 English | EN
English | EN HOW TO AVOID CONFUSING THE TERMINOLOGY IN MACHINE LEARNING
September 5, 2019
Terminology may seem like a trivial subject, but there have been and will continue to be a lot of misunderstandings when people use conflicting terminology. There is one example in the subject of machine learning which often is the base for misunderstandings. This concerns the term test data.
The problem often occurs when data scientists and testers talk about test data. For a data scientist who trains a machine learning algorithm, it is very clear what test data is. It’s also very clear what test data is for a tester who tests a machine learning algorithm. Unfortunately, often they don’t mean the same thing. The next figure shows how (for as far as we have found) the terms “training data, test data and validation data” are commonly used among data scientists.
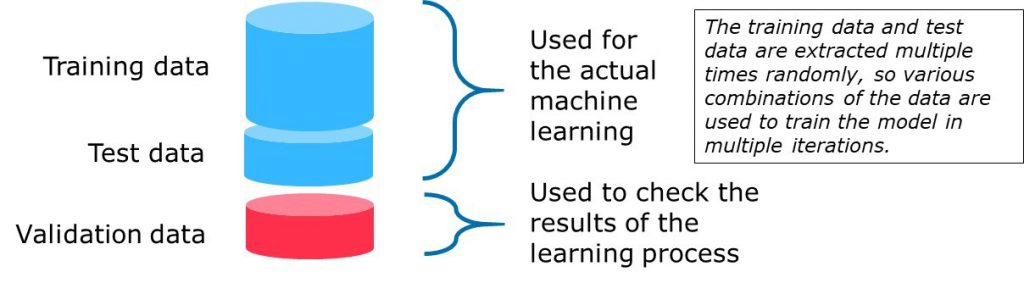
The data that is used to train the machine learning algorithm is split into training data and test data. The machine learning algorithm learns from the training data and (automatically) uses the test data to check if the learning was successful. After the first round of learning the original dataset is again split up in training data and test data (but differently) and the second round of learning starts. After many rounds of learning the algorithm is supposed to be ready with learning. Then a separate set of data (that the algorithm has never seen before) is used to validate if the algorithm indeed has properly learned and is ready for operational use.
If data scientists and testers are aware of this process and the fact that there are three different types of data involved, then they can easily agree on what name to use for which part of the data. Our impression is that data scientists prefer the terms as shown in the figure above, but testers usually would exchange the words test data and validation data because that seems to align better with common testing terminology.
Our advice is to always check terms and definitions as long as there’s no worldwide consensus. The need for discussions around terminology increases when you’re working with people from different backgrounds. Even the most trivial of terms can be the source of grave misunderstandings. So, an open discussion around the terms used can be crucial for the success of the project.
So, how do we avoid confusing the terminology? In machine learning, we use a lot of data for different purposes as we’ve discussed. One way to avoid misunderstandings is to gather everybody involved in a workshop. Start with discussing the different purposes you will use data for. This will result in a list. For each purpose, discuss what term you use for it. To find each different term used, each person should note the term he or she uses on a post-it. For some purposes there will be a common term used by everybody, but not for most. Discuss the purposes for which you use different terms and decide upon one of them. The result of this workshop will be a list of the purposes we use data for and the term we use for that data. When new people arrive, it’s easy to go through the list to avoid misunderstandings. This is a simple technique that has worked well for us.
This blog was written by Eva Holmquist (Sogeti Sweden) and Rik Marselis (Sogeti Netherlands).
Eva Holmquist is a senior test specialist at Sogeti. She has worked with activities from test planning to execution of tests. She has also worked with Test Process Improvement and Test Education. She is the author of the book “Praktisk mjukvarutestning” which is a book on Software Testing in Practice.
Rik Marselis is a test expert at Sogeti. He worked with many organizations and people to improve their testing practices and skills. Rik contributed to 19 books on quality and testing. His latest book is “Testing in the digital age; AI makes the difference” about testing OF and testing WITH intelligent machines.