 English | EN
English | EN JANIS, BRUCE AND BEATLES. DEFINING THE RULES OF ASSOCIATION
September 13, 2019

I have recently had to delve into the use of association rules algorithms to improve understanding of certain datasets. All this through the search for patterns that would improve the quality of the result.
But what are the association rules? They are those that allow us to find sufficiently significant concurrences between groups of variables. A practical example would be to identify the degree of concurrency between groups, through the musical consumption of users of a streaming music platform.

In this case, as I have mentioned before, we will have a series of user records indicating: the user ID, the name of the artist heard, the gender and country of the user.
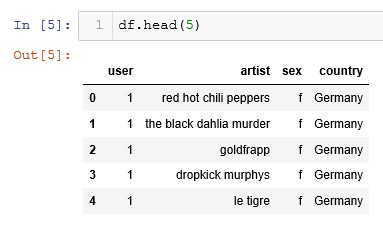
Its good practice that whenever you’re dealing with a dataset, perform a basic set of descriptive statistic tasks to be able to find out something else, such as how many musical groups have been included and which is the most listened to.
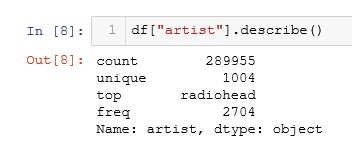
As a result, we see that there is a total of 1,004 different groups and that the group that is most often repeated is Radiohead, with a total of 2,704 times. I’m sure it’s because of your song Creep.
We then perform the same task on the “gender” and “country” fields. In this way, we can increase our information about the dataset. The results were as follows:
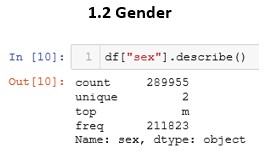
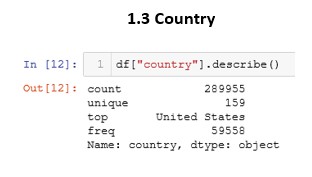
Clearly the sex of the users of this platform is male and by country, we see that the United States in the most repeated with a total of 59,558 occasions, there being 159 different countries in the dataset.
IMPORTANT
That comes to be the transposition of the set of groups with respect to the users, assigning 0 or 1 to “not heard” or “heard” respectively.
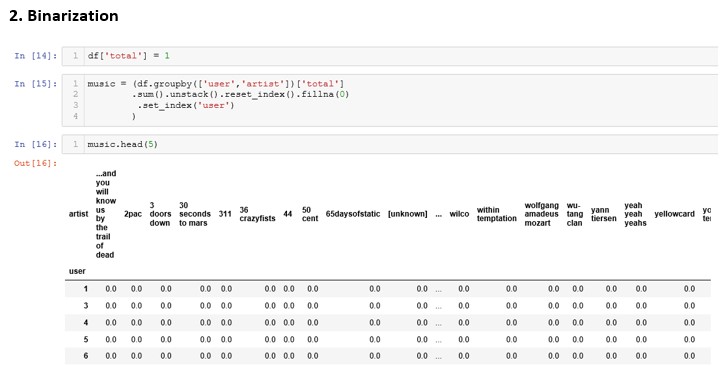
From there, that’s when we use the apriori algorithm of the MLXTEND library. To construct the association rules model on the binarized set. In the end it returns a set of values that I will explain below.
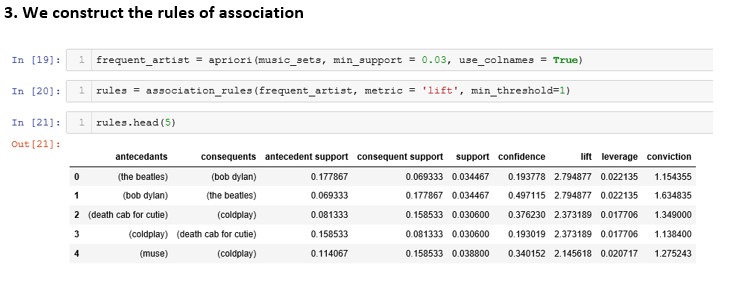
Support: It is the relative frequency at which rules appear. In many cases, you may want to look for high support to make sure it is a useful relationship. However, there may be instances where low support is useful if you are trying to find “hidden” relationships.
Confidence: Trust is a measure of the reliability of the rule. Confidence of .497115 in the example would mean that in 50% of the cases where Bob Dylan was heard, the user also listened to the Beatles. For the musical recommendation, confidence close to 50% may be perfectly acceptable, but in a health situation, this level may not be high enough.
Lift: The elevation is the ratio between observed and expected support if the two rules are independent. The basic rule is that an elevation value close to 1 means that the rules were completely independent. Elevation values > 1 are generally more “interesting” and could be indicative of a useful rule pattern.
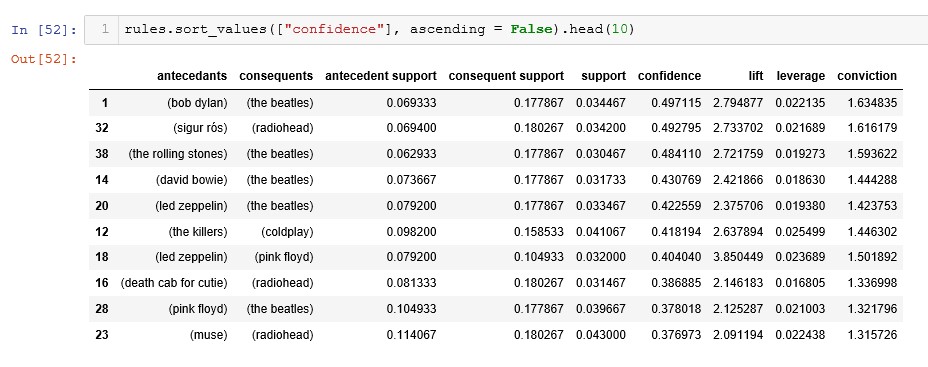
Continuing our analysis, if we now ordered worth of confidence to take the top 10 results we would get:
CONCLUSION
The rules of association are widely used in product and service recommendation projects. As we have seen, analyzing the music taste of the users, through the consumption of music in the platform, we have been able to obtain a set of association rules that serve us to be able to send a commercial communication to a Beatles fan of such as:
“Bob Dylan will release his new compilation next Saturday, and you will be able to listen to it exclusively on our platform”.

About the author
I got thiѕ webѕite from my friend who shared with
me about this web page and now this time Ι am browsing this site and reading very informative articles or reviews at
this place.