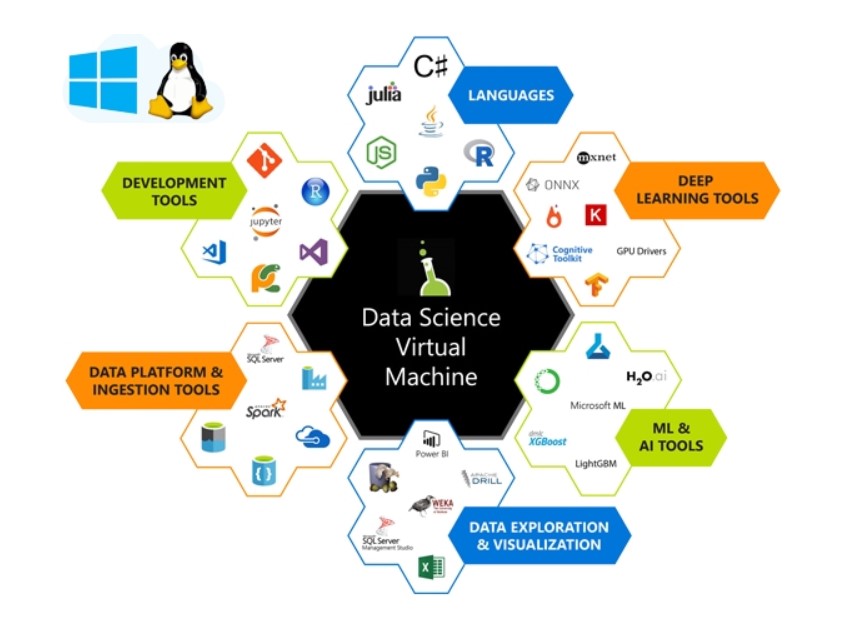
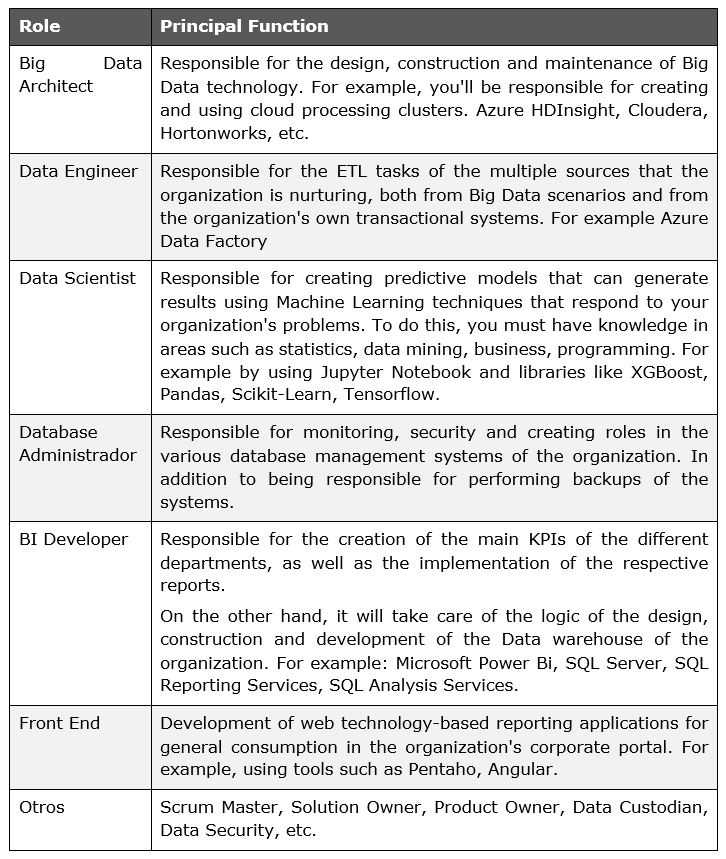
3. As for personnel, he puts the focus on Data Scientists, however, I always open the range to many other profiles, starting of course with the CDO. I believe that, whenever possible, there should be a multidisciplinary team, with profiles such as the following:
4. Finally, with regard to deployment. Here without a doubt, I think the best option is to use Cloud solutions. He talks about Amazon SageMaker ™, while I recommend the full potential of Azure ™ to deploy MLOps. Facing the development of predictive models like any other type of software, I think it brings multiple benefits. The main one, take it out of the data scientists’ own machines, as well as incorporate tests, automatic deployments, code repositories, integration with other solutions.
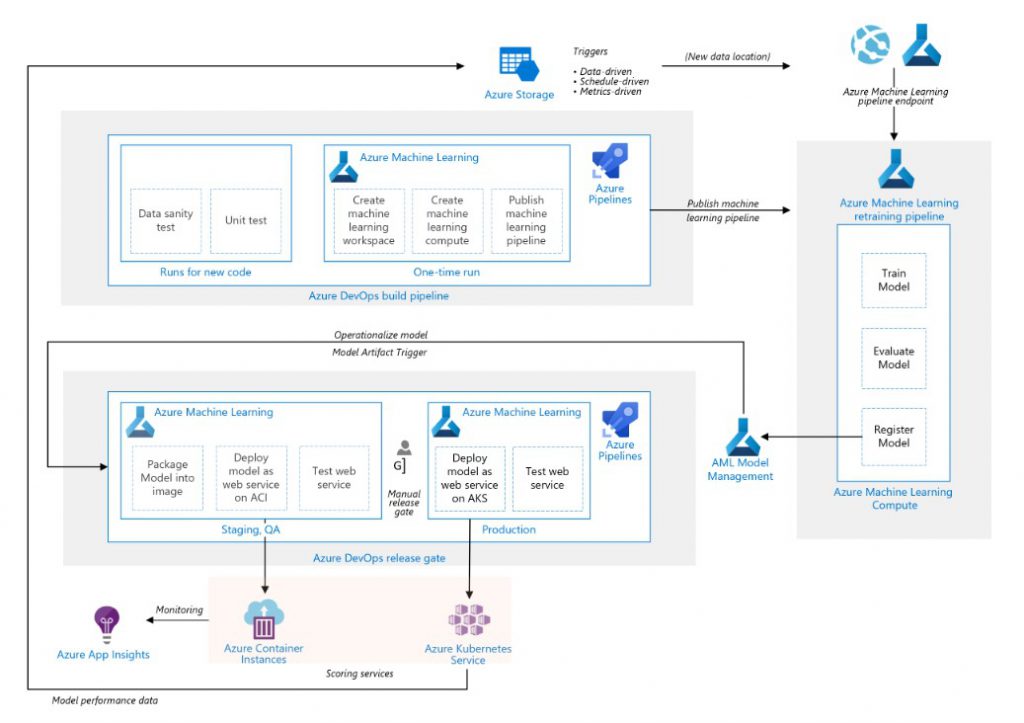
| NOTE I’m working on an article that describes a complete MLOps solution step by step. I hope to complete it soon. |
Implement ML. The approach discussed in the interview seems very accurate to me. There are many companies that want to make the leap to the systematic use of Artificial Intelligence, but they are not clear either for what or how. Just to answer these questions are organizations like Capgemini, which has an Innovation Center in Madrid, where by the hand of the client they develop all these kinds of approaches, making the processes and benefits of AI easier and more understandable.
The possibilities are many:
- Recommendation systems
- Debugging databases using log classification
- Time series analysis techniques for Forecast
- “Pricing” techniques
- Predictive models of customer abandonment, employees
- Fraud detection
- Optimization of processes, routes, chemical reactions
- Complex text recognition systems
- Management of alerts by means of image recognition
And finally, we came to show courage. This is the key to business. Over time, in addition to getting older, I see how companies with teams very aligned with Agile methodologies, are the most efficient when it comes to presenting results to stakeholders.
In my case, we work under SAFe® and two of the things I like the most, are that: we know the business value of what we are developing and that at the end of each sprint we have a “demo session” with users. With regard to the first, it allows you to get an idea of how important your work is to the user, and with respect to the second, when Friday arrives at 9:30 and we see the number of attendees connected to the demonstration, we can’t help but feel a little nervous, but also happy and proud of our work. It is at that moment when we show the advances incorporated into the development during the two weeks of work and in the end, we receive your feedback.
This way of working is undoubtedly a competitive advantage when it comes to facing any project and even more so, in the case of Artificial Intelligence.
Finally, I do not want to miss the opportunity to delve into how important it is, for these types of projects, to carry out constant validations on the results. Since many times, the algorithm functions as a “black box”, and that makes it difficult to explain to the interested party why such prediction. That is why it is vital to incorporate the monitoring of predictions and the analysis of them with respect to reality. This makes it much easier for businesses to trust the solution and encourage its use within the organization.
I hope that with these brushstrokes about the Larry Pizette interview, you’ll be encouraged to start the adventure of adopting ML solutions in your organization, in a controlled way. Without a doubt, it will allow you to approach it avoiding the risks and maximizing the benefits.
Sources:
Julio Minguillón (2018). “Foundations of Data Science”. [Consultation Date: February 28, 2018].
Marcos Pérez González (2018). “The life cycle of the data”. [Consultation Date: March 18, 2018].
Wikipedia (2018, March 21). “Macrodata“. [Consultation Date: March 24, 2018].
Wikipedia (2017, November 10). “Business Intelligence“. [Consultation Date: March 24, 2018].
Wikipedia (2017, 24 August). “Data Science“. [Consultation Date: March 24, 2018].
AWS Report (2018, October). “How to get started with Machine Learning: tips from cutting-edge experts.” [Date of inquiry: 01/08/2019]
Microsoft Azure (2019, May 9). “Machine learning operationalization (MLOps) for Python models using Azure Machine Learning“
About the author