 English | EN
English | EN MACHINE LEARNING: AN INTRODUCTION
July 26, 2019

When most people hear Machine Learning, they picture a robot or some futuristic fantasy. However, it is already here and in fact has been there for almost decades in some specialized areas such as OCR. But, the first breakthrough that took over the world way back in the 1990s was the spam filter. Following this, are now hundreds of ML applications that have now quietly powered hundreds of products and features that you use regularly, say better recommendations on E-commerce portals (or) a voice search.
Introduction:
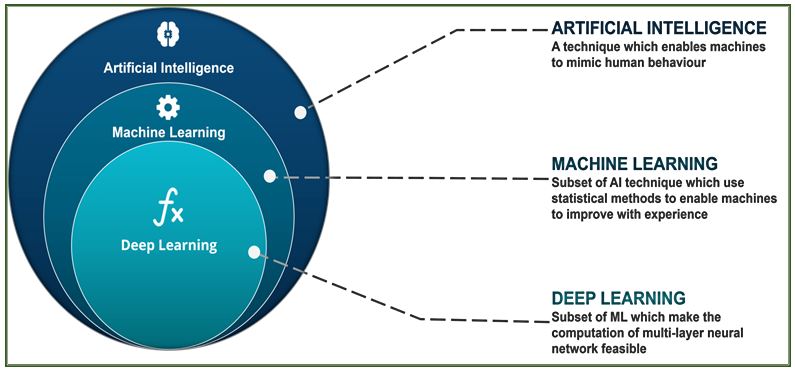
Artificial Intelligence is a technique which allows the
machines to act like humans by replicating their behavior. Artificial
Intelligence makes it possible for the machines to learn from their experience.
Machine Learning is a major field in artificial intelligence
(AI) that provides systems the ability to learn to perform tasks from
experience (i.e. training data) without being explicitly programmed. Machine
learning focuses on the development of computer programs that can access data
and use it to learn for themselves.
Deep learning is a type of machine learning that deals with algorithms inspired by the structure and function of the human brain. Deep learning systems are like how our nervous system is structured, where neurons are connected to each other and pass impulse or information
Let now take an example of the ‘Spam filter’ and try to
understand the process of Machine Learning:
The examples that the system uses are called the training set.
In this case, the task is to flag spam for new emails and the experience is from the training data. A performance measure needs to be defined, for example, you can use the ratio of correctly classified emails. This performance measure is called Accuracy and is often used for classification tasks. What is the classification? Hold on, more on that later!!
Types of Machine Learning:
There are different types of machine learning.
Generally, they are classified based on whether they are trained with human supervision or not (supervised, unsupervised, semi-supervised or re-enforcement learning)
Let’s look at the first category: –
- Supervised/Unsupervised learning:
As mentioned above, these are classified based on the type of supervision they need during their training. Below are a few of them:
- Supervised Learning:
In this approach, you feed the algorithm with the desired solutions (often called labels).
- Classification: A typical supervised learning is a classification. The spam filter that we spoke above is one such example. It is trained with many example emails along with its class (Spam, Not-Spam) and then works automatically in classifying new emails.
Used for:
- Spam filtering
- Sentiment analysis
- Recognition of handwritten characters and
numbers - Fraud detection
Popular algorithms: Naive Bayes,
Decision Tree, Linear Regression, Logistic Regression, K-Nearest Neighbors,
Support Vector Machine, Neural Networks
ii. Regression: Regression is basically a classification where we forecast a number instead of category. Examples are car price by its mileage, traffic by time of the day, demand volume by the growth of the company, etc. Regression is perfect when something depends on time.
Used
for:
- Stock price forecasts
- Demand and sales volume analysis
- Medical diagnosis
- Any number-time correlations
- Unsupervised Learning:
Unsupervised
was invented a bit later, in the ’90s. It is used less often.
Labeled data is luxury. But what if I want to create, let’s say, a bus classifier? Should I manually take photos of million buses on the streets and label each of them? That will take a lifetime and is practically not feasible.
- Clustering: Clustering algorithm tries to
find similar (by some features) objects and merge them in a cluster. Those that
have lots of similar features are joined in one class. With some algorithms,
you even can specify the exact number of clusters you want.
Used:
- For market segmentation (types of customers,
loyalty) - For image compression
- To analyze and label new data
- To detect abnormal behavior
Popular Clustering algorithms are:
- K-Means
- DBSCAN
- Hierarchical Cluster Analysis (HCA)
- Visualization and dimensionality reduction: It is nowadays used for recommender systems, topic modeling, etc. Popular algorithms are:
- Principal Component Analysis (PCA)
- Singular value decomposition
- Association rule learning: It looks for patterns
in the data. It is used: To forecast sales and discounts, To analyze goods
bought together. Popular algorithms: Apriori.
This
includes all the methods to analyze shopping carts, automate marketing
strategy, and other event-related tasks
- Reinforcement Learning: Reinforcement Learning is a very different beast.
The learning system, called an agent in this context, can observe the
environment, select and perform actions, and get rewards in return (or
penalties in the form of negative rewards). It must then learn by itself what
is the best strategy, called a policy, to get the most reward over time. A
policy defines what action the agent should choose when it is in each
situation.
- Neural Networks and Deep Learning:
Used today for:
- Replacement of all algorithms above
- Object identification of photos and videos
- Speech recognition and synthesis
- Image processing, style transfer
- Machine translation
Popular architectures: Perceptron, Convolutional Network
(CNN), Recurrent Networks (RNN), Autoencoders
Any neural network is basically a collection of neurons and connections between them. The neuron is a function with a bunch of inputs and one output. Its task is to take all numbers from its input, perform a function on them and send the result to the output
Convolutional Neural Networks (CNN)
Convolutional neural networks are used to search for objects
on photos and in videos, face recognition, generating and enhancing images and
improving image quality.
Recurrent Neural Networks (RNN)
The second most popular architecture today. Recurrent
networks provide useful features like neural machine translation, speech
recognition and voice synthesis in smart assistants. RNNs are the best for
sequential data like voice, text or music.
Main Challenges of Machine Learning:
In short, since our main task is to select a learning algorithm
and train it on some data, the two things that can go wrong are “bad algorithm”
and “bad data.” Machine Learning is not quite there yet; it takes a lot of data
for most Machine Learning algorithms to work properly.
Poor-Quality Data: Obviously, if your training data
is full of errors, outliers, and noise (e.g., due to poor quality
measurements), it will make it harder for the system to detect the underlying
patterns, so your system is less likely to perform well.
Irrelevant Features: Your system will only be capable
of learning if the training data contains enough relevant features and not too
many irrelevant ones.
Testing and Validating
The only way to know how well a model will generalize to new
cases is to try it out on new cases. The recommended option is to split your
data into two sets: the training set and the test set. As these names imply,
you train the model using the training set, and you test it using the test set.
The error rate on new cases is called the generalization error and by evaluating
your model on the test set, you get an estimate of this error. This value tells
you how well your model will perform on instances it has never seen before.
Stay tuned for my next blog, as I delve deep into various
areas of Machine Learning!
About the author