 English | EN
English | EN 
Now that processing power and technological capabilities for developing Artificial Intelligence (A.I.) solutions are becoming more easily accessible, the main bottleneck often becomes data availability. There is often a mismatch between the feature space of available data (dimensions within which all our variables live) and the feature space of the Artificial Intelligence challenge you are trying to solve. Even if plenty of data is available, the dataset might be imbalanced (i.e. you have a lot data of one class, and little of another), it can lack diversity, or its use is restricted by privacy regulations (such as GDPR).
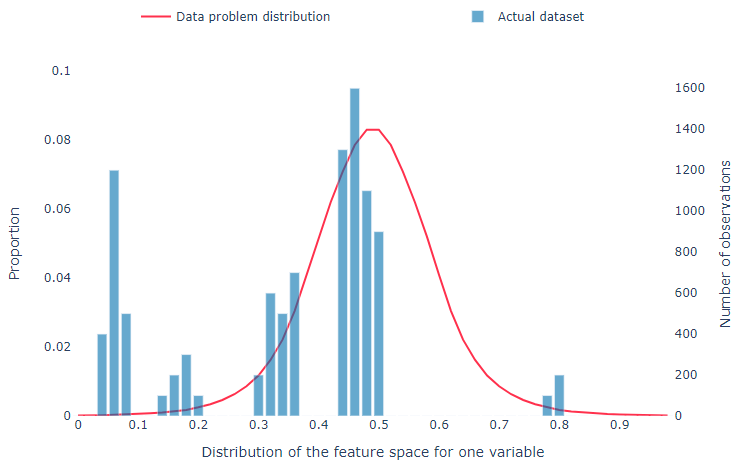
It is therefore essential that we optimize the value in the data we can use. We can achieve this by a process called Data Augmentation, i.e. artificially enlarging a dataset. Until recently, mostly rule-based data augmentation techniques were applied in practice. Now various Machine Learning approaches are available, and this substantially boosts the method’s value. At Sogeti we are enabling various customers to obtain more value from their datasets this way, and in this blog, we’ll provide examples on how you can improve your A.I. solution(s) with artificially created data too. While the focus here is on images, similar techniques also exist for tabular data and unstructured (text) data.
Rule-based data augmentation
Suppose we are interested in monitoring wildlife migration patterns. While animals are unlikely to complain about privacy regulations, it is likely that you will mostly collect empty images and it will take a long time before you have enough data to train an adequate A.I. solution. Rule-based data augmentation is a great way to get started. The intuition is simple, you apply basic changes to your image dataset which enlarges the diversity of images that the neural network sees. This reduces the mismatch between the feature space of the data set and the feature space of the problem; the deriving model becomes more generalizable to the real world (i.e. a better performing model). You can use common sense to determine what might work. In our wildlife scenario horizontally flipping (mirroring) an image will work, as an animal can walk in both directions. Vertical flipping, however, might only work when trying to detect wildlife in the southern hemisphere (just kidding). Other techniques you can try are cropping (closer to the camera), shading (illusion of different times of day) or resizing (different width/height dimensions).

Rule-based data augmentation is likely to boost performance at least with a few percent and it is a straightforward procedure, so you should go for it. But wait… there’s more!
Machine Learning based data augmentation
Trying to think of a person you have never seen is like trying to imagine a new color or taste: difficult. Yet if we could have a machine create a bunch of people that don’t exist, that would create a whole range of new opportunities. Machines have shown to be able to do this task just fine, for example check out Thispersondoesnotexist.com. These incredible results are achieved using Generative Adversarial Networks (Goodfellow et al., 2014). GANs have two neural networks that battle against each other; one that tries to create fake images that look real, and one that tries to determine which images are real or not. This is often compared to an art forger that is trying to trick an art critic/monger into believing that a forged painting is real, after receiving feedback on what the art critic believes to be real. Each network learns from the other how to become better at its task. In the beginning, the Generator will produce images that look ridiculous, even a one-year old could probably do better. However, after thousands of iterations, it will learn to create what we are interested in.
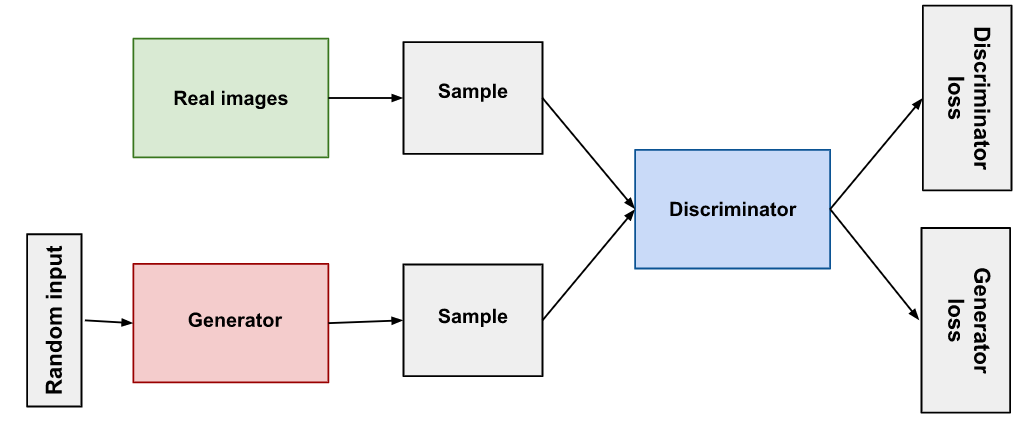
There are various ways in which this technique, or other ML-based data generations techniques can be useful. Let’s discuss the ones most relevant to our use case.
Image to Image Translation
Going back to our wildlife monitoring use case, let’s say we already have lots of data from the dry season and suddenly it starts raining. If our network is trained only on images of dry landscapes, performance is bound to drop when the land turns green. You will probably have a lot of empty images within days. But it might take a while before you again have enough images that contain animals to use in training. To use this availability of empty images to our advantage, we can train an image-to-image translation network. Here you train a neural network to learn the mapping from one type of images to another (e.g. dry season to wet season). This has been applied to for example converting summer images to winter, or even zebras into horses (Zhu et al., 2017). The great thing is that you do not need to have pictures of the different styles at the same place (this is called unpaired translation); this would be difficult to achieve in the zebra example.

Image Blending
Another method to get more data from an infrequent class is to blend the object of interest with an empty image. We might have a lot of empty images and only a few objects. We can extract the objects from their original images and integrate them into other environments, herewith making our data set more diverse. This is what we call ImageBlending, and it has the goal to make the composite image look as natural as possible. This can be done using an algorithm that derives the statistical features from the target image’s style, and iteratively converts the source object into that style. The results are generally incredibly credible as you can see in the example.

Object generation
While animals are not likely to complain about privacy regulations, I still would like to put this one in here because it has so many other applications. We can train a GAN to generate naturally appearing objects that don’t exist. We applied this method for generating synthetic people which we could then blend into an existing image of an environment. This can, for example, be useful when you are not allowed to use your own data for training due to privacy regulations. Synthetic data enables one to train your neural network and do inference (predictions) on your real data without problems. In the wildlife monitoring example, you might want to be able to detect poachers while you most likely won’t have data on it. Blending synthetic people into some of your training data can make your model familiar with this statistically unusual appearance of a human in the wild.

Final Thoughts
Data scarcity no longer needs to be a problem if you can reduce the feature space mismatch between the available data and the use case by creating diversity artificially. Real data is still preferred, but can be very costly to obtain. These methods are useful in an incredible number of use cases. Think for example of autonomous driving, security, smoke detection to prevent wildfires, tumor detection and more.
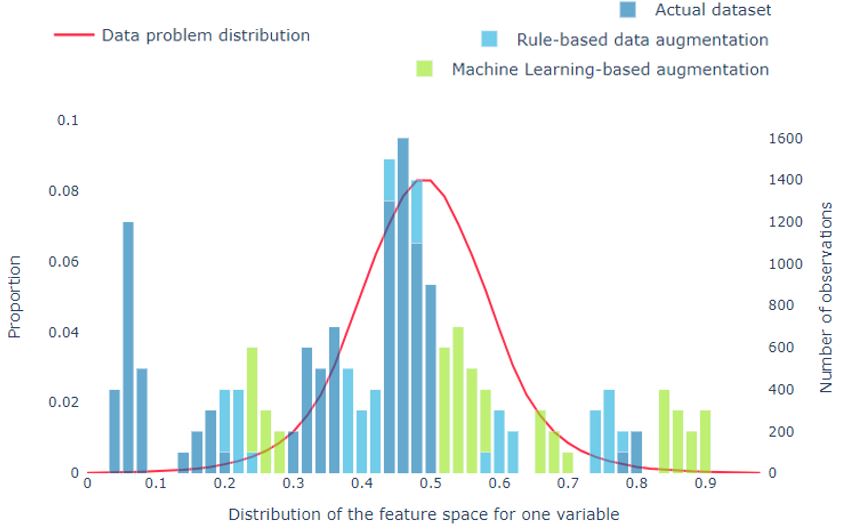
Sogeti’s solution ADA (Artificial Data Amplifier) is being used to generate synthetic MRI scans, to create synthetic people to place in synthetic images and generate fake imagery on plastic pollution — all these done to create or boost existing datasets to support training of computer vision solutions. While this blog is not an exhaustive overview of the opportunities that ADA or synthetic data provides, it hopes to provide understanding of how powerful Data Augmentation really is, and that it can substantially improve performance of your AI solution. Make sure to reach out if you are curious what it can mean for your organization.
This blog has been written by Colin van Lieshout.

As Senior Data Scientist at Sogeti, and part of the Center of Excellence of the AI team, Colin is particularly passionate about the practical application and societal value of AI solutions. With his experience in computer vision and other machine learning domains, he aims to convert an initial business question into an operational solution that creates value on a daily basis.