 English | EN
English | EN 
Introduction
Disaster recovery strategies can be broadly categorized into four approaches, ranging from the low cost and low complexity of making backups to more complex strategies using multiple active Regions. Active/passive strategies use an active site (such as an AWS Region) to host the workload and serve traffic. The passive site (such as a different AWS Region) is used for recovery. The passive site does not actively serve traffic until a failover event is triggered.
It is critical to regularly assess and test your disaster recovery strategy so that you have confidence in invoking it, should it become necessary.
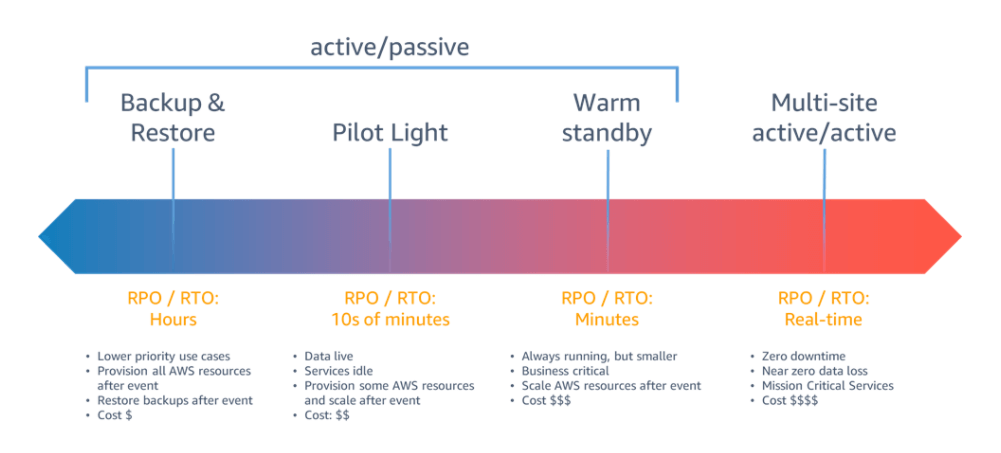
For a disaster event based on disruption or loss of one physical data center for a well-architected, highly available workload, you may only require a backup and restore approach to disaster recovery. If your definition of a disaster goes beyond the disruption or loss of a physical data center to that of a Region or if you are subject to regulatory requirements that require it, then you should consider Pilot Light, Warm Standby, or Multi-Site Active/Active.
Disaster Recovery Pattern for Rest API Serverless APPs
This article describes setting up a Disaster Recovery of serverless Application that uses services like API GW and Lambda.
Application Architecture Design
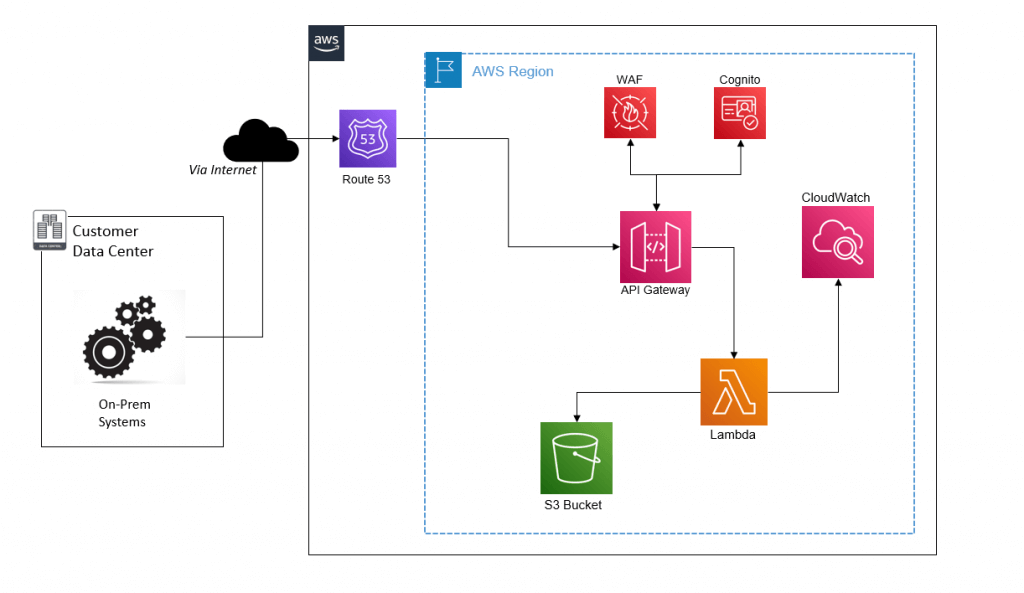
Below is a to be architecture of the Application. The main services that are used are:
API GW: App uses Rest API Regional API GW service which acts as a front door to access the backend lambda service to perform complex business logic.
Custom domain is configured on the API GW.
Lambda: This is a serverless PAAS service that supports multiple Run times such as DOTNET code, Lambda, NodeJS etc. The lambda function does not require any VPC to be configured in our use case.
For Lambda to make making external API calls and for destinations to whitelist source Ips, Lambda functions must be configured within the VPC, and NAT Ips can be used to whitelist on destination systems.
Cognito: Cognito is used to authenticate API GWs using client credentials. This is typically to provide credentials to an application to authorize machine-to-machine requests.
S3 Bucket: S3 bucket is used to store the objects processed by Lambda. It uses KMS encryption to encrypt data at rest in the form of Customer-Managed Keys (CMK). This will be configured with bi-directional replication.
Route53: This is a DNS service used by API GW to deploy the hosted zone. The custom domain also uses secure SSL certificates provisioned by the ACM service.
CloudWatch: This is used to store all the logs from lambda functions. The application may use other supporting services like Secrets manager to store API Keys and Parameter stores to store all configuration data used by the Application.
Suppose a customer requests a Disaster Recovery solution for above application then how would that work?
Design Decision for DR
The serverless nature of the application allows for an active-active type of DR and still be cost-effective.
Below is the DR architecture for this application:
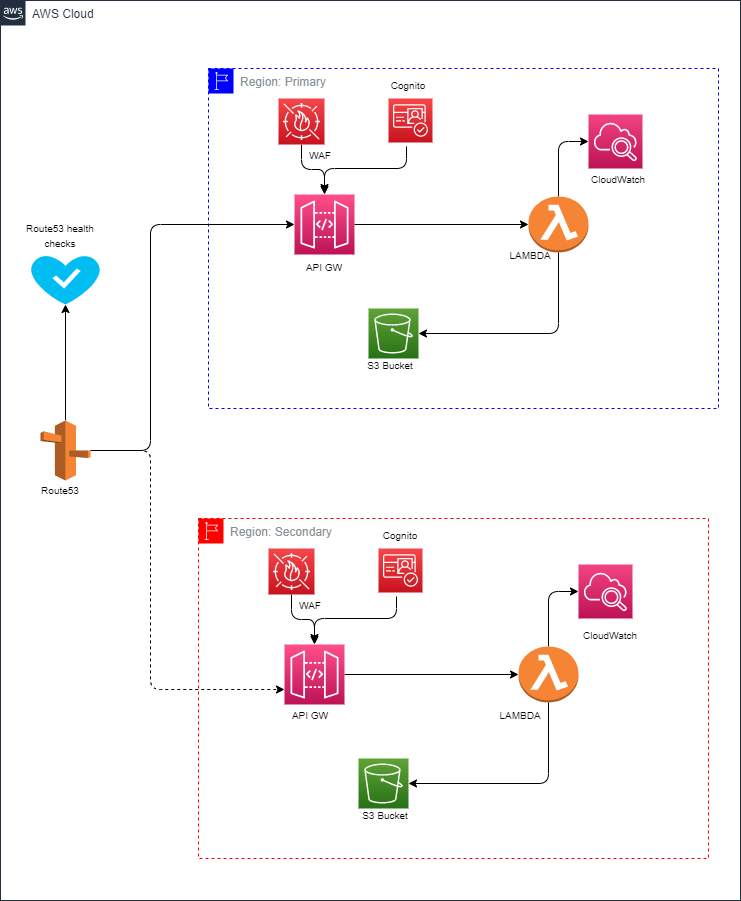
While designing the DR systems, it is important to identify and then categorize the AWS services into two broad subgroups: data-persistent services and codebased services.
Data Persistent services: These are mainly services like S3 bucket, EBS, EC2, RDS which must be deployed without any data loss.
Code-Based: These are mainly services like API GW, Lambda etc which do not store any sort of data and are mainly configurations-based services.
In our scenario, we also have a few global services like Route53 which cannot have a DR configured for it.
How will the architecture work in case of DR event?
• Route53 will be configured in failover mode which will continuously check the health of API GW.
• This can be accomplished by dropping a standalone API GW with lambda that displays static content.
• In case of DR event the health checks configured for both the API GWs will be responsible to switch the DNS to failover routing
• The primary record will have the custom domain endpoint of the API GW in primary region and the secondary record will have the custom domain endpoint of the API GW deployed in secondary region.
• If the primary region goes down, the health checks on the primary region would become un-healthy which would prompt route53 to send traffic to the secondary region.
• This will lead to the application failing back to secondary region.
Failback
The application also has a fully automatic failback mechanism.
As soon as the primary region is back online, the health checks configured on the primary API end would again become healthy which will prompt route53 to send traffic back to the primary region API Gw.
With S3 bucket configured with bi-directional replication there will not be any data loss as the data in the s3 bucket will be identical.