 English | EN
English | EN EARCHIVING APPLICATIONS
June 24, 2019


To and from during my career the subject of archiving applications that have been replaced are popping up. Usually, there have been few solutions to the issue.
- Create a data model and migrate the valuable data into it
- Keep the old application with its data, with a small set of user licenses
Probably there were
also dedicated solutions, but they never came across me.
Since last year the question has been raised more often, which is natural as a large number of applications that were built in the late 90:ies and early 00:ies now are reaching the end of life.
I remember a dialogue
a few years ago when a group of public health care organizations were running a
common project for archiving of old medical records systems. At that time, they
had spent two years of work trying to define a common data model to migrate the
different medical records system data in to.
Lately, the question popped again from a client that was asking for an eArchiving solution.
With the knowledge
from my actual assignment I now can announce:
It is easy! Too easy to be true!
So, what is the
solution?
It is an Information Management platform consisting of a DataLake, a traditional Database, and a reporting tool.
Everything can be implemented in the cloud, which will be very cost efficient as the data traffic will be low. (If it turns out to be high, it is not an archive)
The picture below
shows the architecture of a potential eArchiving platform.
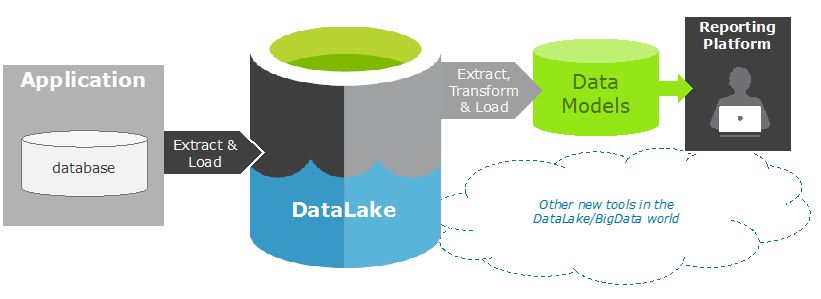
Stepwise the procedure
is:
- Define what data shall be archived. Usually, there are a lot of system data tables that can be left out.
- Create a procedure that Extracts the selected data and stores it into the DataLake. The data is stored in its original structure.
At this stage you
actually have archived your data.
To secure that all relevant
data has been archived it is a good idea to design and implement a set of
reports based on the archived data.
These reports are
normally based on traditional use cases.
- Design
reports - Design a
data model to support the reports. Don’t think that you shall try to create one
data warehouse, focus on each report need and realize it. - Build an
ETL procedure to populate the data model(s) with data from the Datalake
eArchive. - Build the
reports
Then continue to
design and build reports as demands show up.
The example above is
an easy to understand solution based on tools and platform components known to
many. There are a new set of tools around the DataLake technology that also can
be used. I intentionally left them out here.
It is easy! Too easy to be true!
I have to repeat it.
How much work do you
think it is?
I have in my project at the moment moved in 15 applications into a DataLake. We have built a Data Warehouse upon it and then realized more than 10 BI domains.
With my knowledge, I can say that it is less than a week’s work to set up the complete flow from the application to be archived to a set of basic reports. Of course, we are not talking about advanced reports, just basic ones that help people to search for data in the archive and produce output.
In my case we have
used 100% Microsoft Azure, which means:
- Azure Data
Lake - Azure Data
Factory - Azure SQL
- Power BI
Aren’t there any
drawbacks in my work so far?
Yes, of course, but I
can tell you what you might face, which may drive to more than a week’s work.
- Many standard applications have a very complex structure and a lot of data tables for system purposes.
- It can be hard to identify the valuable content for the load to DataLake! You can load everything, but the problem will hit you later anyway. Try to select from the beginning.
- There are standard applications that don’t use the relations in the relational database. The relations are made in the code.
- It can be hard to understand the structure of the data that has been loaded in the DataLake, which in turn makes it hard to implement the reports.
- The relation between data objects and tables has to be re-created in the data model.
- Even if it’s an old application to be archived, it can be hard to get the right authorization for Extract and Load all data to the DataLake.
- Many standard applications have different terminology in User Interface and Data model.
- This can make it hard to identify the right data, as the users we consult only know the UI terminology, and we work with data model terminology.
- There are of course applications that have very large amounts of data.
- The load time will be longer, which shouldn’t be an issue for a one-time load.
- The reporting requires smarter data structure and flow structure to be able to provide acceptable response times, which of course takes more time to achieve.
I am still happy to
say that it is still less than two weeks work.
There is no reason
not to take on the application archiving anymore.
Just do it!
Good Luck!
About the author