 English | EN
English | EN 
Customer Segmentation
Context
On a daily basis, a colossal amount of data is generated and stored across the Retail stores. The main purpose of storing such a huge amount of data is to analyze the behavior of customers and make strategies accordingly in order to drive more profits. But the amount of data generated is so huge that it makes any analysis a very difficult task.
Hence it’s prudent that retailers must group customers into subsets based on gender, geographical location, commonly purchased goods, or other defining features. These small individual subsets of customers will represent how they have contributed to profitability and business expansion. This process is called segmentation.

Problem Statement
Let’s say that you want to run a promotional campaign and give personalized offers and discounts to your top customers. But how will you find your top customers? Customer Segmentation might help you solve this problem.
Meet the Algorithm: RFM Analysis
Customer segmentation using RFM ( Recency, Frequency, and Monetary) analysis, is a marketing technique used to determine quantitatively which customers are the best ones by examining how recently a customer has purchased (recency), how often they purchase (frequency), and how much the customer spends (monetary).
RFM Score Calculations
Recency (R): Days since last purchase
Frequency (F): Total number of purchases
Monetary Value (M): Total money this customer spent
Technical Details
We perform all the data analysis using Python Pandas and NumPy. Pandas is a python library that offers data structures and operations for manipulating and analyzing numerical tables. NumPy is the fundamental package for scientific computing with Python.
Step 1: Calculate the RFM metrics for each customer.

Step 2: Add segment numbers to RFM table.
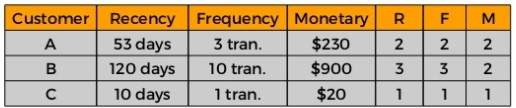
Step 3: Sort according to the RFM scores from the best customers
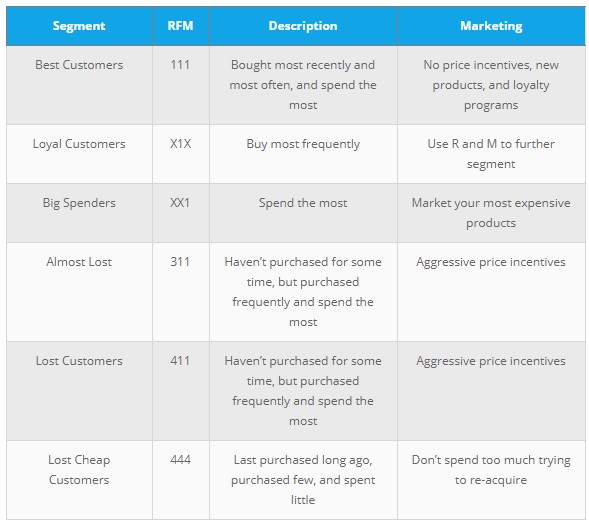
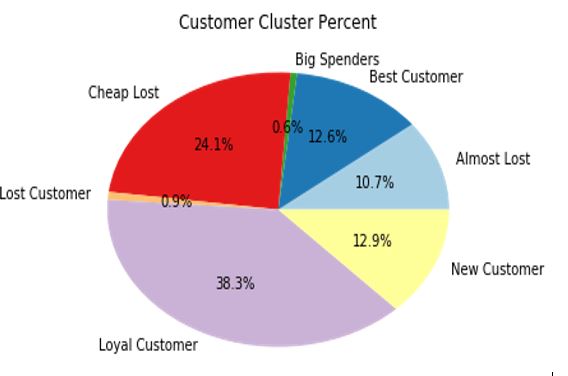
Step 4: Based on the RFM scores, create a graphical visualization of segmentation.
Fraud Detection
Context
The detection of fraud and fraud rings is a challenging activity of a reliable retailer. The main reason for fraud detection is a great financial loss caused. And this is only the tip of an iceberg. The customer might suffer from fraud in returns and delivery, the abuse of rights, the credit risk, and many other fraud cases that do nothing but ruin the retailer’s reputation. Once being a victim of such situations may destroy the precious trust of the customer forever. The only efficient way to protect your company’s reputation is to be one step ahead of the fraudsters. The algorithm developed for fraud detection should not only recognize fraud and flag it to be banned but to predict future fraudulent activities. That is why Anomaly/outlier detection algorithms prove to be so efficient.

Problem Statement
Let’s say this festive season your online e-commerce application attracted a lot of customers making their purchases. But there might be some fraudulent transactions also. How to identify such fraudulent patterns/anomalies in the data? Various classification models in supervised and unsupervised machine learning might help to solve this problem.
Meet the Algorithm: Isolation forest
Isolation Forest, like any tree ensemble method, is built on the basis of decision trees. In these trees, partitions are created by first randomly selecting a feature and then selecting a random split value between the minimum and maximum value of the selected feature.
Technical Details
Step 1: Perform exploratory data analysis on dataset to get desired features/columns.
Step 2: Perform feature selection using extra tree classifier.

Step 3: Perform cross validation on the dataset using grid search.
Step 4: Implement isolation forest model with relevant parameters.

Step 5: Print the metrics like classification report to validate the model predictions.
Churn Prediction
Context
Churn is defined slightly differently by each organization or product. Generally, the customers who stop using a product or service for a given period of time are referred to as churners. As a result, churn is one of the most important elements in the Key Performance Indicator (KPI) of a product or service. Customer retention rates are important in understanding the health of a business or a product.

Problem Statement
Let’s say a customer (player, subscriber, user, etc.) ceases his or her relationship with a company. Online businesses typically treat a customer as churned once a particular amount of time has elapsed since the customer’s last interaction with the site or service. Reducing customer churn is a key business goal of every online business. But how to achieve that?
Meet the Algorithm: Random forest
One of the approaches we use for churn prediction is Random Forest (RF). RF is an ensemble method, which creates multiple decision trees and averages/votes their predictions. It uses multiple decision trees to make predictions. Single decision trees on their own can be very effective at learning non-linear relationships (low bias, but high variance). Due to their high variance, they can tend to over-fit. Random forest reduces this variance by averaging many trees (at the sacrifice of a slight increase in the bias).
Technical Details
Step 1: Perform exploratory data analysis on the dataset to get the desired features/columns.
Step 2: Perform feature selection using select K best class.
Step 3: Perform model fitting using selected ‘k’ best features.
Step 4: Implement random forest model with relevant parameters.

Step 5: Measure model prediction using RandomForestClassifier.
Step 6: Implement accuracy metrics to validate the predictions.
Conclusion
With the increasing use of machine learning and AI, retailers can boost efficiency and productivity while actively engaging with consumers via digital and mobile platforms. There is a real need for automation and deeper data analysis to identify patterns that support cost-effective and accurate decisions. Retailers have to figure out now how to meaningfully connect with consumers who expect intuitive and convenient shopping experiences. Ultimately, retailers need to focus on bringing customers back by providing them with a complete shopping experience. Machine learning has the capability to address these concerns in the retail industry and those retailers who are counting on it will have an upper hand in such a competitive environment.
References:
https://towardsdatascience.com/find-your-best-customers-with-customer-segmentation-in-python-61d602f9eee6
https://github.com/pwinslow/Fraud-Detection
https://www.kaggle.com/cborek/predicting-telco-customer-churn-with-random-forest
This blog has been co-authored by Vijayender Riyal