 English | EN
English | EN 
In today’s world dominated by artificial intelligence, terms like transformers, LLMs (large language models), and embeddings are everywhere. While many are familiar with models like ChatGPT, few truly understand the fundamental components that power these systems. One of the most crucial and often overlooked elements is the embedding.
As companies increasingly adopt deep learning to build data-driven products, they feed their neural networks with massive volumes of multimodal data — text, images, audio, and much more. To interpret this data, deep learning models rely on embeddings: internal numerical representations that capture the meaning, structure, and relationships within the input data.
Over the past decade, embeddings have evolved from simple statistical tools to sophisticated semantic encodings. They are now at the heart of many technologies, from Spotify’s music recommendations to YouTube’s video suggestions, Pinterest’s visual search, and Netflix’s content strategy. Even though users don’t see them directly, embeddings quietly shape the digital experiences we live every day.
In this article, we will explore what embeddings are, how they work, and why they have become a cornerstone of modern machine learning (ML) systems.
What do embeddings look like?
At a general level, embeddings are a way of representing data — such as words, sentences, or even images — as vectors (lists of numbers) in a high-dimensional space.
Let’s break that down a bit:
Imagine the word “cat.” Computers don’t understand words the way we do. So, we need to transform “cat” into a series of numbers: its embedding — that captures its meaning, context, and relationships with other words. These numbers exist in a multi-dimensional space, sometimes with hundreds or even thousands of dimensions. In this space, words with similar meanings (like “cat” and “dog”) end up close to each other.
From vectors to tensors
To make this more concrete, here’s what a single embedding might look like in a simplified 3D space:
[1, 4, 9]
This is a vector: a numerical representation of a single element, such as the word “fly”. Now, if we want to represent multiple elements—say, “fly” and “bird”—we can stack their vectors together into a matrix (or more generally, a tensor):
[1, 4, 9]
[4, 5, 6]
This matrix is a compact way to represent multiple embeddings at once.
How Are Embeddings Created?
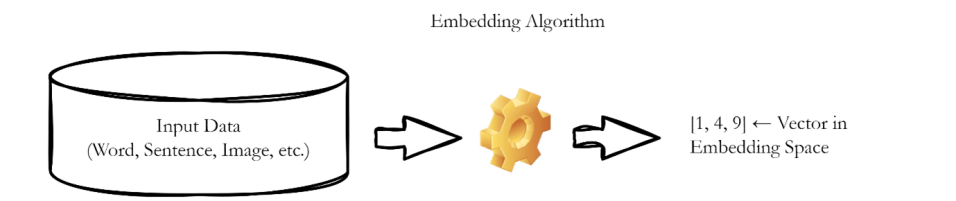
These embeddings are not manually assigned — they are learned. They are generated by feeding raw data into a machine learning model. The model transforms this data and compresses it into a lower-dimensional space while preserving its semantic structure.
Here is a simplified view of the process:
A decade of evolution: from TF-IDF to Transformers
Over the past decade, embeddings — numerical representations of features used in machine learning — have become a foundational data structure in industrial-scale ML systems. Older techniques like TF-IDF, PCA, and one-hot encoding were long essential for compressing and interpreting large volumes of textual data. However, these traditional methods struggled to capture deeper context and semantic relationships, especially as data grew in volume, velocity, and variety.
The real breakthrough came with Google’s Word2Vec, which marked a shift from purely statistical representations to semantic understanding. This was followed by the rise of Transformer architectures, transfer learning, and more recently, generative AI — all of which have firmly established embeddings at the core of modern artificial intelligence systems.
Why do we need embeddings, how are they created and what can we use them for?
Language is messy, nuanced, and contextual. Traditional systems struggle with synonyms, slang, tone, and deeper relationships between concepts. Embeddings solve this by translating complex data into a form that machines can work with efficiently—while preserving semantic meaning.
Embeddings are typically generated using machine learning models trained on large datasets. Each technique embeds meaning into numbers, but each differs in how they capture context, scale, and modality.
Popular methods include:
- Word2Vec – Predicts surrounding words for a given word.
- GloVe – Uses word co-occurrence statistics across a large corpus.
- BERT / Transformer-based models – Generate context-aware embeddings.
- CLIP – Maps images and text into the same embedding space.
Embeddings are incredibly versatile. Here are some of their most powerful applications:
- Search & Retrieval: Semantic search finds documents or images based on meaning, not just keywords.
- Recommendation Engines: Compare embeddings of users and items to generate personalized suggestions.
- Text Classification: Used in spam detection, sentiment analysis, and topic classification.
- Clustering & Visualization: Tools like t-SNE or UMAP help visualize high-dimensional embeddings.
- Cross-modal Understanding: Models like CLIP enable searching images using text and vice versa.
Embeddings in the age of AI
Embeddings are foundational to modern AI models like GPT-4, Claude, and Gemini. When you ask a question or write a prompt, your input is converted into embeddings. The AI uses these to find relevant knowledge and generate meaningful output. They’re also central to RAG (Retrieval-Augmented Generation), where external knowledge is embedded and compared to a user’s query to improve factual accuracy. Embeddings may sound abstract, but they’re revolutionizing how machines understand the world. By converting messy, human-centric data into structured, meaningful vectors, embeddings allow AI systems to reason, relate, and respond in surprisingly human-like ways. Whether you’re building a smarter search engine, a next generation chatbot, or an AI music curator, understanding embeddings is your first step into the heart of modern machine learning.