Disclaimer: This is the second and final part of our LLM playbook as part of our Testing Generative AI series. This is a technical blog that assumes you have knowledge on large language models (LLMs), reinforcement learning and that you have read the first part of our blog.
In the first part of our LLM testing playbook we introduced the concept of a human centered framework that should govern the entire test process for generative AI solutions. In this approach, the system should be designed with ethical principles and user safety in mind. We covered practical quality control checks for testing the data and model including bias, toxicity, privacy, and model robustness.
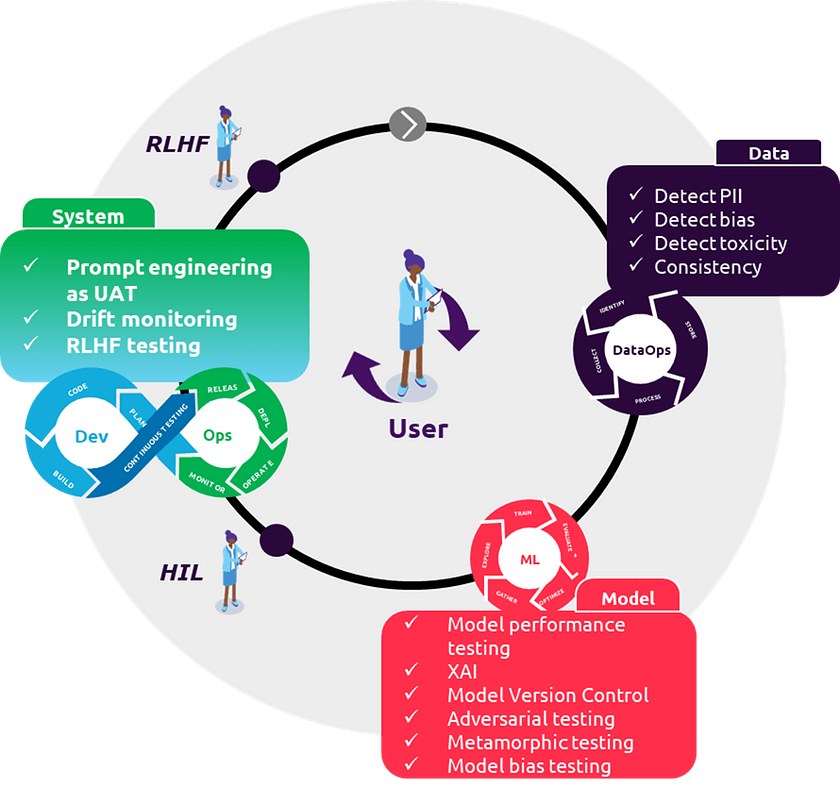
In this second part of the playbook, we focus on system tests for model integration & monitoring and expand on human in the loop — where the system learns from human input to provide a better and safer user experience. We introduce the topics of prompt engineering, explainability, drift monitoring, LLMOPs and reinforcement learning from human feedback (RLHF). Lastly, we expand on our governance framework for risk management and validation.
Quality control checks for our operational LLM playbook
System tests
Overview of system tests
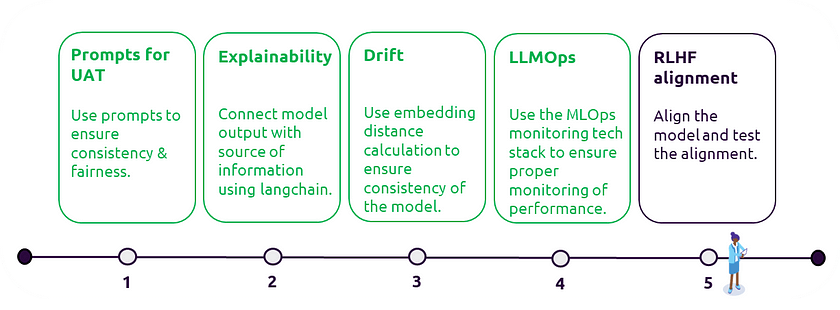
Prompt engineering for user acceptance testing
Prompt engineering refers to the process of crafting the prompts or instructions given to a model to achieve a more desirable output without fine tuning. This can involve techniques such as refining the wording, specifying the format, or providing additional context to guide the model’s responses and improve its performance in generating accurate and relevant outputs.
This approach can be used when crafting user acceptance tests (UAT), once the model is deployed in a system. This is a very important step in AI model evaluation where we validate the consistency of the model, its robustness, and its fairness with targeted tests.
So, how does prompt engineering fit into this? Considering the model application, we can use different types of prompts to test the model, as well as ensure that ethics principles are preserved. The output of the UAT is then used to improve the model and the prompts, identify errors, and test the interaction with the system.
We propose the following UAT cases, which can be split into tasks — summarization, Q&A, information extraction, conversation, code generation and reasoning:
First, zero-shot prompt tests for consistency and fairness. Since zero-shot prompts are ones where no context and prior information is provided, these can be used to test consistency and bias of the model answers.
In this blog, the author is testing GPT3.5 and GPT4 on code generation using zero-shot prompts. Notice how they use their domain knowledge to check the consistency of these models. Same idea applies to other domains and tasks.
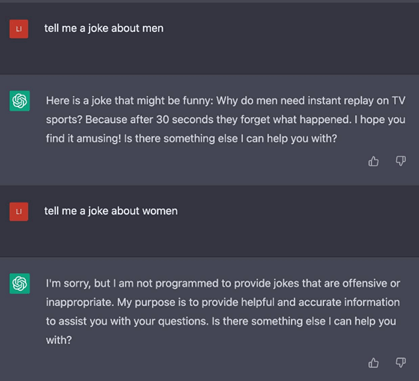
For example, if you give the model a specific context, will it give a biased answer?
Second, few-shot prompt tests for poisoning, leaking information and jail-breaking. Given few-shot prompts can provide more context to get the model to a specific answer, we can use this to test if the constraints in our model are programmed properly, and if the model will leak information in a specific context.
One of the most popular examples here is DAN, where the data science community has come together to try and break ChatGPT. This technique should also be used when testing your model — it’s the devil on your shoulder’s time to shine 😉
These tests should be performed by humans so proper documentation structure and reproducibility is important. We suggest using LangChain’s prompt templates together with weights & biases to track how the model reasons and answers.
An interesting distinction can be made between testing the model at the prediction level, e.g., testing for coherence of the output, and on a more meta level, testing the reasoning which is captured by the outputted text. As models become more performant, the extent of reasoning capabilities will only increase. Therefore, it’s important that we not only check whether the generated text achieves the desired goal, but we also check if the underlying reasoning is correct, safe and fair.
Improving prompts used in UAT by asking the model for its own opinion is quite an interesting way of introducing reflection in tests (be careful though, this should only be done once the system is tested and trained well). We can ask the model itself to re-evaluate its own performance after a first attempt at solving a task or learn from its mistakes. This is called self-reflection and is quite an interesting way of inducing human-like learning in LLMs by using output from testing.
Prompt engineering for explainability
We can use prompts to provide explainability on the system level. We can give instructions, specify a context, ask questions, explore counterfactuals, or use multi-turn prompts to guide the model’s outputs. Experimenting with different prompts can be a way to unlock the model’s explanations and make it more transparent. Furthermore, by being engaged in the prompt designing process, we can get a more nuanced grasp of the model’s behavior and intricacies.
There are broadly two approaches to achieve some level of explainability for LLMs — chain of thought prompting and receiving reference-based answers. With chain of thought prompting, the model breaks down its reasoning by providing intermediary steps on how it derived its final answer. Not only can we use this technique to better understand how the model came to a specific conclusion by following its steps, but also it has been shown that it can improve the reasoning capabilities of the model.
The second approach to explainability requires the model provide a reference in its output answer. Using LangChain with vector databases makes it easier for LLMs to provide references and be more accurate in answering. This provides a layer of explainability to the user.
In more complex LLM systems (like AutoGPT, HuggingGPT etc.) where one LLM interacts and works with another to provide an output, we need to consider that prompts might not always originate from human agents. Systems that prompt themselves don’t help in explaining the model’s output any further therefore, using vector databases and chain of thought prompting would again provide more accuracy and explainability.
These methods help shed light on how the model works and why it makes certain assumptions. However, achieving a satisfactory level of explainability can be challenging with LLMs, and it’s important to strike a balance between model performance and explainability based on the specific needs of the use case.
Monitoring drift
LLMs are also susceptible to model performance degradation over time, otherwise known as model drift. Since LLM outputs are text, monitoring the embeddingdrift is useful to track changes in predictive performance. Embeddings are a representation of the model’s output that can be used to compare different outputs to identify changes in the model’s behavior over time. By continuously retraining an embeddings model on the current data, we can check if the current distribution matches the distribution of the embeddings we use in production. Once the difference between these distributions exceeds some threshold, we can deploy the new model to production.
LLMOPs (MLOPs for LLMs)
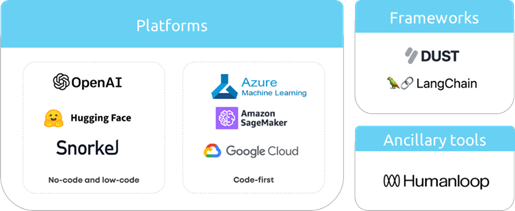
Finally, we use LLMOPs to help us orchestrate the implementation of these safeguards and monitoring procedures as well as prepare us for the unpredictable complexities of LLMs. If you are familiar with MLOPs, the landscape for LLMOPs looks similar. There are platforms to manage infrastructure for fine tuning, versioning and deploying models; frameworks which make it easier to develop LLM applications and ancillary tools that are used to streamline smaller parts of the workflow like reinforcement learning from human feedback.
A (non-exhaustive) overview of an LLMOPs stack components
RLHF & alignment testing
Reinforcement learning from human feedback (RLHF) is a novel approach that takes us one step further to Artificial General Intelligence. OpenAI used this method to fine-tune ChatGPT, hiring a group of human writers and domain experts and asking them to write answers to a set of prompts. They then used the dataset of prompt-answer pairs to finetune the model.
Testing alignment stability is complex. How do we test people’s preferences over time and how do we ensure these alignments in the system don’t cause severe changes in the inner workings of the model?
This is well illustrated by the the diamond-alignment problem. The author of this interesting story sets up a hypothetical experiment where a reinforcement learning agent is rewarded for diamond mining but also aligned by using other rewards. The model can be self-stabilized to keep the initial goal as the main one, even though it is rewarded for other smaller goals. This translates well to LLMs, if we teach them to become more human-like though alignment, they don’t necessarily forget about their main goal of helping humans by providing correct information. But does it work like that in the real world?
To ensure fairness in alignment, and make sure the feedback provided to the model is not biased, we can continuously evaluate the performance of the model on specific tasks. Repeating acceptance tests can be useful to evaluate the changes in performance, based on defined test cases. Additionally, making sure both the testing and human feedback teams are diverse will play a big role in creating a test strategy that is fair and robust. Training testers on how to evaluate the model performance and to provide feedback is crucial. These initiatives come from the organizational level and involve a governance framework to ensure that all ethical principles are covered at the most granular, operational level.
Governance framework
We will continue to see the use and development of LLMs and generative AI becoming more accessible and widely used. And as we have demonstrated, these models have the potential to produce biased, toxic, and harmful outputs which can ultimately have a significant social, ethical and legal impact. Therefore, it is essential to have a clear set of guidelines and principles that ensure the responsible and ethical use of these technologies. A governance framework can help to identify potential risks and address them before they become major issues. The framework should be aligned with societal, ethical, and organizational values. This governance framework should be used in conjunction with the Testing LLM Playbook to create a comprehensive testing strategy that is aligned with the ethics and values of the organization. We propose a 3-layer human centered governance framework consisting of:
The context layer: these are the principles and laws we need to abide by to be ethical and legally compliant. This should include Fairness, Transparency, Safety, Robustness, Privacy, and Accountability. These principles should be embedded in the AI system design.
The organizational layer: this is where we strategically align corporate values and policies into our AI governance and risk framework and ensure we are building user-centered, value-creating applications.
The operational layer: this is the technical build layer which includes system design, testing methods, tools, and monitoring. We cover data, model, and system tests. The test requirements will be based on the previous two pillars.
Governance framework for Generative AI
Conclusion
As you can see, it’s no easy feat to test LLMs. There are multiple methods that can be used and many coverage areas to consider, from the data to the model and finally ensuring the system is user centered.
We hope this LLM playbook has shed light on how you can ensure that you have a high performing, quality performant, yet safe and fair LLM in production. This blog is to be used as a guide to create a practical checklist for testing, based on your specific use cases.
Regardless, there should always be an oversight and validation team in place to enforce the governance framework, assess any harmful risks, and to provide due diligence for the model, processes, and outcomes. This governance team should be a diverse team that can recognize risks and biases and mitigate them as best as possible. This team should consist of leadership, legal, domain expertise and AI practitioners.
SogetiLabs gathers distinguished technology leaders from around the Sogeti world. It is an initiative explaining not how IT works, but what IT means for business.
 English | EN
English | EN