 English | EN
English | EN 
The root of delivering good products is in how you handle your code base, as any team will concur. For this reason, teams can spend a lot of time choosing what works best for them, often formed by opinionated discussions. Over the years I’ve seen many of these, as well as articles describing the optimal way to deal with branching. The truth is, there is no single answer that can satisfy all use cases, so I will try to give you a hand and set up a DIY kit for branching based on your situation.
Now there are different generation of versioning systems which each had their merit:
- In systems like CVS that versioned files, a tag would be a combination of files with their versions, leading to complex management.
I’ve not come across this in the last fifteen years. - Repository-based version numbering, like Subversion and TFVC. Here the complete repository gets an auto-incremented version number and contains everything. A branch is a separate folder, and any change anywhere results in an update. They work client-server, where you need a connection, and you lock whatever you work on.
These systems typically work with some fixed branches for specific purposes like environments, since all automation had to be linked to folders in the repository. For this reason, they work quite well in Waterfall projects. - Distributed versioning systems, let’s just say Git. These are designed to work decentralized; all changes are made by branching and then merging when you’re done. Changesets each have a unique ID and are chained as a branch.
An interesting aspect is that branches are not folders, a workspace is typically one branch that you can switch. Since this leads to the same folder independent of the branch, it works much easier for doing Agile development, hence its popularity.
For this article, I will focus on Git.
The base
Starting to build your branching strategy, it’s important to have a base. This is your golden source, the one place of truth, and you should want it to be stable. This also means any new changeset should not break your product.
Typically this is called Main, you are free to give your truth a different name but know it can be confusing, especially when team members change. As an example, we’re here:

Making changes
You wouldn’t be in a team if you didn’t make any changes. Of course, you can do it directly on Main, but the chance of accidentally breaking something is high. A change can be a new feature, a bugfix, a hotfix, a patch, a setting change, some documentation, basically anything. Consensus has been reached that these are done through feature branches and having them merged back through pull requests. Now here you have a number of options:
- Naming convention: it’s good practice to start with a prefix, typically feature/. Of course, it’s not mandatory and you’re allowed to use any name.
- Testing: will you include a successful test as a prerequisite to merge the result back to Main. It is advisable, since you want to know it works before you put it in your stable source.
- Review: how is the review done, when does your team think it’s good enough. These are degrees of freedom.
- Merging strategy: will you merge all changesets into the Main branch, or do you squash them into one new changeset. The advantage of squashing is that after a long time you can see what feature or bug led to a change, rather than going through a list of mixed details.
These criteria should be described together with any other criteria in some Definition of Done, as is often seen in Agile. You typically want it to be done before going into your stable source.
If you make your pull request such that:
- one work item must be linked – typically a story, bug or incident
- tester and reviewer must approve
- squash changes into a single changeset
that will lead to a very readable branch that can also be offered to an auditor should that be a requirement.
It can now look like this:
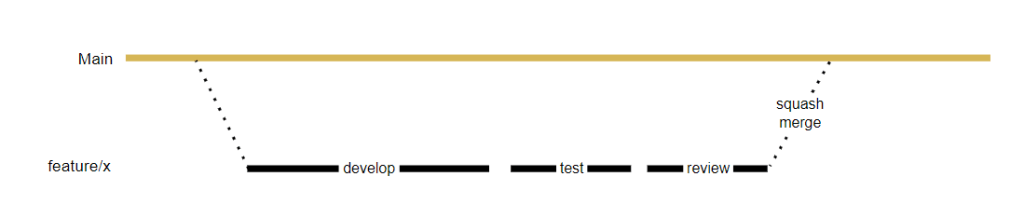
The DevOps mindset
In an ideal world, you now have your golden source, you know it’s stable, and there is trust, so you can push it to production. That would mean we’re done now, and any update goes to production, typically multiple times per day.
This is the idea behind trunk-based development and the DevOps mindset. It’s the ideal we strive for, but you need a few things for this:
- Trust from the client. If there’s no trust that this works, it won’t work. Also, trust can’t be forced, it must be earned, and always starts with two-way open communication.
- Automation. If you want this to happen multiple times per day, it must be automated. That includes the build, unit tests, integration tests, deployment, and monitoring.
- Feature toggles. These make sure that you decouple enabling a feature from the moment it’s deployed. It allows you to gradually enable, do A/B testing, set a date, can disable something when it breaks.
- Design for failure. When you deploy a monolith, your application is down at every deployment, leading to customer frustration. Break up your application, look at hot reload, build in circuit breakers or retries, design your landscape to be asynchronous.
Acceptance
If you’re in the situation that someone needs to accept your work, this process should be reflected in your branching. After all, you have your golden source, anything coming after that should be considered a bug or rework on that golden source.
There are two main ways to look at this step:
- There are two copies of that same golden source: one that you trust and one that the customer trusts. Each time it’s accepted, they are identical once again. We can do this easiest using pull requests that do a basic merge, to maintain a 1-1 relation between them.
- You release software from the golden source, and the resulting release is deployed to acceptance before production. When in acceptance some finding comes out, that software release is rejected and not deployed to production. Then it can be decided whether to wait for the next release or to deliver a hotfix also to acceptance.
Option A) will add the following part to your branching strategy:

For option B) look at the Release and Hotfix sections.
Release
A release branch is typically used when you want the option to make a hotfix independent of any new functionality. This is typically the scenario where there are fixed release moments that take a while – anywhere between two weeks to a year between. Here also there are two flavors prevalent:
A) One release branch that is updated on each release. This can work when the release branch is going as soon as possible to production, since in the time between branch update and the software being live on production you can’t do a hotfix.
In this scenario it’s common to tag each version with a proper version number, so you know which is which.
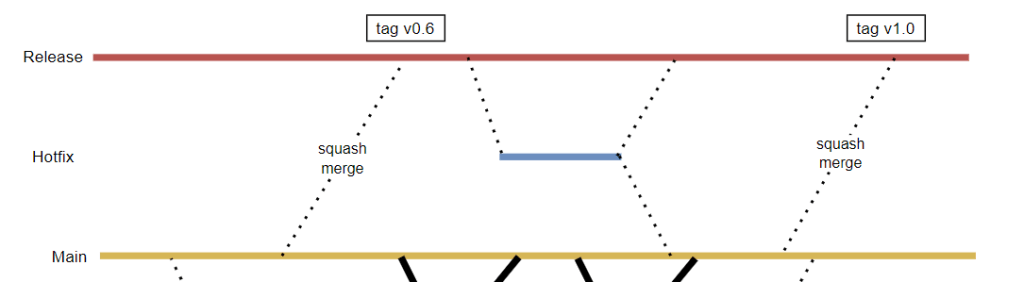
B) Each version gets its own release branch. The benefit is that different releases don’t interfere, you can easily do a hotfix and apply it also to your golden source. It’s typically applicable when you get longer time in between with different acceptance stages, or when going to production has an intricate process.
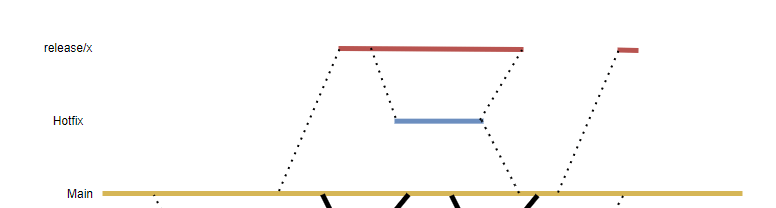
*Gitflow has a typical design that contains these aspects, but despite its popularity combines both downsides of both strategies. This particular flow applies when the team can afford to get dedicated test- and release time, during which no development is done, and works toward one fix new production version. This typically applies to earlier waterfall release processes where the software is handed over to the test team instead of where testing is done in the team itself.
Hotfix
A hotfix is typically a fix on the live system, so you need to do it on the code that’s on the live system at that moment. This means it’s split off from that source:
- In trunk-based development, the Main is also the code deployed on production, so a hotfix is implemented like any feature.
- When you have a release branch, a hotfix is split off from the release branch and after implementation merged back. Next to this, it’s also merged back to the Main branch.
- Should you have a separate branch for the acceptance, the hotfix shouldn’t go back there. Any update on the acceptance branch should go through the acceptance process, so it will get there with the new accepted product.
Final notes
Setting up branching strategies is not trivial, and there are many ways to do it. Make sure that they’re based on the process at hand and make sense. But most of all, only make branches that you need, since with every step you add complexity.
Merging code back through the chain to get them back in sync can seem like a very flexible solution, where you can develop from both sides and sync afterwards. In practice however, this way you ensure there is no golden source, no base, and the potential to get mixed up with changesets. Before you know it, you’re spending all your time getting things back together rather than on adding value.
Everyone has their favorite git command, git tool and git process. Make sure to align with the team how to work and be compatible. It can get ugly very fast when you don’t align on the details. And after all, we’re not all equally good at git internals.
It could be that you will need more than one strategy, and this is fine. A common example is one library that maintains a package library, and another that holds an application. They have different needs.