 English | EN
English | EN 
In my 1st blog for SogetiLabs, I had applied a holistic and perhaps somehow a blurry vision of ‘no-but-allowing-code’ 3rd era Test Automation (TA) tooling. Elaborations were based on such tool utilizing Model Based Testing (MBT) techniques rather than using self-automated Machine Learning (ML) for e.g. Production user behavior log data and analyzing AI; which is generally best suited for cloud. In the second blog of the series, I will elaborate on the differences between traditional TA and ‘no-but-allowing-code’ 3rd TA era tooling; with a slightly higher non-MBT focus.
In this blog, I have grouped metrics to rate and compare several real but herein anonymized tools to keep an adequate abstract level of tools agnosticism. As a take-away, companies may use those metrics to set and eventually weigh their own required rating as a means for obtaining an informed basis for qualified decision making on new or changed TA and tooling investments.
By the way, ‘No-but-allowing-code’ 3rd TA era tooling was pioneered back in 2018 and sufficiently matured now in the 2020s – didn’t we get room for a revolution(?). However, at least in large parts of Europe, it seemingly has been too complex and hard to grasp and communicate much about this. Let’s do a little something about it, while I leverage on my TA tools vendor partnership network, keep business English conceptual, and refrain from explaining the complexity of ML-/AI-algorithmic technicalities.
The Test Debt State of Traditional Test Automation Processing

With traditional TA tooling, it has become widely known that test debt just keeps on increasing.
Let me put it in abstract Gherkin while explaining the bars in the blog image: Given that the TA team capacity is constant, when for each sprint more tests/scripts are expected to be developed (by SDETs), more TA test results are expected to be reviewed, and more TA tests require maintenance efforts (by SDETs), then the upper limit of the TA team capacity will be reached rather sooner than later.
As that happens, test debt begins creeping in, since the only reasonable activity to cut down would be on the development of new TA tests.
Unlike the 3rd era of TA tooling, traditional TA tooling does not provide any means for dealing with either entire SUT/AUT (System/Application Under Test) blueprint captures, self-healing object recognition, or self-automated or (MBT-provided) TA test generation and maintenance. Hence, traditional TA processing will always incur continuous test debt increases.
Test Automation Tooling Metrics and Ratings
The main purpose of these ratings is to document insights and concerns over anything potentially important in a particular metric. Metrics are rated per tool at a scale of 0 to 5 and weighed equally. A rating of a metric represents a conviction of how smart and to which extent that metric was met.
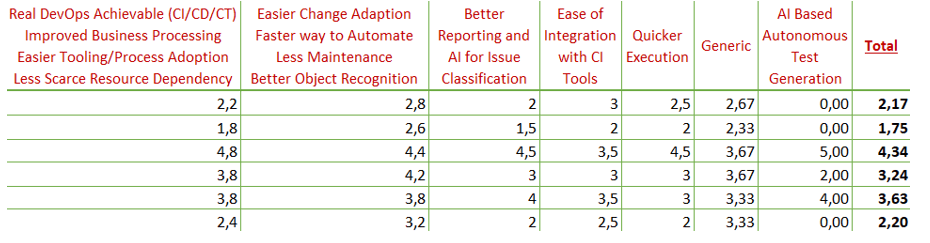
Here’s a TA tool rating overview – elaborations will follow later herein:
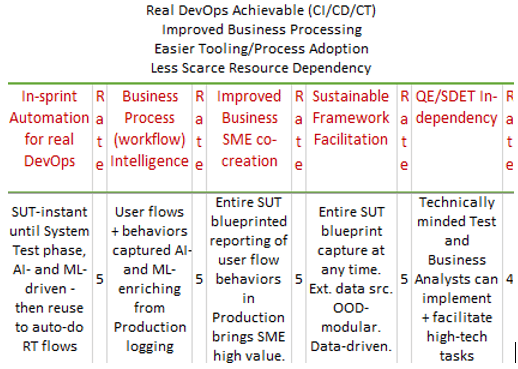
More detailed and explanatory metrics are shown below. Firstly, here’s an example of the top-scorer in the 1st metrics group – for every single rating, I have also briefly explained the criteria:
Other rated metrics in use are – i.e. except the ones for MBTA, as herein no featured tool has it:

Disclaimer: No metric was weighed higher/lower than others in its rating, as it should be up to each reader to do so – i.e. all are equally averaged. The purpose of ratings is solely to provide an indicative and comparable overview. Yet other metrics may still not occur, such as but not limited to implementation effort, support service, and license costs. In other words, this is not an evidential scientific report but is based on the author’s experiences, insights, gut-feel, common sense, and inter-relational judging.
Complete rating details are shared on demand with Capgemini clients. I look forward to receiving and considering your feedback on any other TA tool differentiating metric.
Elaborating on Ratings
Let’s get back to the TA tool rating overview (1st figure) and elaborate on that. The top-2 rows regard (A) traditional open source TA tooling, whereas all beneath are licensed tooling of which (B) the upper 3 are ‘no-but-allowing-code’ 3rd TA era tools, and (C) the last 2nd TA era licensed tooling.
The total average ranges from 1,75 in (A), while becoming Test Analyst enabling 2,2 in (C), and up to impressive 4,34 in (B). Obviously (B) is the only part having tools scoring above 0 in the ‘AI based autonomous test generation’ group, and together with the significantly high scoring 1st respectively ‘Quicker execution’ group as well as notably the metrics of ‘Adaptable to changes’, ‘Object recognition’, and ‘AI enabled’ issue classification, that would justify a company’s decision to transition into practicing the ‘no-but-allowing-code’ 3rd TA era.
In addition, I’m convinced that any cost/benefit analysis would provide the hard bottom-line arguments for such a change. By practicing the ‘no-but-allowing-code’ 3rd TA era and utilizing tools provided AI and ML, self-healing optimized object recognition and MBT-provided or even self-automating TA test generation could soon become your achieved option – that lowers both TA maintenance and TA build/development costs to a relatively low or very low minimum.
Let your tech-conceptual Test Analyst or even Business Analysts handle and control your TA, enabled by tool-SI consultants (like me), while letting your “harder-to-get-good” code-skilled QEs/SDETs look only deeper into technically tricky AI/ML challenges, also partner (tools vendor) supported. By the way, one of the tools uses around 20 different ML methods to reach its well-proven outcomes.
Concluding Endnote
Did you ever hear this executive statement?
“Companies in this country are not yet ready for ML self-healing and AI-driven self-automating TA – i.e. not yet ready for practicing the ‘no-but-allowing-code’ 3rd TA era”
It’s a statement that could be challenged by a contrary statement of:
“Companies need to try out practicing the ‘no-but-allowing-code’ 3rd TA era to stay and become even more globally competitive, keeping up with the pace of any desired IT deployment speed”
…or of:
“Companies can’t afford not to try out practicing the ‘no-but-allowing-code’ 3rd TA era in a real DevOps/MLOps highly motivated journey to replace their current TA tooling and approach”
I’m not saying that I cannot become any company’s advisor in the related area anytime soon.
But, to be honest, it should be fairly easy to try out the ‘no-but-allowing-code’ 3rd TA era as almost all the complex stuff goes on behind the scenes. Whatever doesn’t, could be handed over to the code-skilled QE/SDET colleagues – and like for any other test confidence should be build (and PoC’ed) in inputs, computing and outcomes.