 English | EN
English | EN THE SIX-STEP APPROACH TO COMBAT FRAUD
May 25, 2015

GUEST POST
My previous post focused on how a company might elect to view the various stages needed to effectively combat fraud, namely detection, prevention, discovery and investigation of potentially fraudulent activities.
Now, we will consider in more detail the approach needed to satisfy these requirements. Consider figure 1 below:
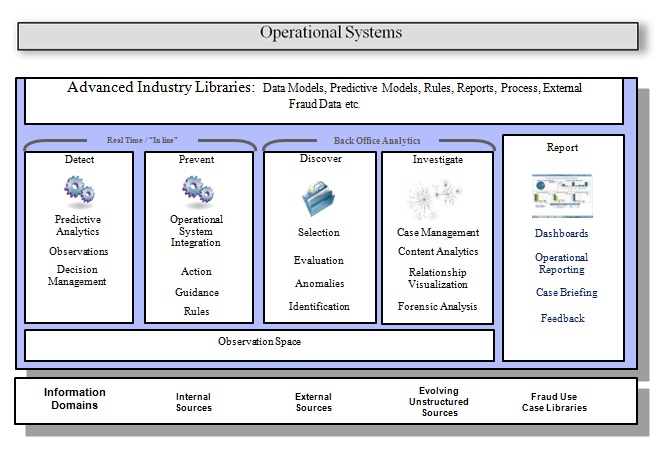
Figure 1: Functional components to support Counter Fraud
Note that some of the components are operational in nature and act in real time, and others are back office functions that augment the process by providing additional insights into the business. The final category pertains to simply reporting on the workflow and processes required to monitor and track use-of-system and to schedule work accordingly.
Operational systems can be integrated into the overall process, if required; and it is expected that various forms of data will be used to support the overall system, utilizing structured, unstructured, internal and external sources to build up a complete picture of any transaction under scrutiny. Industry libraries help to ‘fast track’ any build required for any particular industry domain.more–>
1. Detect (Advanced analytics)
Can help with discovery of anomalous data. For example: this component can focus on ingesting transactional data (a bank transaction, a benefit claim, and insurance claim) and use a variety of statistical techniques to identify patterns, clusters and outliers in the data. The goal is to understand how entities can be grouped together, based on rules or statistical models (regression and ANOVA for linear models, Markov, Bayesian models, Time Series for Stochastic models, and whether the models have been trained with prior knowledge about successfully finding fraudulent claims or not – trained and untrained models and so forth). Disclaimer – I’m not a statistician, but I know those who are!
These techniques all work to root out discrepancies that are probably non obvious and, importantly, can be be repeatable within the parameters for error that the models define.
2. Prevent (Scoring Adaptors/Rules Engines)
If we wish to identify a fraudulent claim in real or near real time, we need to apply the models to the individual transactions, as they arrive. (Note: The models still need to be created from the batch data that will continue to need to be managed and re-evaluated periodically). Typically, new data that arrive is passed to a web service where the data is scored and the results are sent back to any business application that did the original call. This can happen in a few seconds, normally. Any models deployed through statistical tools could also be augmented by capturing known business rules and embedding these into a rules engine to give a ‘matrix’ of results from both approaches that can be used to score the overall output. To enable this, we typically use a highly performant rules engine or a statistical engine, specifically designed to complement the model-driven approach mentioned in (1). Figure 2 below describes this approach:
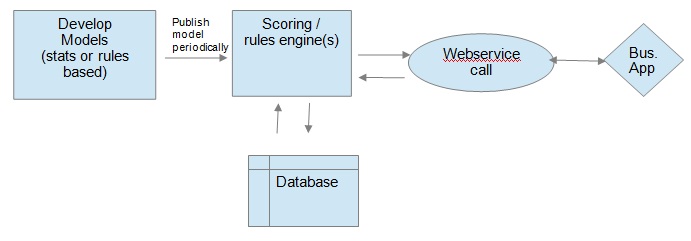
Figure 2 – Typical real time scoring approach
3. Discover (Case Management)
Once a fraudulent claim is detected (or a model can be created that suggests a claim has a probability and confidence level associated with it being fraudulent), it can be managed in some manner with the goal of identifying its importance to the business (is it large or small in size, can it be easily recovered, how long has it been since the fraud took place, etc).
This is generally done by some form of triage, which allows the most serious records to be passed to the assessors / investigators for immediate action. Such staff are generally highly skilled and in short supply, so its important to get the most important issues dealt with by them in the most effective manner. Other records could be passed onto different groups or even automated responses be derived to send e-mails / letters, etc. to try and raise awareness of any potential issue with the parties involved.
The ability to accurately track each potential fraud transaction and manage the overall business process that needs to go behind this (eg: extend the data to strengthen / disprove the case, augment the data gathered to date with other external/ internal data sets to improve breadth of knowledge surrounding the transaction/individual/account/company, add legal content if case goes to court, add case notes as case progresses etc and basically bundle all relevant dat that supports the case). This requires that a suitable case management tool be used to ensure that this highly sensitive material is managed appropriately and full audit trail of activities / changes are kept at a granular level.
The case management component is also used to bundle up any/all details to create a SAR (Serious Activity Report), which could be passed onto the appropriate authorities to drive prosecution.
4. Discover (Content Analytics)
To support a case data from sources other than structured sources may be needed. For example: Existing record management systems, e-mails, documents scanned and so on. The aim here is to extract useful data from the unstructured sources that can help to better understand the person / persons (or other entities) involved in the case. An example, here, could be extraction of key information from (say) a scanned letter to obtain details associated with any correspondence between the company doing the investigation and the potential fraud suspect. So, details of name, address, other parties mentioned, terms and conditions of any agreements might be used to help with the investigation. This could even be extended to searches across the internet, using key words to drive simple searches (eg: name of person under investigation and words such as ‘boiler room’, ‘scam’ ,’sting’ can often yield useful background information which may show individuals who have been involved in similar activities previously). This work is often undertaken manually with teams of people checking such data that could be automated relatively easily.
5. Investigate (Network analysis)
This step takes the investigation one crucial step further. If there is strong belief that a fraudulent activity has taken place, it’s often seen that there is more than one perpetrator. In such cases, we need to understand that the relationships between the person or company under investigation and other entities to ascertain if the fraud was a group effort. To do this we build network models that describe the linkages between things (nodes), linked by relationships (vertices). Figure 3 below shows such a (simple) model, it describes the relationship between various people and visually aids the user to spot the likely central person in the group. This is supported by solutions that are driven by graph databases, a NoSQL style solution specifically aimed at this area of analytics. As well as simple visualisation a set of queries that identify concepts such as ‘betweenness’, (best path to link to other nodes in the network), ‘closeness’
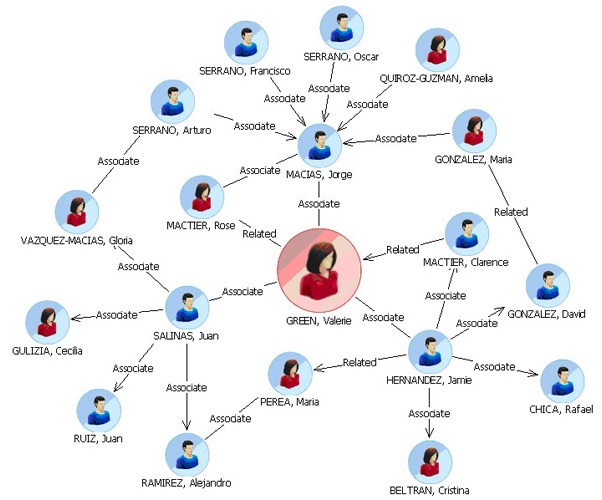
(entity closest to other nodes) or degree (the node with most connections to a node in the network). This topic has many more facets, which I can’t delve into in this short blog. For more information on graph databases, please visit the IBM website.
6. Report (Business Dashboards)
The final step is to be able to monitor accurately what the system is doing to enable the business to keep control of the overall process. This can take the form of a series of dashboards that enable any supervisor to track details such as:
– Number of cases in the system
– Number of cases in open status
– Which operators / investigators have a backlog of tasks (to enable tasks to be moved to optimize workflow)
– Successful outcomes
– Various reports on time / operator/ investigator level to monitor activity in the system.
What’s next?
This blog post has delved further into the details behind building a Counter Fraud solution (there are other elements such as entity resolution that could be added, but this article focuses only on core capabilities). My next blog post will describe how a company could deploy such a solution in a variety of ways.
Author Information
Steve Lockwood
Senior Exec Information Architect
Office of CTO Europe
Member of the IBM Academy of Technology
E-mail: Lockwos@uk.ibm.com
Twitter: @Lockwos
LinkedIn: uk.linkedin.com/in/stevelockw
About the author