 English | EN
English | EN REDUCE MAINTENANCE WORKLOAD BY 97% WITH CONTEXT-DRIVEN TEST AUTOMATION
December 12, 2018

The digital realm is multidimensional, and therefore not as easy to perceive as the physical world. This challenge is at the crux of the difficulties related to IT projects: How to determine when a delivery of a multidimensional project is of a satisfactory quality and ready for release?
You can easily observe if a newly constructed bridge only allows 9 out 10 cars to pass, or if it is made of sections that don’t completely align. Unfortunately, in digital projects, equivalent shortcomings are often passed as acceptable. A bridge is a tangible, three-dimensional construct, while digital constructs are not. How do you ensure the quality of a project with potentially infinite dimensions? How do you test it?
Test automation is the obvious solution to the accumulating workload in quality assurance of software projects. Fewer human errors, more coverage with fewer resources, and the ability to scale repetitive tasks are some of the well-known gains of automation. However, to really benefit from automation, it is necessary to reduce complexity along the way. This post presents context-driven automation as a solution for hiding unnecessary layers of complexity so that testers can focus their efforts where it makes the most sense.
The automation journey
Once QA teams have embraced automation and begun rolling it out, they often go through a predictable journey of learning. The phases of this journey will be described later but can be summarized as follows:
First, test cases are built one-by-one to replicate how testing was done manually. This is called linear, or 1:1, automation. Then, as the maintenance workload associated with the ever-growing number of standalone test cases grow out of control, there’s a realization that test automation must be done in a smarter way. This second phase of the automation journey is all about optimizing and reusing parts across multiple test cases. It usually involves plugging in data sources to automation flows to run data-driven automation. This exercise can significantly reduce maintenance workload, but it comes at the cost of paralyzing complexity.
Most test teams make it to the second level: They implement data-driven automation but are lost in the complexity, without knowing how to deal with it. The solution is context-driven automation, which is the final phase of the automation learning curve. Very few companies, like Amazon and Google, have reached this level of maturity in their automation efforts, but this shouldn’t discourage you! Keep reading for a chance to get familiarized with the concept of context-driven automation.
Phase 1: Linear automation
As mentioned above, automation roll-out usually begins with test teams gradually automating their test suite by building automated cases one by one. The automated tests are usually just replicas of manual test flows. This is a “parrot” approach to automation because manual processes are simply just repeated one-to-one without test automation engineers gaining a deeper understanding of the business processes under test.
Linear automation lacks the helicopter view of the system under test, and therefore this approach has some inherent limitations. An example from real life: A test team has built 1,600 standalone test cases (16 features to be tested, 100 tests per feature). Every single one of these requires continuous maintenance by testers, so the gains reaped from automation are at risk of being negated by the growing maintenance workload, especially when the product under test changes.
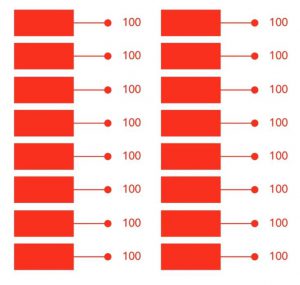
Figure 1:Linear automation. 1,600 standalone test cases (100 tests per feature), each of which requires continuous maintenance.
Phase 2: Data-driven automation and reusable test cases
Test case maintenance can be reduced to some extent by building components that can be reused across test cases. With the LEAPWORK Automation Platform, for example, any part of an automation flow can be turned into a “custom building block”, or sub-flow, to be reused in other flows. This obviously saves time when building automation flows.
Reusable components hide a layer of complexity from the tester building automated test cases. However, this simplification comes with the risk of creating a labyrinth structure of entangled references where there is more than one path to a given point. Some paths are dead-ends, others will go in circles. If a tester gets lost in a labyrinth structure, he or she quickly loses perspective and will begin wondering “Do I test what is most important? Do the test cases cover what is required? Can I even trust these test cases?”
Data-driven automation is about optimizing automated tests even more. Instead of having to build an automation flow for each test scenario, you feed flows with one or more data sources. As the flow is executed, it iterates through specified data entries from the source and goes through the same process for each entry.
Data-driven automation is an attempt at deconstructing the processes being tested to understand them better. This exercise usually reveals some common denominators, i.e. inputs of data, across the test cases.
By automating the use of data, e.g. connecting a spreadsheet to an automation flow, the 1,600 individual test cases from the example above are now “re-packaged”, and the same level of test coverage can now be achieved with just 200 data-driven test cases.
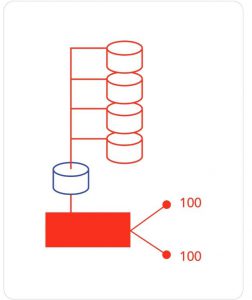
Figure 2:Data-driven automation. The 1,600 test cases are deconstructed, and the same level of test coverage can now be achieved with just 200 data-driven test cases.
Data-driven automation hides another layer of unnecessary complexity for the tester who no longer has to worry about the individual data entries but just needs to know how to plug data sources into his/her automation flows. At this stage, the amount of test cases is much more manageable for any test team, but the complexity is instead moved to the test data, where there are still several dimensions to navigate. A test dataset of 100+ parameters, the majority of which are either not used for each test case or spread across multiple data sources, is still incomprehensibly complex.
Phase 3: Context-driven automation
Context-driven automation takes simplification to the next level. It’s a way to hide complexity, for the tester to only focus on what is essential in a test case.
Context-driven automation relies on data-sources in which the interrelation between data is pre-configured in the source itself. This way, the relations do not have to be specified when building automation flows, which makes it much simpler to re-use components, e.g. sub-flows in LEAPWORK. On a theoretical level, context-driven automation reduces a multidimensional project to three dimensions or less making it much more manageable for the human tester.
In practice, context-driven automation is made possible by having engineers do all the technical pre-configuration of data sources and relations before these are used in automation flows. Complexity is split into layers, each of which takes care of a comprehensible part of the complexity. This way, flows are “reduced” to business processes per se. The pre-configuration includes any customizations required for testing your system in your organization—i.e. your context—meaning that a tester can build automation flows without having to take into consideration custom adaptations of the system under test.
As a result, entire test suites can be reduced to a few archetypes of flows that are contextual and compatible to changes in the surrounding context, e.g. test environment, data sources, system customization, multiple product versions, etc. To expand upon the previous example: The 200 data-driven automation cases can be further reduced to a few archetypes by moving contextual configurations from the cases themselves to an additional data source, as illustrated below.
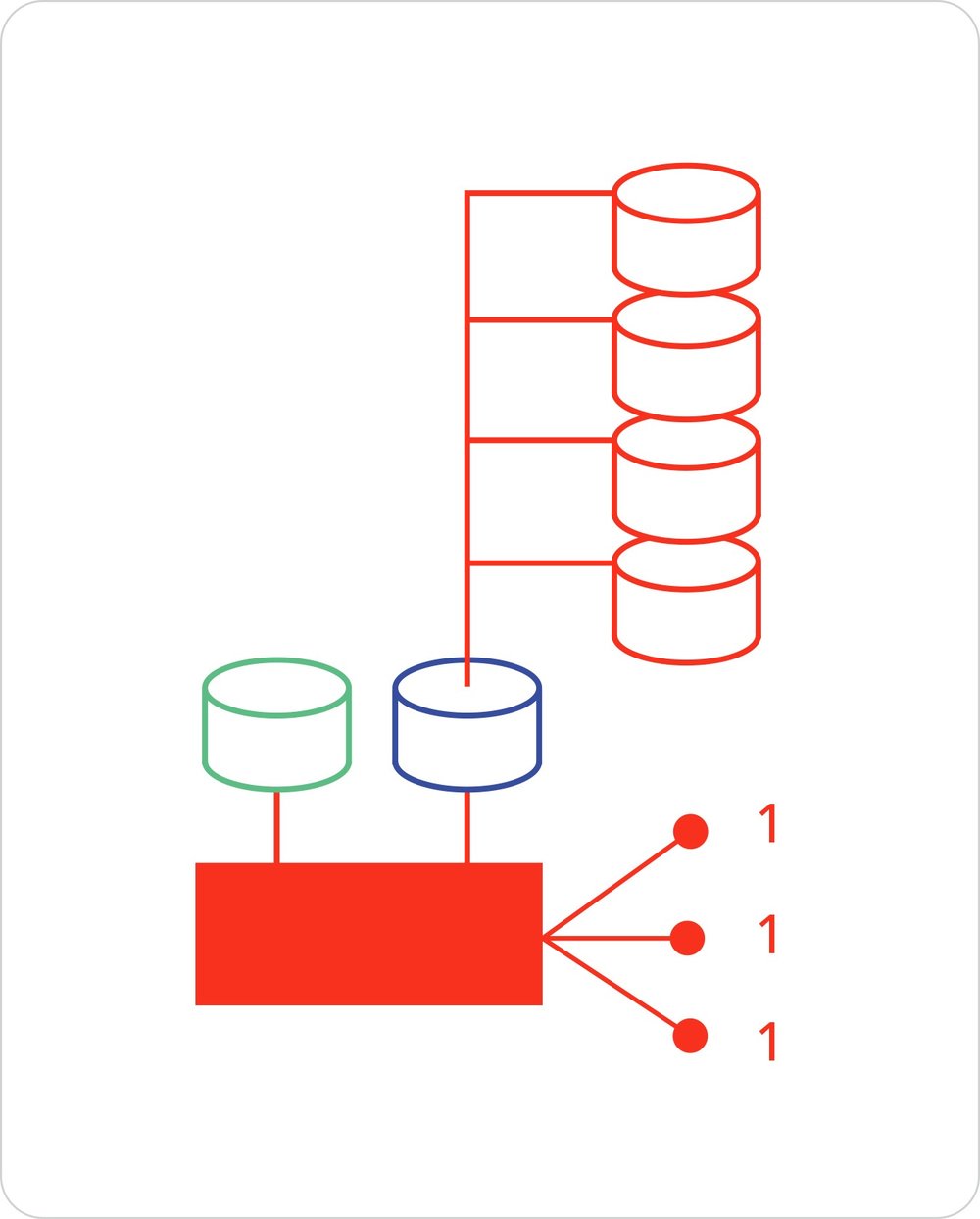
Figure 3: Context-driven automation. The 200 data-driven automation cases are reduced to a few archetypes by moving contextual configurations from the cases themselves to an additional data source.
The three archetypes illustrated in the figure above support several testing scenarios, involving multiple parameters. For example, a single archetype for a single business flow could support:
- 3 applications
- 4 web browsers
- 3 devices
Linear automation would require:
3x4x3 = 36 test cases to achieve the same level of test coverage
Data-driven automation could require, say, 30 parameters for this simple setup where 80% of the data would be redundant.
To sum up:
1 context-driven automation case = 36 test cases
All test cases, even when context-driven, requires maintenance but by reducing 36 cases to 1, you achieve:
97% reduction in maintenance workload
Imagine if a single business parameter is added with just two possible values, then the number of supported test cases would be doubled to 72 and the efficiency gain would then be 99%. It is not uncommon that multiple business parameters with multiple possible values are added, for example, to support multiple user roles, i.e. who is logged into the system under test. In such a case, the potential efficiency gain by utilizing context-driven automation to reduce maintenance workload would be >99,9%.
Keep complexity under the hood
The philosophy of context-driven automation is completely in line with that of LEAPWORK.
With the LEAPWORK Automation Platform, both non-developers, technical specialists, and business generalists can automate advanced, cross-functional tests and processes regardless of their technical proficiency. All layers of complexity are “under the hood” and users can build automation flows by connecting visual building blocks. Each block contains the hidden code that drives the automation engine, and they can be parameterized and pre-configured as needed, enabling context-driven automation.
Logically, this approach just makes sense. To illustrate:
- To drive a car, you don’t need to know all underlying processes taking place in the engine.
- To send an email to a colleague, you don’t want to spend time getting to know the systems that make it possible for the email to be sent and received.
Besides the obvious efficiency gains, context-driven test automation also lowers complexity so that testers can validate how a functionality works from the end-user perspective and not only verifying whether the functionality works or not.
In short, context-driven automation enables testers to better perform their primary task: To act as end-user ambassadors by continuously challenging the product under test, instead of spending time on navigating thousands of interrelated test cases and the frameworks around them.
A final note: One of the most exciting things about context-driven automation is that it is applicable to other automation scenarios than software testing, such as RPA (Robotics Process Automation). Context-driven automation hides layers of complexity and uncovers processes in their simplest form, and as such, it supports the argument that at their core, test automation and RPA are similar disciplines.
About the author