 English | EN
English | EN AUTOMATION IS COMING – HOW WILL YOU SURVIVE?
December 17, 2018

How AI will disrupt the developer and IT-architect; and what can they do about it?
You might be in your 20s, 30s, or 40s and surfing on the wave of brand new technology with no fear of “what’s to come”. We know that AI (Artificial Intelligence) with its Machine Learning and Cognitive Automation is surfacing below the deep unknown waters and that they will disrupt the industries within the transport, fast food, and farming sectors. We even know that the disruption will not only influence the blue-collar workers, but almost every job profile is also affected by accountants, lawyers, medical practitioner up to data scientists already in touch with AI. The questions we will treat here are, how will this AI revolution influence software development, and therefore the developer and IT-architect? What should you expect from the upcoming world of the 2020s and how should you prepare for it?
To understand what will happen in the 2020s we need to review what has happened in the last 61 years in the field of AI.
The History of Artificial Intelligence
The first machine learning program and neural networks
The concept of “learning machines” is not new. The first electronic device that was able to learn and recognize patterns [Cor57], was built as early as 1957 by Frank Rosenblatt. The first machine learning prototype was built in 1961 by Leonard Uhr and Charles Vossler [Pat61]. Neural networks have existed for a long time, but their learning required a lot of labeled digital data, which was rare and expensive in the 1960s. In today’s digital world, especially social media deliver huge amounts of labeled date every second. Sensors were also analog and not very precise compared to today’s sensors in phones, smart homes, and cars. This is probably why chess was so interesting to automate because the sensory data input was simple (only 8×8 tiles and 12 types of bricks) but could result in at least 10^120 probable chess games [Che], which is larger than the number of atoms in the known observable universe [Uni].
The chess game itself was simple enough to code but winning a chess game was not. It was obvious that neural networks had a potential, but no neural network at the time was able to beat a human chess champion.
The 2000s
Something happened in the 2000s, that made AI move forward and solve problems AI couldn’t solve before. DARPA arranged in 2004 a self-driving car competition: “The DARPA Challenge”. No car managed to complete the course and the longest driven distance was 12 km.
DARPA tried again in 2005 with completely different results: 23 of 24 cars managed to beat the record of 12 km, where 5 of the 24 cars managed to complete the whole course of 212 km. What happened? The incredible improvements of big data, affordable HPC and deep architectures, e.g. digital online maps became available, image analysis tools became better, etc.
Deep learning
Software engineers and scientists required fewer data to build e.g. an image recognition algorithm, than a neural network required to learn to recognize images. In the late 2000s enough labeled digital data was available for machine learning software to remake the same image recognition algorithms, that humans already had developed. Deep learning was one of the machine learning methods, that split the learning into multiple layers. The first layer learned to recognize simple forms from pixels. The next layer learned to recognize faces from simple forms. The state of the art is that machines e.g. can diagnose diseases on the basis of images and do so better than corresponding human specialists
Not only did deep learning remake the previous image recognition algorithms, it even improved them. Machines didn’t only recognize items on images but also began to create its own images called “computer dreams” [Ifl]. Machines even began to change summer to winter on existing photos and even change day to night and the other way around [Pix]. The machine learning algorithms were not new, but the new huge datasets gave new possibilities.
What to expect?
Software development by humans
Software is all about mapping the inputs with the correct outputs to solve specific problems.
A software engineer or a computer scientist could take a complex real-life phenomenon and refine the necessary patterns into an algorithm:
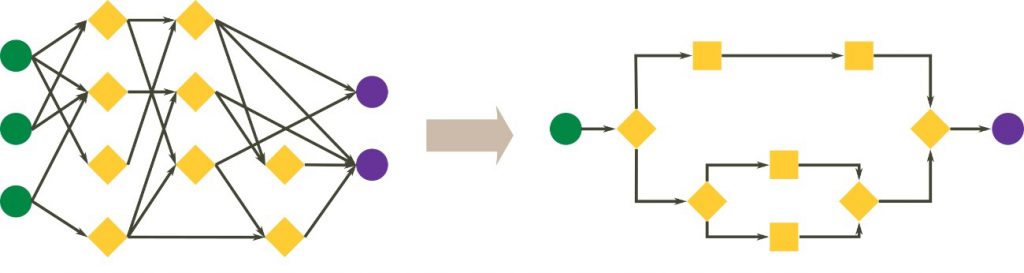
Software development by machines
Most machine learning is only about connecting inputs with outputs, but machine learning based on evolutionary algorithms are able to improve itself by putting pieces of codes together into completely new algorithms. This type of evolutionary development is a lot faster than traditional human software development.
In 1997 humans managed to develop Deep Blue, the first computer that was able to win a chess game against a human world champion. It took 20 years, before AlphaGo in 2017 was able to win the board game Go against the best player in the world.
AlphaGo Zero (a new version of AlphaGo) was developed based on reinforcement learning. AlphaGo Zero learned itself to play Go from scratch in only 4 hours, after which it was able to beat the original AlphaGo 100 times in a row [Dep].
A machine was able to create a better algorithm in only 4 hours compared to the 20 years the multiple developers and architects needed. Developers and architects will be disrupted, but there will still be a need for humans.
It might not be fair to compare the human development time to only training/learning time of the machine since it also took some time to develop the training/learning algorithm. What we have to remember, that the training/learning algorithm can be reused for other projects, while the human development time will not.
The risk in not understanding
Software in the last 70 years has been built on simple algorithms that are understandable by humans (even though they are still difficult for humans to understand). Machine learning software can create a new type of algorithms that are much more complex and impossible for humans to understand. We are much more dependent on our software today than ever before, and not understanding the algorithms behind our software will be a huge risk to take.
The consequences are not dire, when weather-chatbot mistakes the word “tonight” with a city name, as asking the weather-bot “What is the weather tonight?” would only result in a bad answer: “I don’t know ‘tonight’. Try another city or neighborhood.”. Word mistakes such as that would have far worse consequences for a critical healthcare system, especially, if no human was able to fix the problem. Some would say, that these mistakes happen because AI is still in the early stages of development and it is only a question of time before these mistakes won’t happen – but will they?
Complex algorithms are not perfect
Kurt Gödel proved with his incompleteness theorem, that all systems are incomplete, even math. I have simplified Gödel’s proof into:
- For a sentence to be true in math, it must be proved.
- But what about: “This sentence is unprovable”?
If this sentence is true, then it can’t be proved and therefore false according to math.
The bad news: Complex algorithms created by machines are also systems and therefore incomplete, imperfect, flawed, and containing unexpected bugs.
The good news: A chess algorithm does not have to win all possible games. It just needs to win more times, than the current world champion. If humans could design a healthcare system as a board game, then machines would find better and better ways to win this game. If humans could design a healthcare system as a board game, then machines would find better and better ways to win this game, just like AlphaGo Zero managed to win the board game Go better than any human could.
Test Driven Reinforcement Learning
In traditional development of machine learning, a dataset is split into training data (80 %) and testing data (20 %). The training data is used to train the machine, while the testing data is used to evaluate how precise a machine is to predict/categorize. Data that reduce the precision is removed from the dataset, while data that increase the precision is added. Building, navigating, and improving the datasets require a data scientist or someone with a lot of mathematical, statistical and technical know-how. This restricts a lot of people from working with machine learning.
Reinforcement Learning is about rewarding and punishing behavior to either reinforce wanted behavior or diminish unwanted behavior. I have built a prototype: A bot that has to follow a target. The bot has 4 cameras (one in each direction) and a leg (so it can move in a direction). The bot would start moving the leg randomly. To reinforce a leg movement a developer could set up a technical test, that measures the distance between the bot and its target. If the distance decreases, the probability of the leg movement would be reinforced, but if the distance increased, then the probability of the leg movement would diminish:
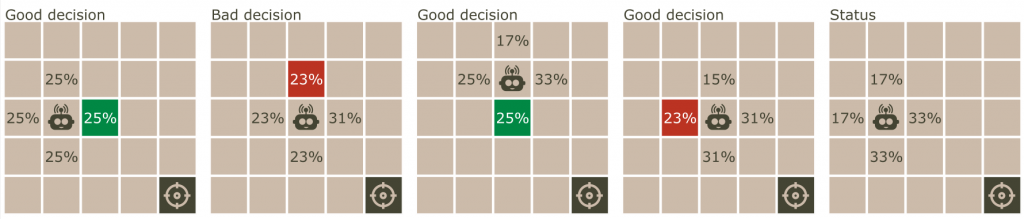
Caption: “Visual example of how my prototype learns and unlearns.”
My prototype is even able to handle changes in the environment, because of constant learning and unlearning. If two cameras switch place, then the bot would unlearn the old camera-movement relations and relearn the new ones.
I named this approach TDRL (Test Driven Reinforcement Learning) and is completely different than traditional development of machine learning. Instead of preparing the dataset for a machine, the machine gets access to an unfiltered dataset or environment. The tests will govern the development of the machine and whenever a machine behavior needs to change or be fixed, then a new test case can be written. For example, Microsoft deployed an AI chatbot “Tay”, that became racist within 24 hours. If this was built on TDRL, then this could have been easily fixed by adding a test case that measures the racism level within a sentence. The chatbot would then fix the problem itself, by governing its own sentences and lower the probability of writing something racist.
The book “Testing in the digital age” [Tes2018] describes, that we will not only need technical tests (like in the example above: “measuring the distance”), but also ethical and conceptual tests (like measuring mood, empathy, humor, and charm) to improve robots in the roles of a partner, coworker, or assistant. Technical tests will be less complex to design, while the ethical and conceptual test will be more difficult. Ethical and conceptual tests would require domain-specific knowledge. For example, the concept of “health” or “happiness” can be perceived differently: Something that is healthy for me is not necessarily healthy for my children, or the planet’s environment.
Summary
How will this AI revolution influence software development, and therefore the developer and IT-architect?
There is no doubt about that the AI revolution will disrupt the IT-industry in the 2020s. Machines will be able to create better and more complex solutions, in less time, than a human developer and architect ever could. Machines will even disrupt the data scientist.
What should you expect from the upcoming world of the 2020’s?
We already see the need to govern machine learning bots and this need will only be growing. To govern the machines doing software development; developers and architects will have to design tests and guide the machines in creating software and solutions.
How should you prepare for it?
There is already a need to design ethical tests, like for Microsoft’s AI chatbot “Tay” that became a racist. But before ethical tests can be implemented, a new set of development tools need to be developed from current TDLR prototypes. As a developer or architect, you will have the opportunity in the next few years to become a part of the development, and get the experience needed to not only design the technical tests, but also the ethical and conceptual tests. The book “Testing in the digital age” [Tes2018] is a good start to find out how to deal with these new challenges. Ethical and conceptual tests will require us to answer difficult domain-specific questions such as “what is a good partner”, “what makes a good product”, “how to make the customer happy”, etc.. These questions are important, and as a developer/architect in the 2020’s we will be answering them!
| Bartek Rohard Warszawski defines “knowledge” as the ability to predict a future – if you can predict something, then you can prepare for it. He has almost 30 years of experience within software development and testing, which he uses, when he speaks at conferences, writes articles, and holds workshops in TDD and test automation.Email: Bartek.Warszawski@Capgemini.comLinked: https://www.linkedin.com/in/bartek-rohard-warszawski/ |
References
[Cor57] “The Perceptron A perceiving and recognizing automaton (project para)”, Cornell Aeronautical Laboratory, inc., Report No. 85-560-1, Frank Rosenblatt, January 1957
[Pat61] “A Pattern Recognition Program That Generates, Evaluates and Adjusts its Own Operators”, Leonard Uhr and Charles Vossler, May 1961
[Che] http://mathematics.chessdom.com/shannon-number
[Uni] https://www.universetoday.com/36302/atoms-in-the-universe
[Ifl] http://www.iflscience.com/technology/artificial-intelligence-dreams/
[Pix] https://petapixel.com/2017/12/05/ai-can-change-weather-seasons-time-day-photos/
[Dep] https://deepmind.com/documents/119/agz_unformatted_nature.pdf
[Tes2018] Testing in the digital age, by Rik Marselis, Tom van de Ven, Humayun Shaukat, 2018, ISBN 9789075414875
This content was first published in magazine OBJEKTspektrum, Germany.
About the author