 English | EN
English | EN 
Chatbots powered by Large Language Models (LLMs) can see significant improvements in their performance by incorporating external knowledge through a technique called Retrieval Augmented Generation (RAG).
In simple terms, RAG allows these chatbots to access additional information beyond what they were originally trained on. This extra knowledge serves two main purposes:
- It helps reduce the chances of the chatbot providing incorrect or irrelevant responses (referred to as “hallucinations”)
- It broadens the range of topics and information the chatbot can discuss.
So, how does RAG work? Imagine you’re chatting with a chatbot, and you ask it a question. Instead of relying solely on its pre-existing knowledge, the chatbot can now pull in relevant information from external sources like PDF/Word documents to better understand and respond to your query.
However, there’s a catch with RAG: the quality of the retrieved information is crucial. RAG chatbots follow the old data science principle: garbage in, garbage out. If the chatbot pulls in irrelevant or incorrect documents, it will likely generate inaccurate responses. This is where a technique called re-ranking comes into play.
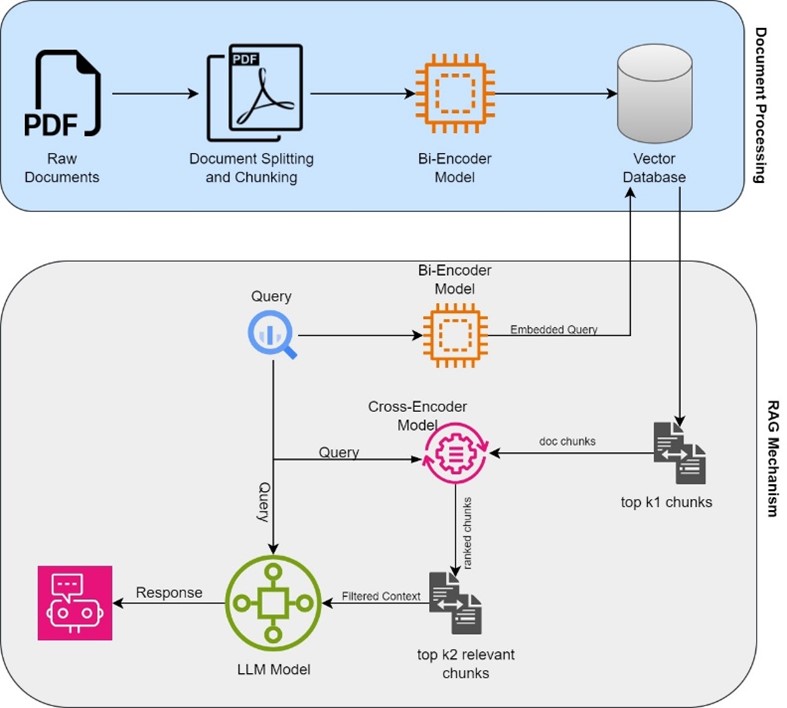
Re-ranking is like a quality check for the retrieved documents. After the chatbot initially retrieves a set of documents based on your query, a re-ranker algorithm evaluates each document’s relevance to your question. This helps prioritize the most pertinent information and ensures that the chatbot’s response is based on the most relevant sources. Let’s see in a more bit detail how it actually works.
Two-Step Retrieval
Step 1 – Retrieval with a Bi-Encoder
The very first step in a RAG pipeline utilizes a vector database containing sentence embeddings derived from numerous text fragments, where our external knowledge is stored. For this, a bi-encoder model is used. Now given a user query, we convert the query into an embedding vector using the same bi-encoder model and then perform a vector similarity search (usually by computing cosine of the two vectors) between the query embedding and all stored chunk embeddings.
However, relying solely on embeddings for similarity matching can sometimes lead to inaccuracies, as embedding vectors are a compressed representation of text, which ultimately leads to information loss.
Step 2 – Re-Ranking using Cross Encoder
Why can’t we just retrieve as many as documents possible with a bi-encoder and add them into the context of our prompt to support our RAG system with as much as information possible?
The answer is no! That is neither efficient or scalable in the long term.. Realistically:
- Context lengths are limited. For example, Llama 2 has a maximum of 4,096 tokens and GPT-4 has a maximum of 8,192 tokens.
- Documents may become obscured within our context if simply inserted. Thus, prioritizing the placement of the best document matches at the outset of the context is optimal.
This is where the second step, re-ranking with a cross-encoder, comes in. Unlike the bi-encoder, which compares each document independently, the cross-encoder evaluates pairs of documents and queries simultaneously, providing a more accurate measure of relevance.
The idea involves initially retrieving candidate documents through a bi-encoder and embedding similarity search. Subsequently, we refine the ranking of these documents using a slower method that offers higher accuracy.
For example, using a re-ranker we can refine the initial selection of the top 20 retrieved document chunks to prioritize the most relevant top 4 chunks. Overall, the goal of the RAG pipeline is to ensure that the chatbot has access to the most relevant and accurate information to provide you with the best possible response.