 English | EN
English | EN NOSQL : WHATU0026#X27;S IN IT FOR ME?
September 9, 2013

NoSQL databases have been under the spotlight for some time now. It’s because in certain use cases they are really better suited. At the beginning of a new project it’s now important to consider all the options for the data storage, and not only relational databases. In some cases the relational option is still the right one, but very often other alternatives can be very efficient, especially for performance, scalability and schema flexibility.
So, NoSQL is not just a buzzword. Let’s demystify a few of the NoSQL concepts…
What is NoSQL ?
 First of all “NoSQL” does not mean “No SQL at all” but “Not Only SQL”.
First of all “NoSQL” does not mean “No SQL at all” but “Not Only SQL”.
In other words, NoSQL is not here to replace existing SQL databases, it just brings another approach for data storage that can be used when a classical “Relational Database” has reached its limits.
With a so vague definition we could consider that any storage system without SQL language is a NoSQL database… But usually the “NoSQL” term is used only for the following categories of databases…
1) “key-value” data store
This type of database works as a big cache stored on a remote server. Each value is associated with a key. The value is “opaque” (no specific structure, not indexed). The storage is usually entirely “in-memory” (with sometimes an optional storage on files).
![]()
The main “key-value” solutions are Redis (http://redis.io/ ), Memcached (http://memcached.org/) and Riak (http://basho.com/riak/ )
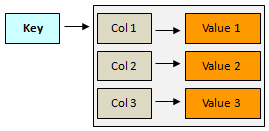
2) “Column-oriented” databases
In this kind of database, the data is also associated with a “key” but it is organized by “columns” and the columns can be grouped by “family”. With the column notion, this type of database is not so far of the relational databases but there’s no fixed column definition (no schema) hence the storage is more flexible.
3) “Document-oriented” databases
In this type each key is associated with a “document” (usually formatted in JSON or XML). Obviously it’s possible to store anything in each “document” so this is the best solution to combine structured data (JSON or XML) with data store flexibility (no schema).
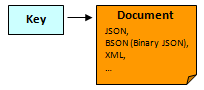
Examples of “document oriented” databases : MongoDB (http://www.mongodb.org/ ), CouchBase (http://www.couchbase.com/ ), CouchDB (http://couchdb.apache.org/ ).
4) “Graph” databases
This type is especially designed to store graphs (nodes and all the links between nodes)
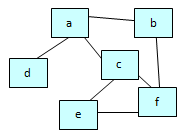
The best known graph database is Neo4J ( http://www.neo4j.org/ )
Why use a NoSQL database ?
NoSQL is very often associated with “Big Data” because it provides natural scalability, improves the performances and can store a huge amount of data. But it’s not the only use case…
When to use NoSQL databases ?
– When the volume of data is big enough to require more than 1 physical server.
– When availability is more important than consistency (see the “CAP theorem” below)
– When the data to be stored must be very flexible (no fixed structure)
Cloud computing integration
NoSQL databases are very often available in the Cloud. For example, Google uses “Big Table” for data storage in “Google App Engine” (http://cloud.google.com ). It’s also very easy to host a database instance on Amazon or Azure servers with a provider like Garantia Data ( “Redis” and “Memcached” hosting on http://garantiadata.com/ ). They are also present in many “Plateform as a Service (PaaS)” offers (CloudBees for example http://www.cloudbees.com )
Schema flexibility
Most of the NoSQL databases are “schema less”. It means that you can store unstructured data. And hence the content can evolve without any administration operation on the database (no “create table”, “alter table”, etc.. ). This flexibility is very useful for time to market constraints. It’s probably the most important advantage. It can bring a better reactivity and adaptability for any kind of application independently of the amount of data to be stored.
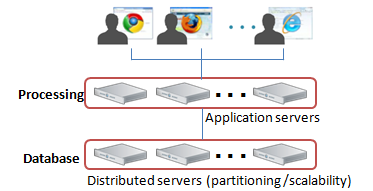
Scalability
A NoSQL databases provides “horizontal scalability” (scalability by adding machines into a pool of resources) thanks to the data partitioning.
The limits
The CAP theorem
The “CAP theorem” (also known as Brewer’s theorem) states that it is impossible for a distributed computer system to simultaneously provide all three of the following guarantees:
- Consistency (a read sees all previously completed writes)
- Availability (reads and writes always succeed)
- Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
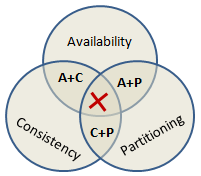
So a NoSQL database as a distributed system cannot satisfy all three of these guarantees at the same time. You cannot have the 3. You must choose only 2 of the 3.
- Classical relational databases : Availability + Consistency
- NoSQL databases : Availability + Partition tolerance OR Consistency + Partition tolerance
The lack of expertise
At the moment some NoSQL solutions are very simple and easy to use (for example “key-value” databases), but others are quite complicated and it can be difficult to find experts providing a good support.
What about the maturity ?
Some solutions are very stable, but others have some key features yet to be implemented and bugs to be fixed.
The “polyglot database” approach
Each database has its own advantages and drawbacks. You have the choice, so do the right choice! Consider only your context requirements and do not try to choose only one database to do everything…
Since few years the notion of “polyglot database” becomes to emerge. It’s a response to the following problems :
– Very often an application uses different kinds of data
– It integrates information from different sources
– A unique technology (like a relational database) is not sufficient for all the users expectations
So, why not choose the best of breed for each domain (even in a single application) ?
For example :
– User sessions stored in a “key-value” database (like Redis )
– Employees relationships stored in a “graph” database (like Neo4J)
– The product catalog stored in a “document” database for flexibility (like MongoDB)
– The analytics data stored in a “key-columns” database (like Cassandra)
– Financial data stored in a “classical relational” database (like Oracle)
Conclusion
Obviously relational databases aren’t dead and we’ll still continue to use them (very often as the core of the system) but the NoSQL databases will be indispensable to respond to the new users’ expectations.
The “polyglot database” approach is probably the future for many domains…
The main NoSQL databases
| Database name | Type | API protocole | Written in |
| Redis | Key-Value | Native/socket | C |
| Memcached | Key-Value | Native/socket | C |
| Riak | Key-Value | Prot.Buf, REST | Erlang/C/C++ |
| Cassandra | Column oriented | Thrift (or CQL) | Java |
| HBase | Column oriented | Prot.Buf, REST, Thrift | Java |
| BigTable | Column oriented | ||
| MongoDB | Document/JSON | Native/socket | C++ |
| CouchDB | Document/JSON | Erlang | |
| CouchBase | Document/JSON | Memcached Prot. | Erlang/C/C++ |
| Neo4J | Graph | Java | |
About the author