 English | EN
English | EN BASICS OF MACHINE LEARNING
August 8, 2019
Most artificial intelligence is powered by machine learning algorithms. So, when people want to know if their artificially intelligent system is working well, they ask testers ‘can you test my AI?’.
Testing machine learning is different from “normal IT-systems” because the system is not programmed but trained. And if the machine learning algorithm is “continuously learning” test results are unpredictable because the algorithm keeps on learning so the result of tomorrow will be different from the result of today. Thus, testers need to be aware of the peculiarities of artificial intelligence when preparing their testing. We have noticed some interesting basics about machine learning that we want to share in this blogpost.
Machine learning is mainly not an automatic process
To the superficial observer, machine learning sounds like an automatic process. It is a machine that is learning. So why would human activity be involved?
When looking closer into machine learning we quickly found that the process of machine learning is quite complex and does include a lot of human activity (although supported by tooling).
Machine learning only works thanks to data. A lot of data. The data used is often gathered for a different purpose and comes from different sources. Therefore, there are often inherent problems with the data, for example:
- Data elements that shouldn’t influence the outcome must be ignored during learning, for instance, the gender in a job applicant’s curriculum vitae
- Outliers in the dataset that shouldn’t be a base for learning
- Incorrect information (this can be caused by bugs in the information system the data is collected from)
- Outdated information, for example, decisions based on changed regulations
- Data that is not diverse enough (this can happen when the data comes from a subset of the population and therefore isn’t representative of the whole population)
- Varying formats of data, because they have a different origin
All these instances, and many other problems, need to be found and corrected. This means that before the actual training of the machine learning model can start, a lot of data preparation is needed.
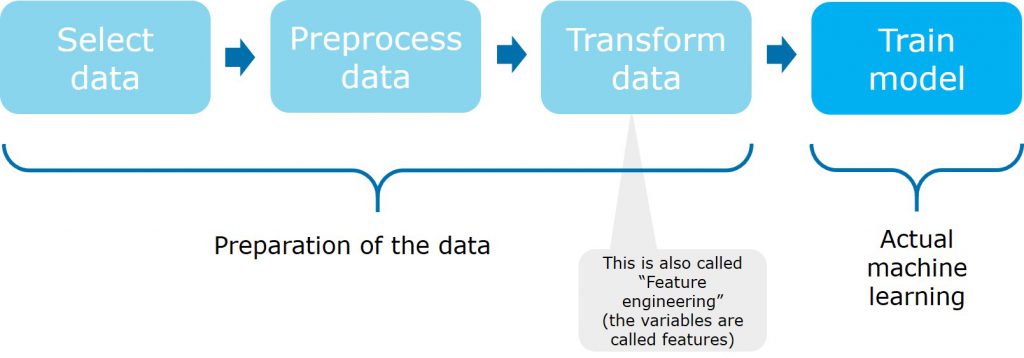
Commonly, data scientists will distinguish three major activities in the preparation of data. First, they select the data. This of course highly depends on the goal they want to achieve with the machine learning algorithm.
When the correct datasets have been obtained the second step is to preprocess the data. This is needed for example to align data that comes from different sources, for example when data is in different formats (e.g. a date can be yyyy-mm-dd or dd-mm-yyyy). Preprocessing of data is also necessary to remove outliers and data elements that shouldn’t influence the outcome.
The third step is to transform the data in the proper format needed by the model that will be trained.
For the machine learning to occur, the system also needs to have feedback on the result. In many cases, this is also done by humans, giving us another human influence on learning. You could say that the machine learns, and the teachers are human.
If you don’t work with machine learning, it’s easy to think about it as magic where the machine automatically learns and becomes a perfect being. It’s important for everybody to know that as we humans are involved, the process can never be perfect, and artificial intelligence will be as faulty as the rest of human activity.
This blog was written by Eva Holmquist (Sogeti Sweden) and Rik Marselis (Sogeti Netherlands).
Eva Holmquist is a senior test specialist at Sogeti. She has worked with activities from test planning to execution of tests. She has also worked with Test Process Improvement and Test Education. She is the author of the book “Praktisk mjukvarutestning” which is a book on Software Testing in Practice.
Rik Marselis is a test expert at Sogeti. He worked with many organizations and people to improve their testing practices and skills. Rik contributed to 19 books on quality and testing. His latest book is “Testing in the digital age; AI makes the difference” about testing OF and testing WITH intelligent machines.