 English | EN
English | EN 
Siri, what’s the latest news update?
OK, now playing the blue station.
OK Google, what’s the weather for today?
I’m sorry, I didn’t quite catch that.
Everyone has had an experience where we try to use our voice assistants on our phones and other devices only to have it respond with the most quirky, random things or otherwise not even try. This seems to be a rather ubiquitous experience – this shared moment of bemusement, laughter, and annoyance is so pervasive, we can even see it in pop culture. For example, take this scene from Antman:
As my brother likes to put it: “Millions of dollars and this is the best we can do?”. Of course, the software engineer in me wants to respond that it’s a lot more difficult to make than you’d think but he has a point – we can do better. But whom exactly are we making it better for?
For many people, voice-based software such as personal assistants like Siri and Alexa are a simple tool that can help us know the weather, keep track of alarms and shopping lists, or read to us our morning news. For others, particularly those requiring assistive technology, they are invaluable in how they interact with the world around them.
If you’re reading this blog post, then there’s a good chance that you interact with the software in English. Perhaps you, like myself and millions of others around the world, speak English with an accent. Perhaps English isn’t your native language – you’d prefer to speak in Hindi, Spanish, German, or something else entirely. Maybe you don’t even speak English at all or instead use a mixture of languages in the same sentence such as Spanglish or Hinglish.
These people often experience the most frustration with this software because the software regularly fails to work properly for them. This is no fault of theirs; the software likely wasn’t extensively trained with their language, accent, or dialect. Chances are, the voice data was American English coming from white, middle-aged men (Washington Post).
The obvious solution is to use a larger dataset with more diversity so that more people are covered. But this data can be expensive to obtain and is sometimes proprietary. Of course, the more people use their devices, the more data is being generated which we assume will improve the speech recognition patterns over time. However, this isn’t exactly a reasonable solution – would you want to use something that is routinely broken for you in the hopes of a vague promise that it will eventually be just as good as it is for your friends?
Even if you decide to create your own dataset, you need lots of data. Once you have that, you must train it on what’s good and what’s bad. Creating these models takes a significant amount of time. This is the problem that Mozilla is attempting to tackle with their Common Voice initiative. With Common Voice, anyone can help – be it by creating the initial data or by helping train it!
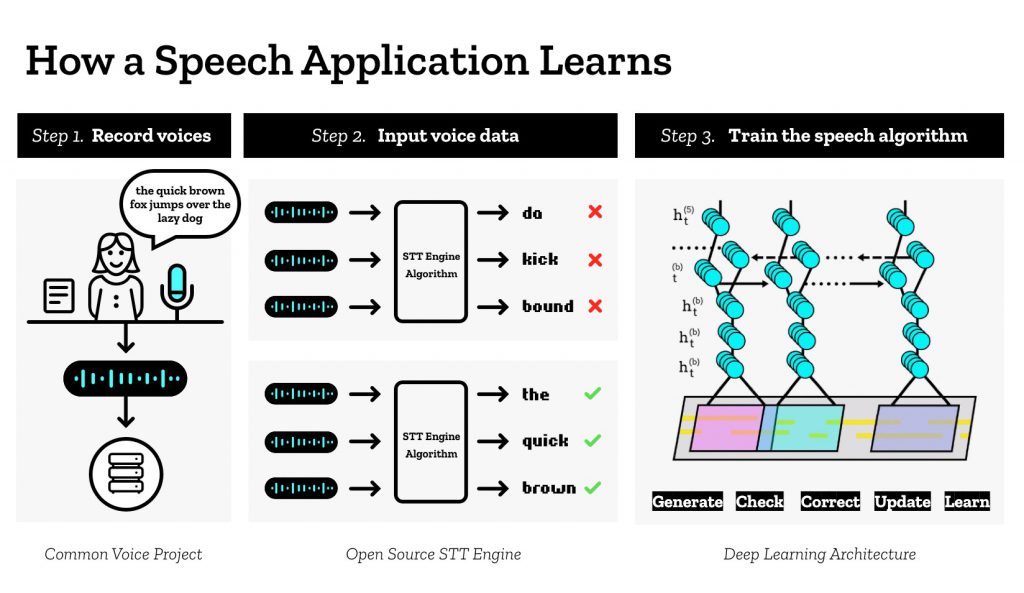
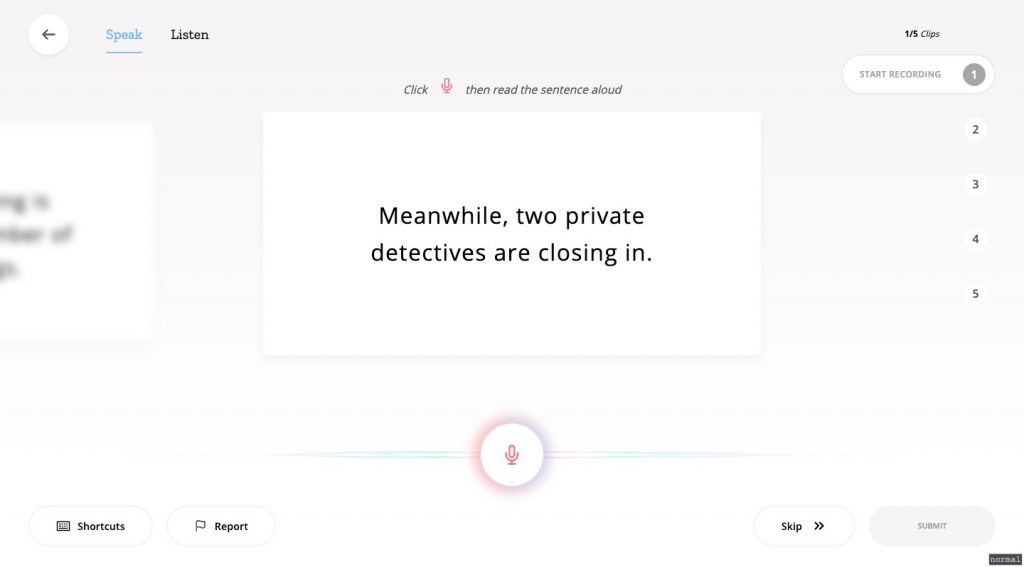
It’s incredibly easy to do – all you need is to say the sentences shown on the screen. Simply record your voice five times and then submit the data which will then be added to the data to be trained.
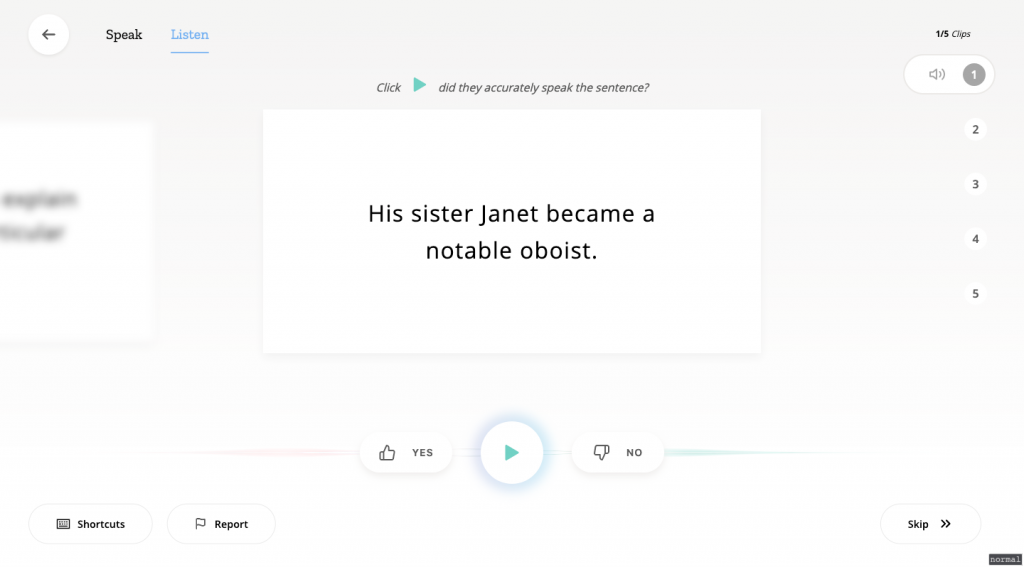
Similarly, anyone can also listen to the few lines and validate that the voices are words are clearly stated and would make for good training data. The interface for it is just as simple to use as the one for listening. Listen to the line, and then validate it as to whether you think it is good or bad. The criteria for what’s good or bad is entirely subjective to you, the listener.
You don’t even need to make an account – for both screens above, I was able to record and train without signing up for anything! For those willing to make an account, they can help better categorize the data by providing some basic demographic information such as age and gender (with personally identifying information always kept private). This can help classify voices into data that can be tailored for specific contexts.
The beauty of this initiative is free and open to everyone. You can donate your voice in any language and help build a dataset that is rich for the language you speak. While I’ve only shown English in the images above, you can select from any language you wish – or add it to the list if it’s not there! Furthermore, anyone is able to take the data and use it as they wish – for free; be it building a better voice assistant, creating assistive, accessible technology, or simply using it in systems to create more natural, pleasant to hear voices for our interaction.
References:
https://www.washingtonpost.com/graphics/2018/business/alexa-does-not-understand-your-accent/
https://hacks.mozilla.org/2019/12/deepspeech-0-6-mozillas-speech-to-text-engine/
https://research.mozilla.org/machine-learning/
https://voice.mozilla.org/en/listen
https://voice.mozilla.org/en/speak