 English | EN
English | EN 
Currently, we see a lot of buzz around the microservices architecture. While this architectural style provides good advantages, it can be intimidating for engineering teams looking to move over from the traditional monolith applications.
In this article, I will be describing phases taking monolith architecture to microservices architecture.
Below are the self-explanatory diagrams explaining the need of microservices architecture:
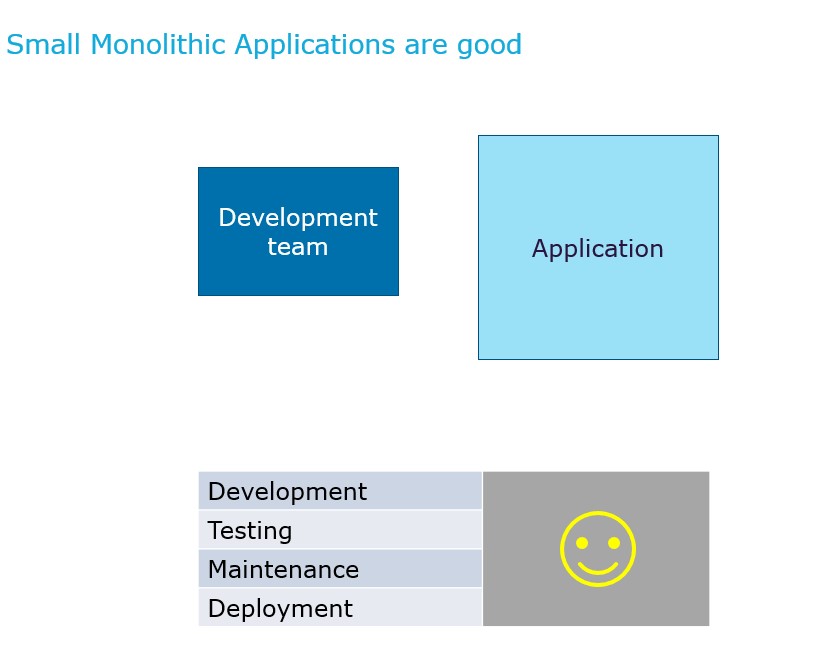
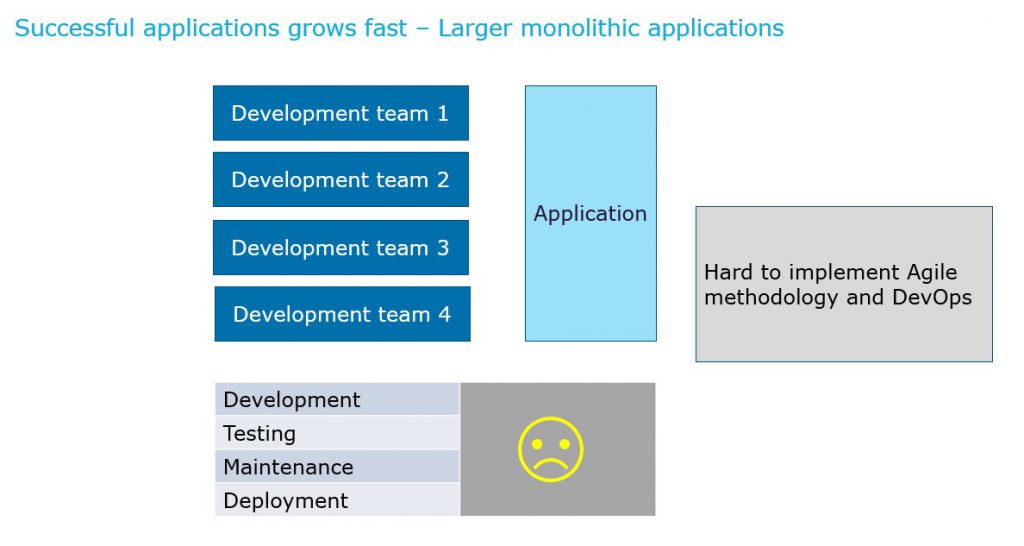
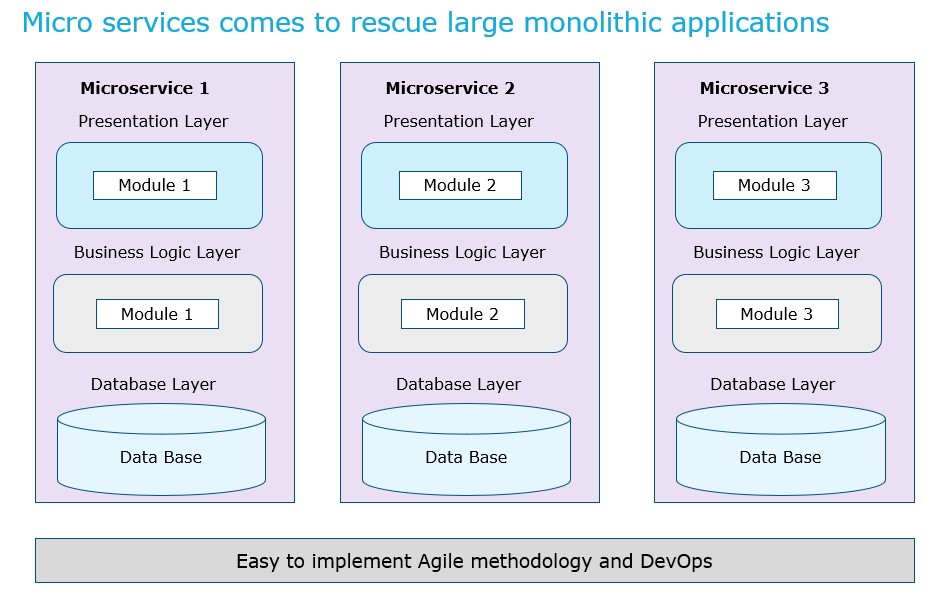
Microservices architecture involves small and well-designed microservices, that exchange messages among themselves
We need to take key decisions before moving to microservices architecture
- Boundaries of individual microservices and how small and what functionality to go in each microservice
- What data is required for individual microservice and design of the database schema
- How microservices communicate with each other
- Failover strategy
- Configuration management
Importance of automation in microservices (DevOps)
In microservices, we will have a good number of smaller components instead of a monolith, we need to have automation in every activity, such as builds, deployment, and testing.
- With the help of CI / CD servers, build and deployment process can be automated which will result in faster production release cycles
- Junit test cases enables the automation backend testing process
- We have good number tools like selenium, Cucumber etc. in the market to enable automation of UI testing
Logging and Tracing
Certain application functionalities can comprise of dozens of separate microservices or serverless functions, we have significant implications on the application logging.
We need to address the following key aspects of logging and tracing
- How the logs produced by microservices are collected
- How the logs are aggregated
- Error alerts
With the help of tools like ELK stack, we can analyze and aggregate the logs to provide support to Ops teams, Support teams, and developers to troubleshoot microservices when they see unexpected behavior.
Prometheus, another tool, has emerged as the preferred tool for microservices monitoring and how metrics are collected and processed. Prometheus aggregates metrics and stores in data store for further analysis using interactive and visualization tools like Grafana.
Transformation to Microservices
In this section, we will discuss the steps involved in the transformation of monolith application to microservices.
A well-designed monolith application will have a clear separation of UI layer from the Service layer which will help in transformation to microservices, if not, the first step in microservices transformation is to separate the UI layer from the service layer and host in separate containers
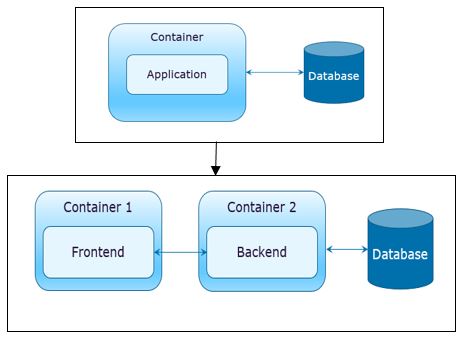
In the next level of transformation, we develop an API on the backend which can be used by any component to communicate with the service layer (backend)
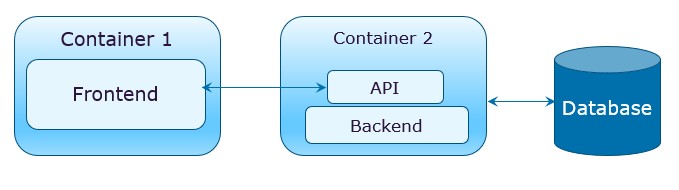
In the next level of transformation, we perform a full separation – down the database level. It would be good to start decomposing with a domain which is small and easy to extract. It will allow the team to gain the necessary experience with little risk and in a relatively short time.

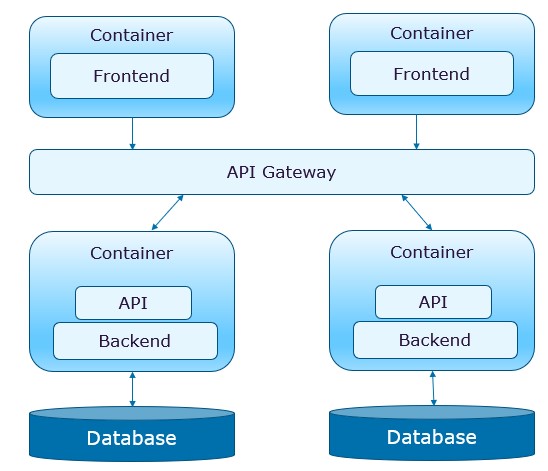
Finally, we separate the UI layer specific to microservice
Transaction management
Building distributed transactions across multiple microservices is a complex job as we must consider many aspects of the transaction management like dealing with service availability, consistency between services, isolations, and rollbacks we need to consider all these scenarios during the design phase.
In this section, we will discuss various patterns that we can consider for transaction management
1. Avoid transaction management
Usually, microservices are designed to be independent and address the business problem on its own.
If we could split our system in such microservices, there’s a good chance we wouldn’t need to implement transactions between them at all.
2. API composition
We can use API composition pattern to get the data from multiple microservices
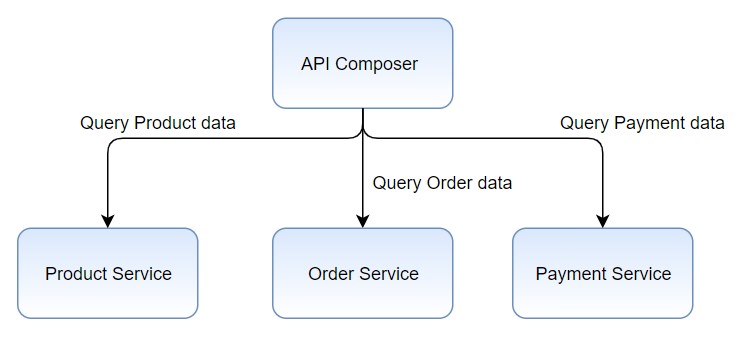
It a simple way to query data in a microservice architecture, this pattern has the drawbacks of in-memory joins of large datasets and inefficiency of some queries
3. Two-Phase Commit Protocol
Two-phase commit protocol is a mechanism for implementing distributed transaction across different software components
One of the important participants in a distributed transaction is the transaction coordinator. The distributed transaction consists of two steps:
Prepare phase — during this phase, all participants of the transaction prepare to commit and notify the coordinator that they are ready to complete the transaction
Commit or Rollback phase — during this phase, either a commit or a rollback command is issued by the transaction coordinator to all participants
The problem with 2PC is that it is quite slow compared to the time for the operation of a single microservice.
Coordinating the transaction between microservices, even if they are on the same network, can really slow the system down, so this approach isn’t usually used in microservices architecture.
4. Distributed Saga Pattern:
In a distributed saga pattern, we implement each business transaction that spans multiple services as a saga. A saga is a sequence of local transactions. Each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails because it violates a business rule, then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.
Saga transaction can be implemented in couple of ways:
Event-driven choreography:
Each service produces and listens to other service events and decides if an action should be taken or not.
Below is the e-commerce example implementation of choreography based saga transaction management
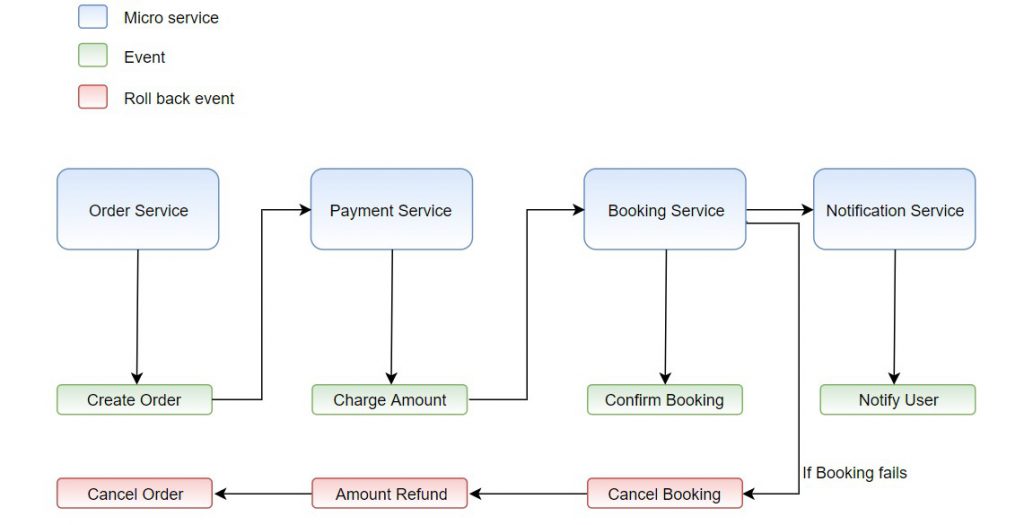
Order service executes a transaction and then publishes create order event.
Create order event is listened by payment service, which executes the local transaction and publishes the charge amount event.
Charge amount event is listened by booking service, which executes local transactions and publishes a confirm booking event.
Confirm booking event is listened by Notification service, which executes local transactions and publishes notify user event.
The distributed transaction ends when the last service executes its local transaction and does not publish any events, or the event published is not heard by any of the saga participants.
Transaction roll back:
Rolling back a distributed transaction is a very costly effort. Developers must implement another operation/transaction to compensate for what has been done before.
In case of booking failure, booking service creates cancel booking event which is listened by payment service and triggers the amount refund event.
The amount refund event is listened by order service, which executes local transactions and publishes cancel order event.
Command/Orchestration:
Coordinator service is responsible for centralizing the saga’s decision making and sequencing business logic.
Conclusion:
This article provides a detailed overview of transferring from a monolith architecture to microservices-architecture, this article is not intended to favor one over the other. Although microservices offer superior performance metrics in several areas, monoliths must not be interpreted as bad as they have their own strengths and advantages.
Working with the original monolith framework within the IDE is cool when the application is small and simple and managed by one team. So, do not attempt to break a monolith unless it gets too complex or you absolutely feel the need to break it up.