 English | EN
English | EN SMART TROUBLE SHOOTING
March 1, 2019

Maintenance for industrial companies is in most cases a key activity, as it is critical to ensure that their product is well maintained.
Maintenance activities are generally tracked but using the return of experience is hardly evident. The reason is that it is difficult to find relevant information in a database where thousands of interventions reports are stored.
Moreover, for an international company, the sharing between multiple sites of the intervention reports is even more complicated.
For an obvious reason first: foreign language. I do believe that it is also because the tools are not adapted for this task. Actually, storing a history of interventions in spreadsheets doesn’t allow the maintainers to easily share their knowledge (different templates, difficulty to get the latest version, even different ways to maintain for the same issue).
The questions raised by this is: Could we create a tool that would help maintainers all over the world to :
- Share their knowledge with each other
- Use the knowledge of the community created for their own tasks
To achieve this goal, we needed to extract and restitute valuable information from report interventions.
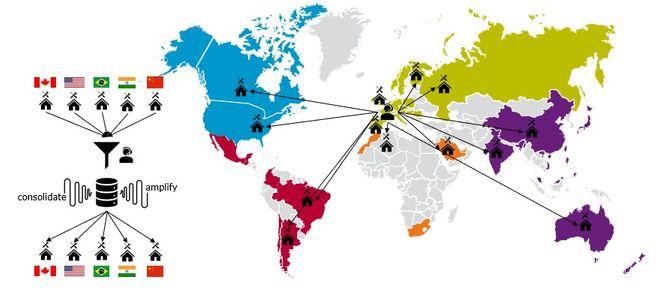
With this goal in mind, we created Smart Trouble Shooting project with our partner in the railway transportation sector.
The main idea behind Smart Trouble Shooting tool is to start by categorizing observations having the same meaning and then to predict a category of observations when a new observation is keyed in. We used state-of-the-art machine learning algorithms to do so.
Smart Trouble Shooting tool lies on 3 major tasks:
- Dealing with Input in a natural language format
- Use Artificial Intelligence algorithms to exploit data
- Display output in a friendly and non-technical Graphical User Interface
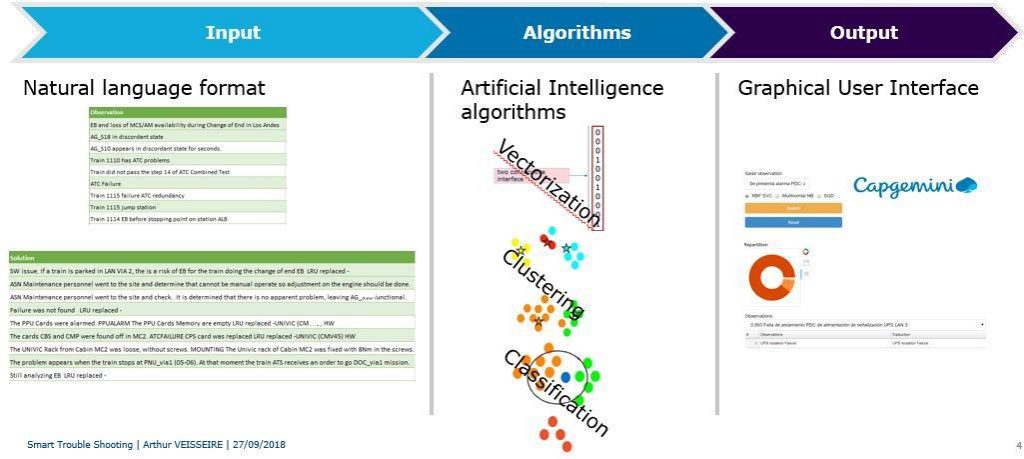
1/ Dealing with input in natural language format is the first step. Basically, the observations are cleaned. For instance, by removing characters, punctuation, stopwords (words that do not carry any meaning in itself, such as ‘and’ ‘the’ ‘a’, …), single letters and so on.
Then a stemming algorithm is used to extract the radical of words (‘conflicted’ becomes ‘conflic’, same as ‘conflicts’ or ‘conflict’). We also added the notion of contextual synonyms, to enable two different observations to be correctly connected even though it is expressed differently.
2/ Once 1st step completed, three types of Artificial Intelligence algorithms are used :
- Vectorization: this step converts textual information into a vector. It is mandatory as any machine learning algorithm uses numbers and not text as an input. Vectorization is the process that affects a weight per word, by calculating local frequencies/global frequencies ratio. The idea behind that is to affect a heavyweight to a word of importance, and lighter weight for words having more occurrences. This is the same as we naturally do when reading a text. In “the HVAC is not working” sentence, ‘HVAC’ word carries more information than ‘working’ which might be present in most observations.
- Clustering: Once all observations vectorized, unsupervised machine learning algorithms can be used to create categories. We used K-Means algorithm to regroup observations having the same meaning. The same was done for solutions.
- Classification: supervised machine learning algorithms allow us to predict a category of observations for a new observation: Logistic regressions, Support Vector Machine and even deep learning with Keras/Tensorflow were tested. It seems that combining multiple algorithms enhance global performances.
3/ The Graphical User Interface allows a user to key in a new observation and see what optimal solutions the tool recommends.
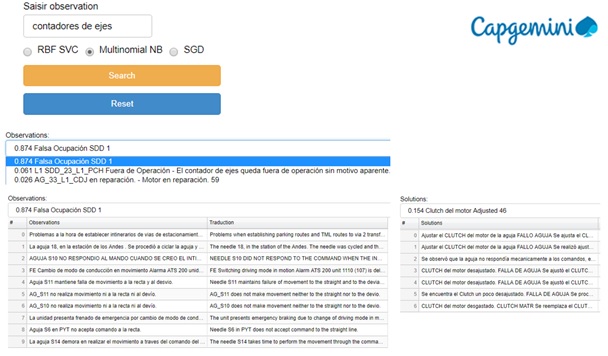
This tool can be configured to define the best solution as a mathematical formula that combines frequency/costs/time of maintenance operations.
About the author