 English | EN
English | EN 
Introduction
Online shopping platforms thrive on customer reviews, but product pages often suffer from stale or incomplete summaries. Without aggregated sentiment, customers struggle to make quick decisions, and conversions drop. Manual review summarization doesn’t scale, and relying solely on cloud-based LLMs introduces high costs, latency, and privacy concerns.
This blog explores how a Small Language Model (SLM) running locally inside Azure App Service—can deliver real-time, cost-effective, and privacy-compliant review summaries.
Problem Statement
- Stale content: Product pages show outdated or incomplete review summaries.
- Scalability issues: Manual summarization fails as review volume grows.
- Cloud dependency: Sole reliance on cloud LLMs raises costs and data residency concerns.
Solution Architecture
This solution automatically ingests new product-review events, enriches product data with concise review summaries and sentiment, and persists results back to the catalog. It combines an Azure queue for reliable messaging, a small local database for product data, and a locally hosted Small Language Model (SLM) that exposes an OpenAI‑compatible API. The result: faster decision-making, improved product listings, and controlled AI costs while keeping sensitive data local.
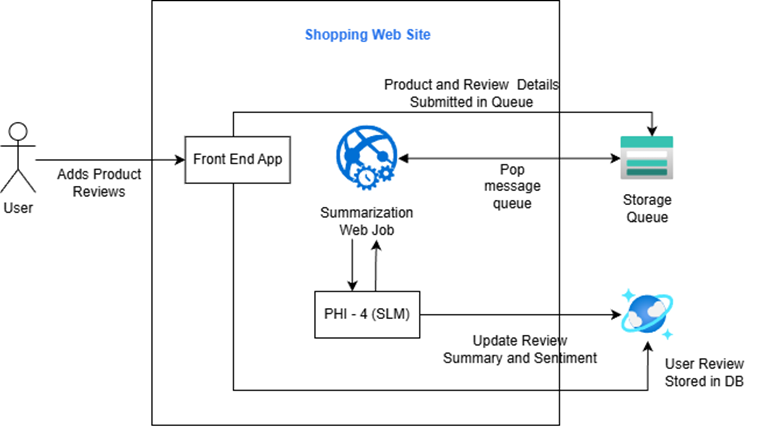
Key components:
- Azure Queue – Reliable messaging pipeline for incoming review events.
- Cosmos DB – To store product and review metadata.
The Sidecar pattern allows AI inference to run alongside the main application container, adding services like monitoring, logging, and networking without tightly coupling them to the core app.
Output of the summarization
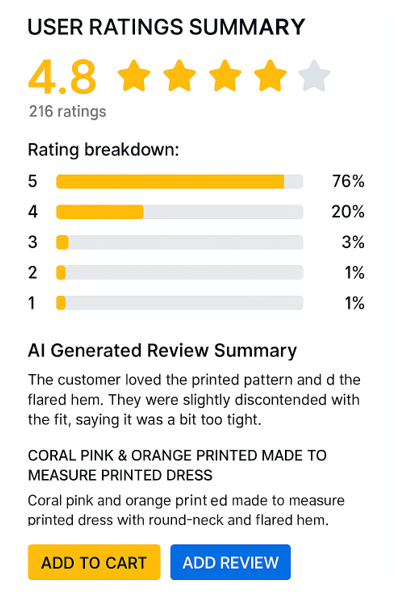
What this solution delivers?
- A simple sentiment label (positive / mixed / negative) per product for UI badges and filtering.
- Continuously updated, succinct review summaries (≤~80 words) that reflect incoming feedback.
- Near real-time updates triggered by review events, keeping product pages current without manual work.
- Privacy & compliance: customer reviews stay within your environment, simplifying data governance.
- Cost control: local SLM inference reduces per-request cloud fees and predictable capacity planning.
Conclusion
This system converts raw review volume into short, actionable product summaries and sentiment at scale, improving customer experience and lowering content costs. Start with a focused pilot, measure business outcomes, then scale with operational guards (quality checks, monitoring, and fallback plans).