 English | EN
English | EN 
Azure Data Factory Use Case Series – 1
In this blog, I will show you step-by-step of extracting nested JSON data from REST API and loading into Azure Synapse Analytics using Azure Data Factory.
Requirement: Recently one of my projects was to extract data from an REST API site every 30 min to get updated data and loaded into Azure Synapse Analytics as a table. I would like to share one of the method I was using.
Overall high-level pipeline setting
This includes 3 steps, 1st step is to load API data into blob (.json files); 2nd step is to load blob file to ADW; last step is to implement incremental logic for updating table inside Azure Synapse Analytics and to incorporate the API data into downstream ETL steps.

If we directly load API data into Azure Synapse Analytics, the nested json file cannot be correctly mapped to Azure Synapse Analytics tables, so we need to utilize Flatten transformation inside Azure Mapping Data Flow (https://docs.microsoft.com/en-us/azure/data-factory/data-flow-flatten) to unroll array values into individual rows. Details for setting up this step will be talked about later in this blog.
Step 1: Loading API data into blob
Because one API call will have more than 1 page, so we need to use Until activity to iterate the pages for API call.
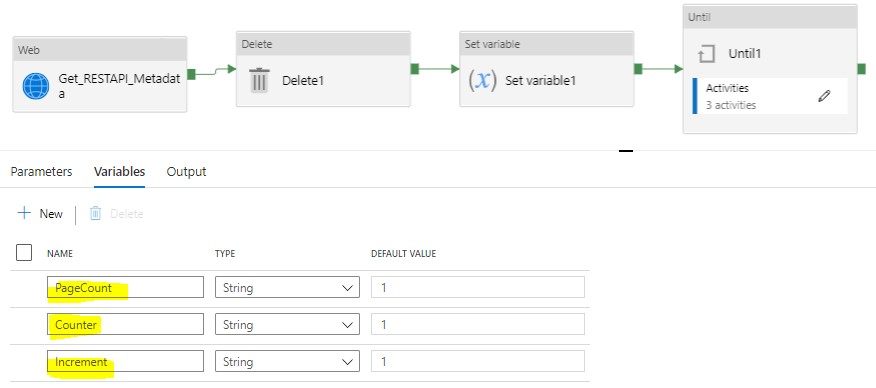
For completing this iteration, we need 3 variables: PageCount, Counter, and Increment.
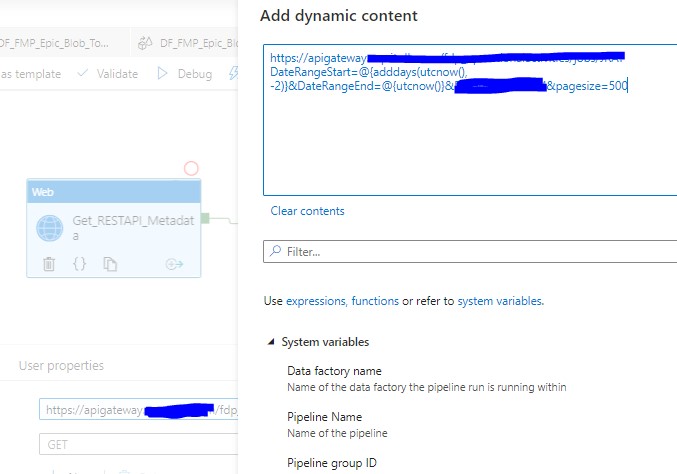
We use Web activity to get API metadata, and assign the totalpages to PageCount variable. Please note here we only get last 2 days’ data from REST API since we want to set up incremental load.
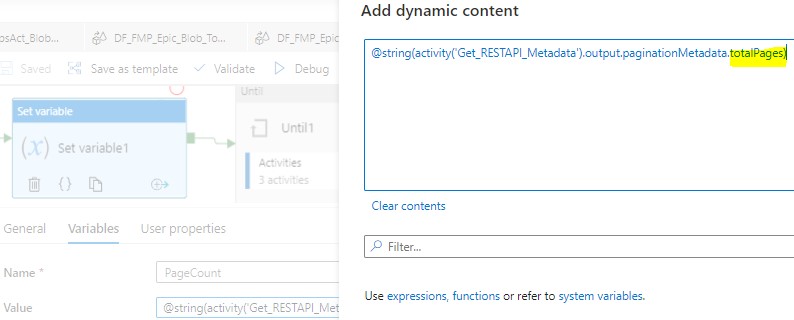
PageCount was giving dynamic value: @string(activity(‘Get_RESTAPI_Metadata’).output.paginationMetadata.totalPages). Basically, this will set up how many pages/iterations the Until activity will be performed.
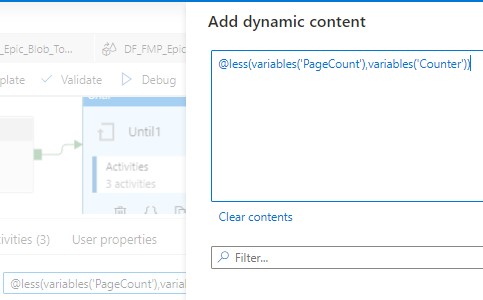
In the Until activity settings, we use the expression “@less(variables(‘PageCount’),variables(‘Counter’))” to determine when the iteration will stop.
Then inside the Until activity, we have the follow setting.

First activity is for the actual copy data step from REST API to Blob storage, one page per time. Then we increase Counter value by 1 after each copy using the @string(add(int(variables(‘Increment’)),1))
Step 2: Transform json files from blob and load into Azure Synapse Analytics stage table
After Until activity, Json files from all the pages in the API call have been loaded into Blob storage, next we will transform those files to load them into a table inside Azure Synapse Analytics. For this transformation, we use Flatten activity.
Flatten activity was introduced on 2020-Mar-19 to the existing set of powerful transformations available in the Azure Data Factory (ADF) Mapping Data Flows – https://docs.microsoft.com/en-us/azure/data-factory/data-flow-flatten.
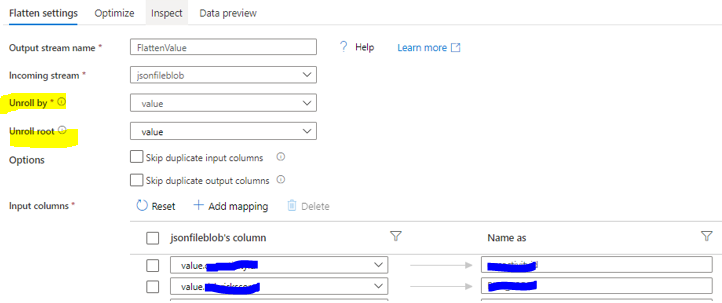
Here is the setting:
Flatten transformation is powerful but very simple to use. What we need to find out which array you want to unroll by selecting it in the drop down lists as well as find out the Unroll root. By default, the flatten transformation unrolls an array to the top of the hierarchy it exists in.
Step 3: Updating table inside Azure Synapse Analytics
Since we only load last two days’ data, so we will need to append and update the full stage table. One of the method I was using is a simple stored procedure as follow:
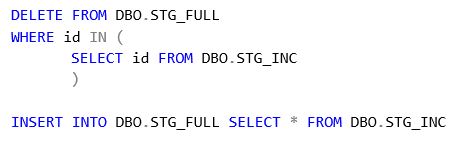
Finally, this stage table can be used for the downstream ETL.
Please contact me for any question and welcome any comments and suggestions.