 English | EN
English | EN EXPLAINABLE AI – TRANSFORMING AI INTO COMPETITIVE BUSINESS DIFFERENTIATOR
March 12, 2019

Introduction to XAI
Artificial intelligence (AI) is a transformational $15 trillion opportunity. Today AI is becoming more sophisticated, decisions of machine or action thereby have a far-reaching impact on individual, society, or government. However, decision making is being performed by an algorithmic ‘black box’. Today’s AL/ML models are mostly opaque, non-intuitive and difficult for people to understand and therefore suffer through key issues like trustworthiness, reliability, rationality, and transparency of models. To have confidence in the outcomes, cement stakeholder trust and ultimately capitalise on the opportunities, it is quite necessary to know the rationale of how the algorithm arrived at its recommendation or decision.
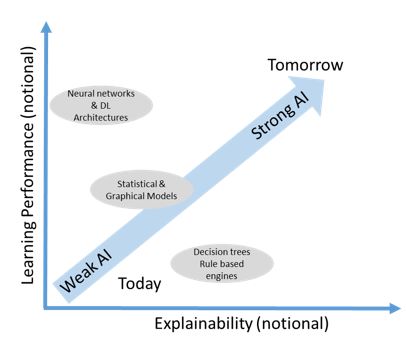
Frequently present AI solutions are centric around decision trees and rule-based engines, statistical & graphical models, and ANN and DL architectures. These exhibit variational learning performance however highly constrained explainability. Many of these techniques lack in incidental questions related to why/when/how. Resolving these queries requires Interactive ML, Visual Analytics, QA dialogues through AI/ML-Human-Computer interaction generating a desired explanation for the end user – these are explainable intelligent systems.
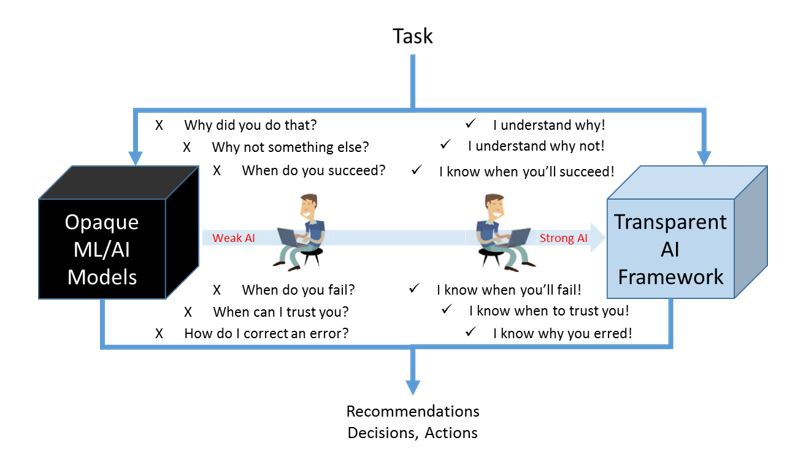
The research for explainable intelligent systems dates back to 1985. However, its generalization, standardization, and industrialization is still unexplored and large potential for research exist there. Steps towards this ask for more fundamental questions like what is explainability and why do we need it. Without loss of generality in context with XAI, we can define interpretability or explainability as the ability to explain or to present rationale in understandable terms to a human. More complex is the fundamental need of explainability. Restricted to XAI, the need of explainability for a strong AI mainly comes from three aspects: humans’ curiosity about knowledge, limitations of current intelligent algorithms, and moral and legal issues.
A. Curiosity
Hunger for knowledge is a part of natural instinct. More and more curiosity gains larger levels of knowledge building higher levels of intelligence thereby enhancing the fitness for survival. Context to AI, two immediate benefits can be noted from insights learned from the behaviour of an AI system. First, these insights can lead to improvement on the design of AI system itself. Secondly, human beings can become more intelligent from these insights. Good example could be understanding the strategy followed for executing the moves by IBM’s Deep Blue in defeating world champion chess game helping humans to master the game.
B. Limitations of machines
The current state-of-the-art intelligent systems, being black box, are usually not fully testable and expert knowledge is required as a complement in case the machines fail. In near future, machines are expected to assist rather than replace humans in many domains. Potential examples could be security, medical services, education, and design. By providing explainability, users’ trust can be more easily established. Besides, explainability can provide an interface for humans to monitor machine.
C. Moral and legal issues
Seeking explanations for certain recommendations/decisions generated by machines is becoming more logical considering anthropological and philosophical base. Possible illustrations are –
- If one’s application for a loan is denied by an automatic classifier, he/she has the right to ask why.
- A doctor may need to know why a patient is classified to have lung cancer to give the final diagnosis.
Philosophical architecture satisfying the needs discussed is expected to be a general framework independent of the algorithmic nature of the AI/ML models. This essentially points for mutually complimenting roles for AI and human expertise resulting in justified and controlled decisions.
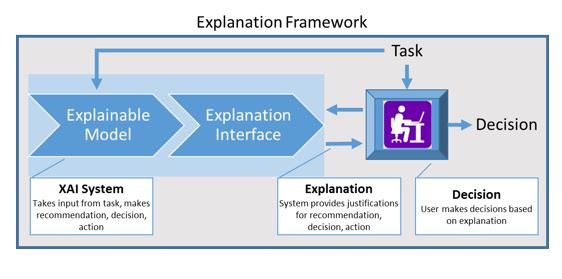
Most importantly, the “right to explanation” is a regulation included in the GDPR (General Data Protection Regulation) of the European Union effective from 2018. It is still debatable on to which extent we should require automatic decision-making systems to provide explanations to the subjects of the decision. Another issue is the fairness or the discrimination problem of automated decisions, which may be easily neglected during the development phase. Such facts highlight the high priority need of AXI framework.
Though explainability is a desirable property, it may not be always necessary. An inability to explain the rationale behind decisions is acceptable when the impacts of AI decisions are relatively trivial. It may not be required, for example, if –
- Application domain has high resistance to errors, and thus, unexpected errors are acceptable
- Application domain has been well studied and the machine results have been well tested in production, and thus, it is unlikely to have unexpected results.
Challenges for XAI
A. Visualization challenges
Majority of the knowledge capturing process, hints for analysis, etc. comes through the process of visualization. Therefore establishing the visual aids for AI systems to generate the explanations and justifications for the outcomes is the prime need. The main challenge of visually explaining machine results comes from the complexity of the model and data, and the natural constraints of humans cognitive. It is challenging to explain complex ML models both concisely and precisely. For example, a convolutional network typically employs thousands of neurons and millions of parameters in multilayer architecture. Therefore it becomes most difficult to understand and interpret the analytics generated at each layer or node. Another example can be a random forest which may employ hundreds of decision trees, each containing hundreds of nodes. Though single decision tree features maximum explainability, ‘explaining’ the forest is highly complex. A more simplistic approach could be sampling a small number of parameters/ neurons/nodes to explain which might be easier to understand for humans, but it brings with it the risk of misunderstanding as well. The variety of model architectures also increases the difficulty of designing an effective and general framework for explaining machine decisions
B. Data Challenges
Obvious challenge with data based knowledge system is the volume and variety of the data used for building the knowledge and therefore intelligence. To ‘explain’, an intuitive path is to trace back to the input data with an objective to find ‘which part of the input data contributes to the result’ and thus highly complex for multivariate decisions with tremendous data. Alternatively, we can attempt to analyse how a model behaves on a subset of data. Some explanation methods require computations over the entire data set, which may become impractical if the data set is very large. Secondly, different data types may require different forms of visual explanation. Image data are readily interpretable, but how to effectively explain models on categorical, text and speech data is still a problem.
C. Cognitive Abilities
Important to note that these challenges are, to some extent, due to compromises owing to the limits of humans’ cognitive ability. If humans can make sense of the meaning of thousands of parameters and complex model structures by merely looking at the raw data or program structure, there is no need to struggle with how to better visualize it. Studies discussing the structure, function, and effectiveness of explanations in cognitive science are already on the research front. And this underlines the need of switching back to basics to understand more about components of Cognitive Science – Philosophy, Psychology, Anthropology, Linguistics, followed by Neuroscience.
Summary
As AI expands into areas with major impacts on humans, like medical diagnosis, the military, recruitment decisions and policing, it becomes increasingly vital for AI to ‘explain’ why it has reached a particular decision. Such XAI demands developing methodologies for making existing opaque AI systems to transparent AI frameworks which can provide explanations to the decisions and recommendations generated.
To achieve the explainability characteristics for intelligent machines, we need to work on detailing a few basic requirements like –
- Way to effectively evaluate the quality of an explanation
- Insights on the load that its visual representations exert over humans
- The possibility of breaking very features of the algorithm due to visualization taps
- Overheads added by ‘explanation’ engine on intelligent machines
- Opening AI black box is difficult and may not always be essential. Any guidelines when we lift the lid?
Now it’s a time to focus on XAI for at least three reasons. The first is the growing demand for transparency in AI decisions. Second is the need to build trust in AI, since people must trust the choices made by AI for those choices to be truly useful. And the third driver is the opportunity for closer and more productive human-machine synergies in the future, with AI and humans each augmenting the capabilities of the other.
This is the starting discussion. Stay tuned here for more details on the basic requirements listed for XAI.
References
- A survey on visualization for explainable classifiers, Yao Ming, Department of Computer Science and Engineering The Hong Kong University of Science and Technology, October 2017, Hong Kong.
- Understanding Machines: Explainable AI, Accenture Labs
- Explainable AI, David Silverman, Imperial College, London, October 2018, imperial.ac.uk/artificial-intelligence
- Explainable Artificial Intelligence (XAI), David Gunning, DARPA/I20, Nov 2017
- Explainable Artificial Intelligence: A Survey, Filip Karlo Došilović et. Al., https://www.researchgate.net/publication/325398586
- Explainable AI, Manojkumar Parmar, https://www.researchgate.net/publication/327754673
About the author