 English | EN
English | EN 
Data has become indispensable in today’s business operations and the number of applications to create value from data continues to grow rapidly. Not surprisingly, organizations are investing heavily in their data assets such as data lakes, data warehouses, reporting tools and perhaps more importantly, in their data teams. Despite this strong commitment to data-driven work, we see that the data ambitions of organizations often grow faster than the power to realize these ambitions.
Central data teams and the monolithic data architecture (one central data platform for all business teams) have become the bottleneck in many organizations, as the amount of data and in particular the complexity of the data increases with the associated demand for knowledge. This can be recognized by a long backlog of new data projects. This results in, for example data scientists having to wait a long time for requested datasets and a central data team that has to operate under enormous stress because (too) many stakeholders expect something directly from them. You could say that some organizations are running up against the limits of the current set-up and the central data architecture, as a result of which the growth in the application of data has reached a plateau.
The consequences of this are significant. For example, the reaction time to exploit an opportunity increases and that’s something that doesn’t fit in a business. The pressure on central data teams is also a cause for concern. Especially in a playing field where the mix of data skills and business knowledge is scarce.
The situation is untenable and therefore the business domains and the data platform teams together need to act smarter to turn the tide.
The potential new way
In response to these challenges, a new movement has emerged: Data Mesh. Data Mesh is a decentralized sociotechnical approach, to share and maintain analytical data within complex organizations. In this blog, I dissect what this exactly means; among other things, I discuss how Data Mesh differs from traditional monolithic architecture and perhaps the most important aspect: how can Data Mesh deliver value for your organization!
Data Mesh 101
Whereas in current implementations of data platforms we often see a centralised approach (datalake, data warehouse and data warehouse), Data Mesh advocates a decentralised approach. Each business domain thus owns and produces its own analytical data and shares this with the entire organisation by means of so-called data products. To enable the teams in the business domains to create these data products, Data Mesh introduces a self-serve data platform. The focus of the data platform team is on the optimal facilitation of the business domains and not on the actual realisation of data products. To ensure that all data products still meet certain standards (for example, the implementation of legal requirements such as GDPR), there is also a specially composed team that realizes so-called policies to monitor security. The big difference with current working methods for data is that this team consists of representatives from each business domain, the data platform team and some subject-matter experts (e.g. a security specialist or someone from legal). So there is no top-down approach where, for example, a CIO prescribes the policies. The policies are the result of a democratic process: together they determine which policies are needed and how they will be enforced.
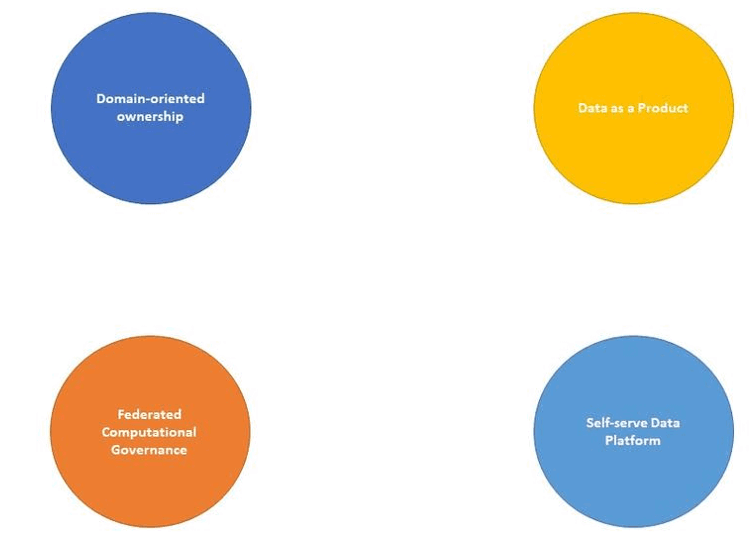
The 4 principles of Data Mesh
Data Mesh is based on 4 principles, each of which has its own purpose and interacts with each other in a specific way. I will treat them one by one to give clarity in why these principles are important and how this relates to the traditional, monolithic architectures we are used to.
Domain Ownership
Firstly, Data Mesh assumes domain ownership: analytical data is the responsibility of business domain teams. These teams are formed in such a way that they connect seamlessly to the business processes. By placing the data responsibility here Data Mesh ensures that business knowledge about the data stays close to the origin. This ensures that real insights can be gained from this data because the knowledge behind it is secured. This is in contrast to the current situation: a central data team must work with limited knowledge of data from various domains, making it very difficult and time-consuming for them to really understand the data and process it into generically usable data building blocks. One danger of assigning analytical data to these domain teams is the creation of data silos within your organization. To prevent this, the second principle, data as a product, is crucial.
Data as a product
Data Mesh introduces product-thinking in the data domain. Each domain team will realise data products and make these available to other domain teams. They in turn can use these products as input for their own data products. The arrival of data products creates flexibility in the domain teams. They are no longer dependent on the central data team that realizes the analytical data product for them. The implication is that they themselves will be responsible for their analytical data products. Think of requirements such as usability, findability and shareability with their data consumers. In addition, they are responsible for the lifecycle of the data product.
In other words: data products are stable, have a life cycle and are made public, because the added value for your organization lies precisely in sharing these data products.
The fact that domain teams are considered capable of producing high-quality data products immediately raises a question: who within these teams should do this? As stated earlier, data experts are hard to find and it is therefore not realistic to place a number of data specialists in each domain team, who can build these data products from scratch and then roll them out and maintain them. To parry this challenge, the third principle comes in handy: the self-serve data platform.
Self-serve data platform
The main goal of the self-serve data platform is to enable the domain teams themselves to produce data products. The platform does this by abstracting as much technology as possible: domain teams should be busy creating data products without worrying about underlying processes such as the allocation of compute resources; network management; the technical deployment strategy of data products or the accessibility of these data products. By designing this self-serve data platform in this way, Data Mesh ensures that on the one hand you have a facilitating data platform team that focuses entirely on building and maintaining the self-serve data platform and on the other hand that domain teams can focus entirely on creating value through data products. Ultimately, this data platform ensures that people within the domain teams are able to produce, consume and process data products without having to have deep technical knowledge about the underlying infrastructure.
Another important role for the self-serve data platform has to do with the fourth and final principle of Data Mesh: federated computational governance.
Federated Computational Governance
We now know that making data products available for use as input for new data products or for direct consumption is important: therein lies the real value! However, to do this, you need coordination between the various domains. If this does not happen, a lot of time and energy is lost in understanding and linking different data products. A simple example is agreeing on a common time zone: “Timestamps are in CET”. To define and implement these kinds of policies, Data Mesh assumes federated computational governance. In concrete terms this means that a team is put together in which each domain is represented as well as representation from the self-service data platform and additional subject-matter experts are added (for example legal and security specialists). This group jointly determines the policies, after which these policies are processed as much as possible in the self-service data platform.
We rely on everyting-as-code in the data platforms we build. This also includes policies-as-code. This helps the domain teams to follow and implement the various policies (such as “data-retention” agreements in line with GDPR).
If you compare this to the current situation, the difference lies in the fact that policies are often determined top-down (e.g. by a CIO or CDO) and these must then be implemented. Data Mesh chooses to democratise the determination of policies: they are determined jointly and then implemented in the self-serve data platform.
Sounds good! Can I start tomorrow?
Now that we have clarified what Data Mesh is, how it compares to traditional architectures and how it deals with today’s challenges, you are probably enthused about Data Mesh and would like to start tomorrow.
We realise that Data Mesh is not a solution that will immediately add value for every organisation. As long as your organisation has not reached the limits of the current solutions, this is probably not the time to make the switch. In addition, it is good to realise that Data Mesh is not simply a technical solution. Certainly, technology plays a prominent role and without the accompanying organisational and in some cases even cultural shift, Data Mesh will not succeed. That is why the decision to implement Data Mesh is a decision with great impact on your organization and must be well considered.
All in all Data Mesh is a new and very promising development within the data landscape where there are many opportunities to create value as an organisation if it is moved in the right way and at the right time (working according to Data Mesh is not realised overnight).
If you have become interested in Data Mesh and would like to talk further about the different principles of Data Mesh or what Data Mesh could mean for your organisation: send us a message via marijn.uilenbroek@sogeti.com. LinkedIn is of course also possible Marijn.
In addition, we’re obviously going to be sharing more content about Data Mesh again in the coming year, including zooming in on each of the principles across the axes of technology, people and organization.