 English | EN
English | EN 
The rapid development of Large Language Models (LLMs) has profoundly reshaped the paradigms of contemporary artificial intelligence. These models, capable of processing and generating content across multiple modalities (text, audio, image, video), require vast amounts of precisely annotated data for effective training. Annotation, as the process of structuring and contextualizing raw data, represents a critical step in building robust, diverse, and representative training corpora.
In this context, we have developed a proof of concept for a multimodal annotation application, designed to meet the growing demands of heterogeneous data processing. This application features a modular architecture that allows dynamic adaptation of both the number and type of data channels to be annotated. It supports multiple synchronous or asynchronous modalities, including time series data (e.g. from biomedical or environmental sensors), audio streams (e.g. speech, ambient sounds), video recordings (e.g. behaviors, facial expressions, gestural interactions), and textual data (e.g., transcriptions, metadata, semantic annotations).
One illustrative use case of this application is the multimodal analysis of complex clinical situations. For instance, annotating recordings of patients in hospital settings, connected to physiological monitoring devices—enables the integration of vital signals (e.g. ECG, respiratory rate), verbal interactions, and observable behaviors captured on video.
Example of annotation on the EAV dataset 1 using the multimodal annotation application developed internally at SogetiLabs:
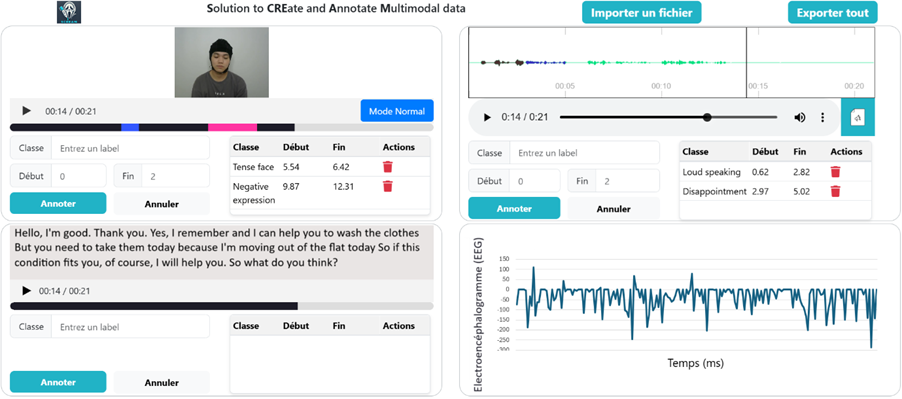
This integrated approach offers a more refined and contextualized understanding of the observed phenomena by combining complementary data modalities. It facilitates the identification of complex correlations that are often inaccessible through unimodal analysis, thereby paving the way for significant advancements in fields such as augmented medicine, applied research, and specialized training.