 English | EN
English | EN CHATGPT AND I HAVE TRUST ISSUES
March 30, 2023


Disclaimer: This blog was NOT written by ChatGPT, but by a group of human data scientists: Shahryar Masoumi, Wouter Zirkzee, Almira Pillay, Sven Hendrikx and myself.
Whether we are ready for it or not, we are currently in the era of generative AI, with the explosion of generative models such as DALL-e, GPT-3, and, notably, ChatGPT, which racked up one million users in one day. Recently, on March 14th, 2023, OpenAI released GPT-4, which caused quite a stir and thousands of people lining up to try it.
Generative AI can be used as a powerful resource to aid us in the most complex tasks. But like with any powerful innovation, there are some important questions to be asked… Can we really trust these AI models? How do we know if the data used in model training is representative, unbiased, and copyright safe? Are the safety constraints implemented robust enough? And most importantly, will AI replace the human workforce?
These are tough questions that we need to keep in mind and address. In this blog, we will focus on generative AI models, their trustworthiness, and how we can mitigate the risks that come with using them in a business setting.
Before we lay out our trust issues, let’s take a step back and explain what this new generative AI era means. Generative models are deep learning models that create new data. Their predecessors are Chatbots, VAE, GANs, and transformer-based NLP models, they hold an architecture that can fantasize about and create new data points based on the original data that was used to train them — and today, we can do this all based on just a text prompt!
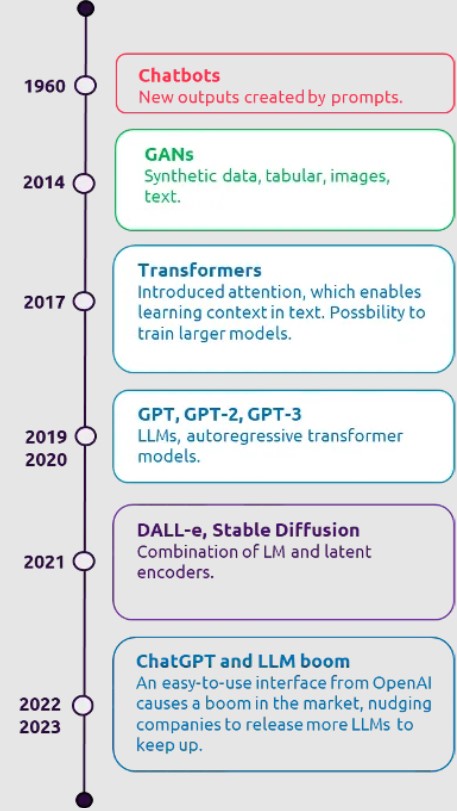
We can consider chatbots as the first generative models, but looking back we’ve come very far since then, with ChatGPT and DALL-e being easily accessible interfaces that everyone can use in their day-to-day. It is important to remember these are interfaces with generative pre-trained transformer (GPT) models under the hood.
The widespread accessibility of these two models has brought about a boom in the open-source community where we see more and more models being published, in the hopes of making the technology more user-friendly and enabling more robust implementations.
But let’s not get ahead of ourselves just yet — we will come back to this in our next blog. What’s that infamous Spiderman quote again?
With great power…
The generative AI era has so much potential in moving us closer to artificial general intelligence (AGI) because these models are trained on understanding language but can also perform on a wide variety of other tasks, that in some cases even exceed human capability. This makes them very powerful in many business applications.
Starting with the most common — text application, which is fueled by GPT and GAN models. Including everything from text generation to summarization and personalized content creation, these can be used in education, healthcare, marketing, and day-to-day life. The conversational application component of text application is used in chatbots and voice assistants.
Next, code-based applications are fueled by the same models, with GitHub’s Co-pilot as the most notable example. Here we can use generative AI to complete our code, review it, fix bugs, refactor, and write code comments and documentation.
On the topic of visual applications, we can use DALL-e, Stable Diffusion, and Midjourney. These models can be used to create new or improved visual material for marketing, education, and design. In the health sector, we can use these models for semantic translation, where semantic images are taken as input and a realistic visual output is generated. 3D shape generation with GANs is another interesting application in the video game industry. Finally, text-to-video editing with natural language is a novel and interesting application for the entertainment industry.
GANs and sequence-to-sequence automatic speech recognition (ASR) models (such as Whisper) are used in audio applications. Their text-to-speech application can be used in education and marketing. Speech-to-speech conversion and music generation have advantages for the entertainment and video game industry, such as game character voice generation.

Although powerful, such models also come with societal limitations and risks, which are crucial to address. For example, generative models are susceptible to unexplainable or faulty behavior, often because the data can have a variety of flaws, such as poor quality, bias, or just straight-up wrong information.
So, with great power indeed comes great responsibility… and a few trust issues
If we take a closer look at the risks regarding ethics and fairness in generative models, we can distinguish multiple categories of risk.
The first major risk is bias, which can occur in different settings. An example of bias is the use of stereotypes such as race, gender, or sexuality. This can lead to discrimination and unjust or oppressive answers generated from the model. Another form of bias is the model’s word choice. Its answers should be formulated without toxic or vulgar content, and slurs.
One example of a language model that learned a wrong bias is Tay, a Twitter bot developed by Microsoft in 2016. Tay was created to learn, by actively engaging with other Twitter users by answering, retweeting, or liking their posts. Through these interactions, the model swiftly learned wrong, racist, and unethical information, which it included in its own Twitter posts. This led to the shutdown of Tay, less than 24 hours after its initial release.
Large language models (LLMs) like ChatGPT generate the most relevant answer based on the constraints, but it is not always 100% correct and can contain false information. Currently, such models provide their answers written as confident statements, which can be misleading as they may not be correct. Such events where a model confidently makes inaccurate statements are also called hallucinations.
In 2023, Microsoft released a GPT-backed model to empower their Bing search engine with chat capabilities. However, there have already been multiple reports of undesirable behavior by this new service. It has threatened users with legal consequences or exposed their personal information. In another situation, it tried to convince a tech reporter he was not happily married and that he was in love with the chatbot (it also proclaimed their love for the reporter) and consequently should leave his wife (you see why we have trust issues now?!).
Generative models are trained on large corpora of data, which in many cases, is scraped from the internet. This data can contain private information, causing a privacy risk as it can unintentionally be learned and memorized by the model. This private data not only contain people, but also project documents, code bases, and works of art. When using medical models to diagnose a patient, it could also include private patient data. This also ties into copyright when this private memorized data is used in a generated output. For example, there have even been cases where image diffusion models have included slightly altered signatures or watermarks it has learned from their training set.
The public can also maliciously use generative models to harm/cheat others. This risk is linked with the other mentioned risks, except that it is intentional. Generative models can easily be used to create entirely new content with (purposefully) incorrect, private, or stolen information. Scarily, it doesn’t take much effort to flood the internet with maliciously generated content.
Building trust takes time…and tests
To mitigate these risks, we need to ensure the models are reliable and transparent through testing. Testing of AI models comes with some nuances when compared to testing of software, and they need to be addressed in an MLOps setting with data, model, and system tests.
These tests are captured in a test strategy at the very start of the project (problem formulation). In this early stage, it is important to capture key performance indicators (KPIs) to ensure a robust implementation. Next to that, assessing the impact of the model on the user and society is a crucial step in this phase. Based on the assessment, user subpopulation KPIs are collected and measured against, in addition to the performance KPIs.
An example of a subpopulation KPI is model accuracy on a specific user segment, which needs to be measured on data, model, and system levels. There are open-source packages that we can use to do this, like the AI Fairness 360 package.
Data testing can be used to address bias, privacy, and false information (consistency) trust issues. We make sure these are mitigated through exploratory data analysis (EDA), with assessments on bias, consistency, and toxicity of the data sources.
The data bias mitigation methods vary depending on the data used for training (images, text, audio, tabular), but they boil down to re-weighting the features of the minority group, oversampling the minority group, or under-sampling the majority group.
These changes need to be documented and reproducible, which is done with the help of data version control (DVC). DVC allows us to commit versions of data, parameters, and models in the same way “traditional” version control tools such as git do.
Model testing focuses on model performance metrics, which are assessed through training iterations with validated training data from previous tests. These need to be reproducible and saved with model versions. We can support this through open MLOPs packages like MLFlow.
Next, model robustness tests like metamorphic and adversarial tests should be implemented. These tests help assess if the model performs well on independent test scenarios. The usability of the model is assessed through user acceptance tests (UAT). Lags in the pipeline, false information, and interpretability of the prediction are measured on this level.
In terms of ChatGPT, a UAT could be constructed around assessing if the answer to the prompt is according to the user’s expectation. In addition, the explainability aspect is added — does the model provide sources used to generate the expected response?
System testing is extremely important to mitigate malicious use and false information risks. Malicious use needs to be assessed in the first phase and system tests are constructed based on that. Constraints in the model are then programmed.
OpenAI is aware of possible malicious uses of ChatGPT and have incorporated safety as part of their strategy. They have described how they try to mitigate some of these risks and limitations. In a system test, these constraints are validated on real-life scenarios, as opposed to controlled environments used in previous tests.
Let’s not forget about model and data drift. These are monitored, and retraining mechanisms can be set up to ensure the model stays relevant over time. Finally, the human-in-the-loop (HIL) method is also used to provide feedback to an online model.
ChatGPT and Bard (Google’s chatbot) have the possibility of human feedback through a thumbs up/down. Though simple, this feedback is used to effectively retrain and align the underlying models to users’ expectations, providing more relevant feedback in future iterations.
To trust or not to trust?
Just like the internet, truth and facts are not always given — and we’ve seen (and will continue to see) instances where ChatGPT and other generative AI models get it wrong. While it is a powerful tool, and we completely understand the hype, there will always be some risk. It should be standard practice to implement risk and quality control techniques to minimize the risks as much as possible. And we do see this happening in practice — OpenAI has been transparent about the limitations of their models, how they have tested them, and the governance that has been set up. Google also has responsible AI principles that they have abided by when developing Bard. As both organizations release new and improved models — they also advance their testing controls to continuously improve quality, safety, and user-friendliness.
Perhaps we can argue that using generative AI models like ChatGPT doesn’t necessarily leave us vulnerable to misinformation, but more familiar with how AI works and its limitations. Overall, the future of generative AI is bright and will continue to revolutionize the industry if we can trust it. And as we know, trust is an ongoing process…
In the next part of our Trustworthy Generative AI series, we will explore testing LLMs (bring your techie hat) and how quality LLM solutions lead to trust, which in turn, will increase adoption among businesses and the public.
About the author