 English | EN
English | EN 
A few days ago I attended a Databricks webinar where they talked about how to integrate the two worlds of analytics, the traditional Business Intelligence and the part more linked to Machine Learning and Data Science.
As we know, if you ask a business intelligence expert about: Data Warehouse, Corporate Information Factory, Data Marts, Cubes, etc. Without a doubt, the answer will be very complete and he will even be able to give you a multitude of success stories he has worked on implementing these solutions.

However, in recent years, business needs for real-time information analysis have led to new terms being added to the knowledge generation process. Streaming, Event Hubs, Data Lake, Real Time, Lambda, etc.
And especially with the appearance of the “sexiest profession of the 21st century”, the Data Scientist, the set of new words linked to analytics has continued to grow: DataFrames, Hyperparameters, Neural Networks, Models, Algorithms, Clusters, etc.

This situation, with such disparate analytical needs, poses a problem for companies when managing data in a simple and efficient way. Although the cost of data storage has decreased with new tools in the cloud, doubling services for its treatment and management, it can burden the account at the end of the month. That is why, a unique data management in the business environment is required, to take advantage of the best architecture and allow the optimization of corporate resources in the generation of knowledge.

How do you do this? Looking for a way to integrate traditional BI with Advanced Analytics into a single environment. That’s why we’re talking about Lakehouse, it comes with the good from both Worlds.

To this end, a new paradigm of architectural development is being developed. What they call Lakehouse.
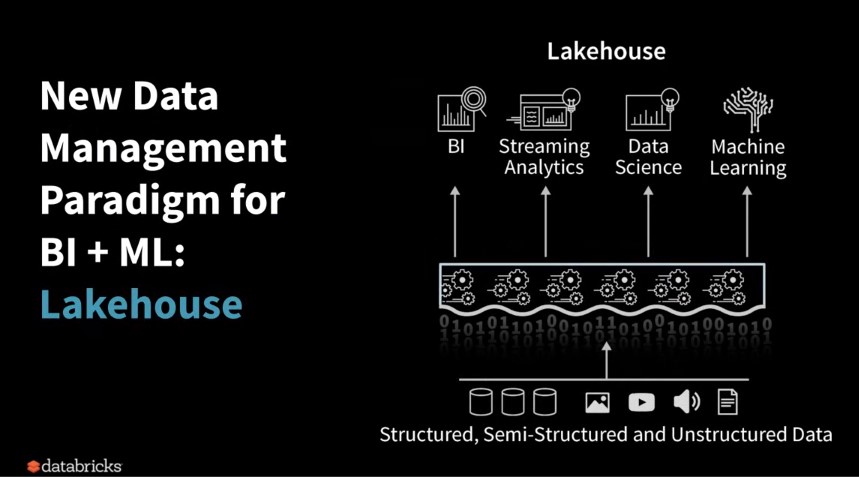
But, technically, how does Databricks solve the problems that this architecture presents?
Firstly, using Spark as the main unification engine, since it allows integration with many ETL tools, Data Warehouse, as well as supporting streaming processing, graphics and incorporating libraries for Machine Learning and Deep Learning.
And secondly, unifying the data service for both BI and ML.

Because Delta Lake ensures data reliability by allowing ACID transactions, it unifies Batch and Streaming processes, it applies the schema, as well as allowing Time and Streaming, among other features.
Source: Microsoft. “Introducción a Delta Lake”. March 2020.
CONCLUSION
The business world needs to meet new needs in terms of advanced analytics, which represents a challenge that forces organizations and individuals to do their best. Databricks’ emergence of this new paradigm only deepens the clear obligation of evolution and continuous improvement. It represents an important leap forward in combining the processing of all types of data in both Streaming and Batch into an architecture, allowing the integration of artificial intelligence models for a complete Reporting.
If they introduced Delta Lake a few months ago and represented a substantial improvement over parquet or other storage systems, today with this new contribution I believe that Databricks positions itself as the benchmark solution in Advanced Analytics today.
NOTE: It’s important to remember that Databricks allows the complete integration of its products with the Azure and AWS clouds.