 English | EN
English | EN 

A few days ago I finished the first Azure IoT Hub practice, and the next step I commented was to collect all the raw data in an Azure Data Lake Gen2. Therefore, the first thing we must do is create it. To do this, we will choose the same group of resources and obviously the same region. This, although it seems obvious, is important since keeping resources “close” optimizes processes.
Here is another tip , from the point of view of cost control, it is advisable to review the cost per service in different neighboring regions, since the same resource in different areas may also have unequal costs.
Let’s get started with the configuration of our Data Lake Gen2. To do this, we locate the new component from our resource group, and begin to fill in the required fields.
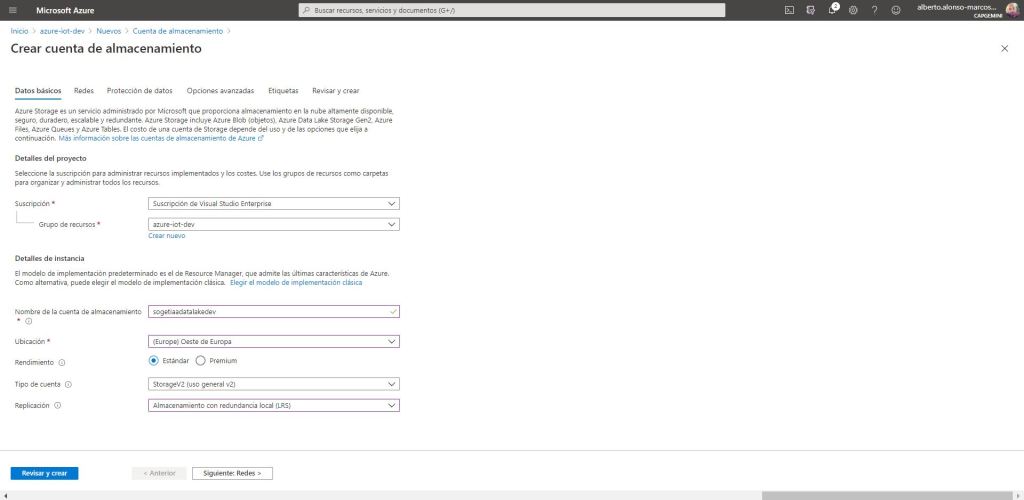
We select the performance type as Standard since we are only going to save the information of two Iot devices. With which the Premium would be underused and we would incur unnecessary expenses. The same for replication, in this example it helps us to choose local redundancy . In the event that we have to face situations that require high availability or a higher level of security in the persistence of the data, it would be a good time to evaluate some of the different options offered by Azure. As this is not the case, we continue…
It is important to remember that to go from an Azure Storage Account to an Azure Data Lake Gen2, you only have to enable the hierarchical namespace set. Easy!

It is time to add the set of containers that we need, although for today’s example, we would have enough with the first two.

Once we have finished with the creation of several containers, we will go on to configure the routing part from the Azure IoT Hub. To do this, the first thing is to create an end point for each of the data sets to be stored. We create the first one for device 1. To do this, we connect with the previously created content to collect the information from said device, and we also configure the batch frequency to the minimum. In this way, we will begin to collect information from the beginning and we will be able to validate that we received the data. All that remains is to configure the structure with which the files will be organized, which in this case will be of the JSON type.
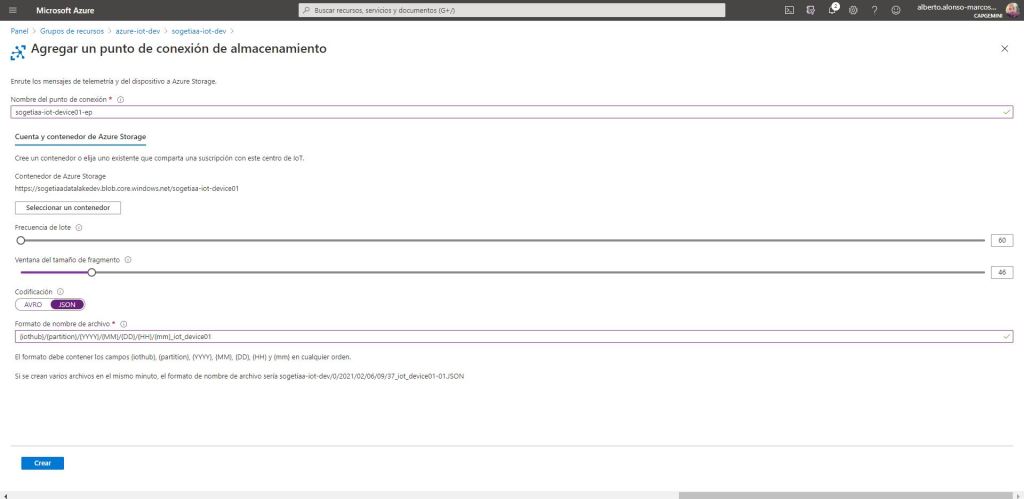
Once the end point is completed, all that remains is to create a route. For this we give it a name and choose the corresponding end point. We indicate the type of data source and to capture only the data from device 1, we create a routing query that filters by the device name. There are multiple other filtering options, in future posts we will see how to persist data sets through temperature ranges.

In the case of device 2, everything will be almost the same except that the file format will change from JSON to Avro. This second is the default type and is extremely useful for later analysis with tools such as Azure Databricks .

Finally we create the route for device 2, modifying the name of the device in the information capture.

Once completed, we would only have to review the content of our containers to verify that everything works correctly and that we capture the information of the applicable device.
We see the result for device 1 as JSON files in the previously defined path.

We do the same for device 2, although remember that it will be stored in Avro format.
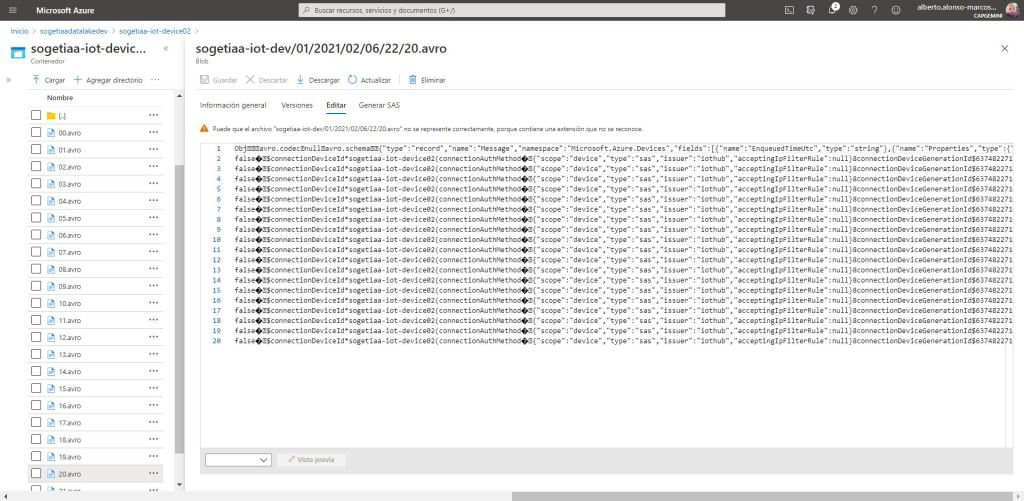
As can be seen, it is extremely easy to save raw data from our IoT devices, which allows us to respond to multiple challenges within Advanced Analytics. For example, for the implementation of a predictive maintenance model.
On the other hand, Azure IoT Hub also allows you to subscribe to events through Azure Event Grid . This allows to greatly expand the integration possibilities with Azure solutions, which enables the option of building anomaly detection systems by triggering actions such as integrating Azure IoT with Event Grid and Azure Functions to receive a notification in the event that a sensor will detect a temperature value higher than, for example, 100 degrees centigrade.
With all this, we see that the Azure IoT Hub adventure has only just begun, a new entry will arrive shortly to discover interactions and use cases.
See you soon!
