 English | EN
English | EN DELTA LAKE WITH AZURE SYNAPSE: UNLEASHING THE POWER OF DATA
October 9, 2023

Welcome to an extraordinary expedition into the convergence of Delta Lake and Azure Synapse. Prepare to embark on a captivating journey where the boundaries of data management and analytics are redefined. In this blog, we will delve into the depths of Delta Lake and Azure Synapse, unraveling their intricate workings and uncovering the vast potential they hold. Get ready to explore a world where data-driven endeavors flourish and possibilities are endless.
The Marvels of Delta Lake
Imagine a realm where data lakes thrive with unparalleled reliability, scalability, and performance enhancements. Enter Delta Lake, a groundbreaking open-source storage layer crafted by Databricks in 2019. Its mission? To revolutionize the way we interact with data. Delta Lake introduces a host of remarkable features, including ACID transactions, schema enforcement, and data versioning capabilities.
One of Delta Lake’s distinguishing characteristics is its robust transaction log, designed to handle massive datasets seamlessly. This log plays a pivotal role in ensuring data quality, reliability, and consistency within data lakes. With Delta Lake, structured and semi-structured data coexist harmoniously, empowering organizations to efficiently store and process a diverse range of data formats.
Unveiling the Architectural Wonders
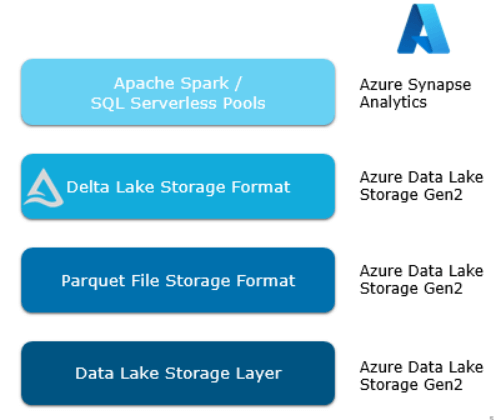
Within the Azure landscape, Delta Lake finds its home amidst the powerful storage layers. The journey begins with Data Lake Storage Gen 2 Layer, providing a solid foundation for data storage. As we ascend further, we encounter the remarkable Parquet file Storage Format, serving as the conduit for Delta Lake’s data storage capabilities.
But the true marvel lies in the crown jewel of this architectural ensemble: the Delta Lake storage format. To unlock its full potential within Azure Synapse, a combination of Delta Table libraries and Python codes is required. These tools enable seamless integration with Synapse, empowering data-driven transformations and computations.
In our exhilarating journey through Delta Lake and Azure Synapse, we have uncovered a plethora of features that define the remarkable capabilities of Delta Lake.
Let’s summarize these key pointers:
Fortified Protection: ACID Transactions (Atomicity, Consistency, Isolation, and Durability) serve as a robust fortress, safeguarding your data with the strongest level of isolation, ensuring its integrity and reliability.
Limitless Scalability: Delta Lake effortlessly handles Petabyte-scale tables with billions of partitions and files, providing a scalable metadata layer that empowers organizations to manage and process vast amounts of data seamlessly.
Time Travel Adventures: Unlock the power of time travel with Delta Lake’s ability to access and revert to earlier versions of data. This feature allows for audits, rollbacks, and the ability to reproduce results, enhancing data governance and decision-making.
Open Source Ecosystem: Delta Lake embraces an open-source philosophy, driven by community contributions, open standards, open protocols, and open discussions. This collaborative approach fosters innovation and empowers users to shape the future of Delta Lake.
Unified Batch and Streaming: Delta Lake bridges the gap between batch and streaming data processing, offering exactly once semantics for ingestion. This seamless integration enables smooth transitions from batch processing to interactive queries, enhancing data analytics capabilities.
Schema Evolution and Enforcement: Delta Lake ensures data integrity by providing schema evolution and enforcement capabilities. This feature prevents bad data from causing data corruption, ensuring the consistency and reliability of your data.
Comprehensive Audit Trail: Delta Lake logs all change details, creating a comprehensive audit history. This audit trail serves as a reliable reference for data governance, enabling accountability and transparency in data operations.
Flexible Data Manipulation: Delta Lake empowers users with SQL, Scala/Java, and Python APIs, allowing for seamless merging, updating, and deletion of datasets. These flexible data manipulation capabilities unlock the full potential of your data.
Business Intelligence Support: Delta Lake supports business intelligence (BI) initiatives, although it requires a specific connector to create Delta Lake tables for BI purposes. This connector acts as a gateway, enabling the utilization of Delta Lake’s rich capabilities in the realm of BI.
Delta Optimization
To improve query speed, Delta Lake offers optimization techniques for data layout:
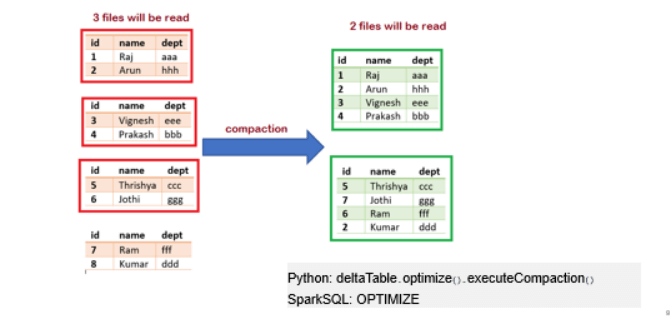
- Compaction: Delta Lake coalesces small files into larger ones, enhancing the speed of read queries and improving performance. This optimization, also known as bin-packing, aims to produce evenly-balanced data files in terms of their size on disk. Python and Scala APIs are available for executing the compaction operation.
- Data Skipping: Delta Lake automatically collects data skipping information when writing data into a table. At query time, Delta Lake leverages this information (minimum and maximum values for each column) to provide faster queries. Data skipping is activated whenever applicable and does not require manual configuration.

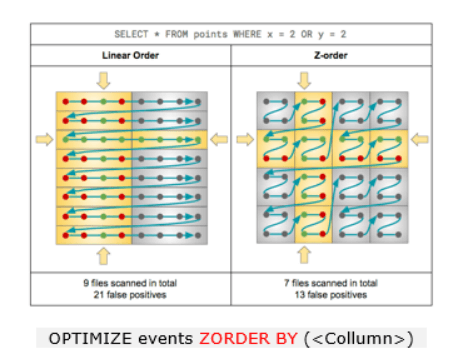
- Z-Order Clustering: Z-Ordering is a technique to co-locate related information in the same set of files. Delta Lake utilizes this co-locality in data-skipping algorithms, significantly reducing the amount of data that needs to be read, especially when applied to columns with high cardinality. Z-Ordering can be specified using the ZORDER BY clause, although adding too many columns may impact performance.
Using Delta Lake in Azure
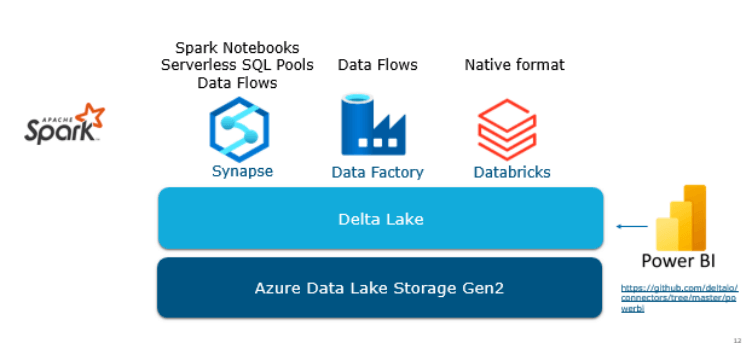
To leverage Delta Lake in Azure, you will need an Azure Storage account with hierarchical namespaces enabled, along with Azure resources based on Apache Spark clusters. In Synapse, you can create two types of tables in Spark:
- Managed Table: Defined without a specified location, the data files are stored within the data lake used by the metastore. Dropping the table removes its metadata from the catalog and deletes the folder containing the data files. Typically, the data is stored in a local Synapse Workspace folder on the data lake, ensuring availability while the table exists in Synapse.
- External Table: Defined for a custom file location, where the data for the table is stored. The metadata for the table is defined in the Spark catalog. Dropping the table deletes the metadata from the catalog but doesn’t affect the data files, making the data persistent.
Demo Time!
Let’s explore some exciting demos showcasing the capabilities of Delta Lake with Azure Synapse:
- Easy transformation to Delta format with ACID transactions.
- Convert normal Parquet file to a Delta Table (Time Stamp -> 24:20 – 29:20)
- Update 1 record (ACID) (Time Stamp -> 30:55 – 31:40)
- Delete 1 record • (Time Stamp -> 33:35 – 34:10)
- Version history • (Time Stamp -> 34:15 – 34:35)
- Time traveling by restoring the previous version (Time Stamp -> 34:36 – 35:23)
2: Showing polyglot capabilities of Synapse
- Create and query managed tables using SQL from a delta folder • (Time Stamp -> 38:58 – 39:55, 43:55 – 45:10, 45:25 – 46:20, 46:27 – 47:41)
- Using Z-ORDER Optimization (Time Stamp -> 49:00 – 57:25)
3: Demonstrate Polybase capabilities
- Query Lake Database table using a Serverless SQL pool (Time Stamp -> 57:28 – 1:00:00)
Best practices/takeaways
- Never change the parquet files outside the Delta Lake format.
- Use optimization techniques like data skipping and/or Z-ORDER, especially on datasets with high cardinality.
- Utilize OPTIMIZE or .repartition to compact smaller parquet files into larger files.
- Avoid using caching in Spark, as it may interfere with the optimization algorithm.
- Delete unused parquet files using the VACUUM command.
- Enforce and validate schema where possible to increase data quality.
- Note that Databricks Delta Lake is not always equal to Synapse Delta Lake; it is advisable to check roadmaps.
The Ultimate Conclusion to Simplifying Your Life!
In conclusion, Delta Lake with Azure Synapse presents a powerful combination for simplifying data management and analytics. By harnessing Delta Lake’s innovative features, robust architecture, and optimization techniques, organizations can unlock the full potential of their data, gaining valuable insights and achieving transformative business outcomes.
It’s time to embrace this powerful union and embark on a data-driven journey that will reshape the way you perceive and leverage your data. Explore the provided demos and take a step closer to revolutionizing your data ecosystem!
Import necessary packages
from delta.tables import * from pyspark.sql.functions import * from pyspark.sql.types import *
Define the schema of your table
schema = StructType([ StructField(“id”, IntegerType(), True), StructField(“name”, StringType(), True), StructField(“age”, IntegerType(), True) ])
Create a Delta Table with z-order optimization
data_path = “/mnt/delta/data” delta_table = DeltaTableBuilder
.forPath(spark, data_path)
.onSchema(schema)
.withZOrderBy([“id”])
.build()
Insert some data into the table
data = [(1, “John”, 25), (2, “Jane”, 30), (3, “Bob”, 40)] delta_table.alias(“t”).merge(spark.createDataFrame(data).alias(“s”), “t.id = s._1”).whenMatchedUpdate(set={“age”: col(“s._3”)}).execute()
Show the version history of the Delta Table
delta_table.history().show()
Play Time!
For a hands-on experience with Delta Lake, you can access the Delta Lake virtual lab at the following link: Delta Lake Virtual Lab.
Get ready to unlock the true potential of your data ecosystem with Delta Lake and Azure Synapse. Embrace the power of data and elevate your organization to new heights!
Stay tuned for more exciting updates and innovations in the world of Delta Lake and Azure Synapse. The future of data awaits!
About the author