 English | EN
English | EN PROCESSING AND ANALYSING REAL TIME TRANSACTIONAL DATA IN AWS USING API, DYNAMODB AND GLUE
November 8, 2023

It becomes important to review real time data coming from multiple systems. This data could be any form of real-life transactional data coming from payment processing systems, CRM systems or any financial systems that record daily trades. This data must be processed to extract business value out of it and help businesses grow. This blog talks about how this data can be processed in AWS using some of its serverless and API services.
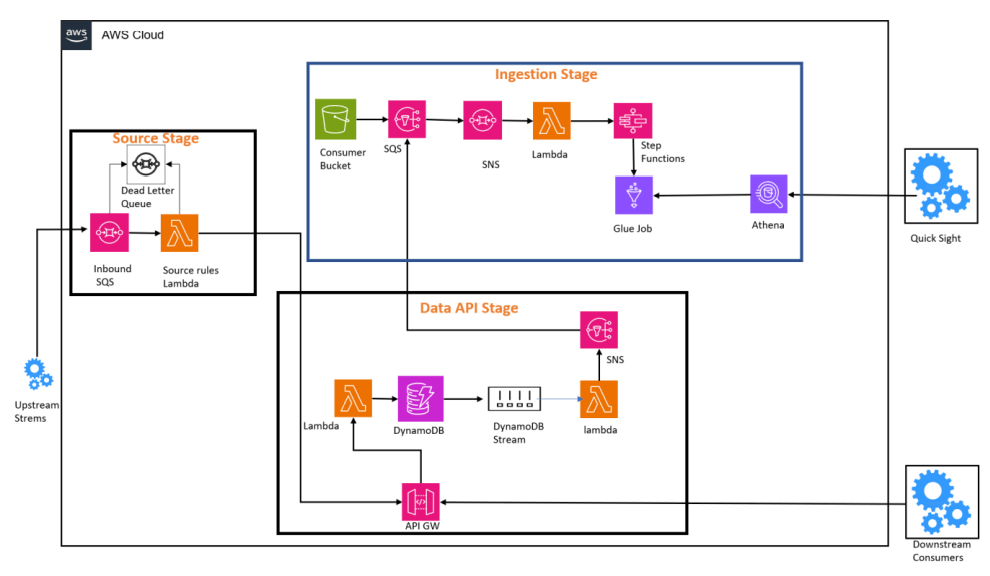
Reference Architecture
Description
This architecture comprises of 3 major stages namely Source Stage, Data API Stage, and Ingestion Stage.
In the sections below, I will explain each stage in detail:
Source Stage
- Data flowing from transactional systems needs to be formatted, standardized before it is processed.
- Source stage could comprise of inbound queues that receive messages from the source systems. The Lambda function in this stage reviews and aligns message payload with the schema definition in DynamoDB’s Data API stage.
- This Lambda also sends alert notifications (using SNS and CloudWatch) for any incoming message schema mismatches. Users can also setup a DeadLetter Queue can be used to store the messages that have a schema mismatch. Lambda function can be given permission to send the messages to DLQ if there is a mismatch in schema.
Data API Stage
- After passing schema validation, the source Lambda sends an API call to insert the messages into DynamoDB via API GW. This API gateway could have multiple authentication mechanisms like Cognito or AD authentication via a Lambda authorizer.
- This Data API stage also has abilities to perform CRUD (create, read, update and delete) functionalities on operational transactional data.
- This stage ensures that transactional data flows through the ingestion stage, capturing real-time changes in the GLUE Catalog.
- Downstream systems that might need to process the data from DynamoDB can access it via API gateway.
- DynamoDB streams perform Change Data Capture and ensure that changes happening in DynamoDB gets synced to the Glue Database.
Ingestion Stage
- Any changes in the transactional data from DynamoDB need to be captured in the Glue Database. This also means that there is a sync and parity between data present in the DynamoDB and Data in Glue Database.
- Trigger for this stage can be from 2 ways, one is that data lands in the ‘RAW’ folder created in the S3 bucket and other is any transactional data flowing from the data API stage via DynamoDB streams.
- Once the file enters that S3 bucket the schema is validated to ensure that it is aligned with the schema of the glue database. Post validation of schema files can be further processed and converted and compressed to parquet format and stored as a final transformed data in the S3 bucket.
- The reason for transforming the data to parquet format is that it becomes easier to read via Athena and helps in optimizing the speed through which data can be extracted via Athena queries.
- The Athena queries can form a backend for other downstream systems like PowerBI or Quick Sight dashboards for further enhanced data viewing.
No posts